Профилактика для сохранения работоспособности почтовой системы
Администратору сервера Exchange каждый день приходится решать, какие выполнять задачи по обслуживанию системы. Профилактический контроль состояния серверов требуется осуществлять постоянно. Для того чтобы система с Exchange продолжала нормально работать, необходимо ежедневно выполнять семь проверок:
- Проверка событий резервного копирования.
- Проверка системных журналов событий.
- Проверка дисковой системы.
- Проверка обновлений антивирусных баз.
- Проверка очередей.
- Проверка квитанций о недоставке (NDR).
- Проверка оборудования.
Выполнение таких профилактических проверок превращается в бесконечный цикл и уже само по себе становится проблемой. Если система большая и сложная, необходимо использовать автоматизированный инструментарий для сбора информации по выполняемым проверкам. К работе таких средств мониторинга можно подключить и проверки вручную, так как некоторые необычные ситуации могут быть пропущены автоматическими средствами. Основная задача — не собрать результаты автоматических или ручных проверок, а правильно интерпретировать их.
1. Проверка событий резервного копирования
Проверка событий резервного копирования Exchange в журнале Application дает очень важную информацию. Во-первых, это позволяет убедиться, что резервное копирование было выполнено и система Exchange может быть восстановлена в случае сбоя. Во-вторых, администратор получает общую информацию о состоянии баз данных, из которых состоит хранилище Exchange.
Чтобы убедиться в пригодности резервной копии, проверять надо процедуры резервирования для каждой установленной системы Exchange. Обычно резервное копирование на файловом уровне выполняется, когда сохраняемые файлы не используются. В случае с системой Exchange файлы баз данных свободны только тогда, когда система остановлена. К счастью, Exchange предоставляет API, который позволяет программам резервного копирования работать в тандеме с модулем Extensible Storage Engine (ESE) и выполнять копирование, когда базы данных используются.
Во время резервного копирования ESE читает базы данных и передает информацию программе резервирования, которая, в свою очередь, сохраняет эту информацию на резервном носителе данных. Поскольку два компонента (т. е. ESE и программа резервирования) работают с данными во время резервирования, важно убедиться, что каждый компонент сохраняет данные без ошибок. Табл. 1 можно использовать для интерпретации системного журнала Application. Она включает события, связанные с работой ESE и NTBackup — штатной программы резервного копирования Windows 2000. ID событий от программы резервирования зависят от используемого программного обеспечения, а ID от ESE будут оставаться неизменными.
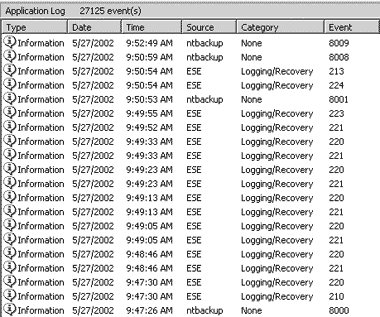
Интерпретировать события в системном журнале очень просто. Например, посмотрим на окно с журналом Application, показанное на экране 1. События с ID 8000 и 8001 показывают время начала и завершения резервного копирования со стороны NTBackup. События с ID 210 и 213 показывают время начала и завершения полного резервного копирования со стороны ESE. Другие виды резервирования, такие как инкрементальное и дифференциальное, будут отличаться соответствующими ID.
|
| Экран 1. Журнал приложений Exchange 2000 |
События NTBackup с ID 8008 и 8009 показывают начало и завершение процесса верификации. Во время процесса верификации NTBackup читает данные и соответствующие контрольные суммы с носителя резервной копии для подтверждения пригодности сохраненных данных. Если возникает аппаратная ошибка или сбой носителя, то NTBackup сообщает об ошибке. Поскольку процесс верификации завершается после сообщения ESE об успешном завершении резервного копирования, для уверенности в нормальном сохранении данных Exchange необходимо убедиться в отсутствии сообщений об ошибках от программного обеспечения, выполняющего резервное копирование. Поэтому только после сообщений об успешном завершении резервного копирования от всех источников можно считать, что получена работоспособная копия данных.
Проверка событий в журналах Application — хороший способ убедиться в успешности выполнения резервного копирования. Однако для абсолютной уверенности в том, что резервная копия годится для восстановления, необходимо проводить тестовое восстановление данных на специально выделенном сервере восстановления.
Проверяя сообщения о событиях резервного копирования, можно судить о состоянии баз данных. При выполнении полного резервного копирования ESE читает базы данных порциями, которые называются страницами. Каждая страница содержит контрольную сумму, взглянув на которую администратор может убедиться, что данные в странице не повреждены. API резервного копирования высчитывает новую контрольную сумму и сравнивает с хранящейся версией для выявления нарушений. Если ESE находит сбой, в журнал заносится сообщение об ошибке и резервное копирование прерывается. О таких сообщениях об ошибках рассказывается в статье Microsoft «XADM: Understanding and Analyzing -1018, -1019, and -1022 Exchange Database Errors» (http://support.microsoft.com/default.aspx?scid=kb;en-us;q314917). Важно как можно раньше обнаружить наличие данного типа ошибок. Если не заметить эту проблему и продолжить эксплуатировать Exchange, возникнет реальный риск не восстановить в случае сбоя базы и все транзакции, поскольку в резервной копии не будет полноценного набора необходимых данных.
2. Проверка системных журналов событий
Когда работающая система Exchange сталкивается с неопределенной ситуацией, в журнал событий записывается сообщение об ошибке, предупреждение или информационное сообщение. По крайней мере один раз в день надо просматривать системные журналы на каждом сервере Exchange и исследовать необычные сообщения. Чтобы упростить эту регулярно выполняемую задачу, необходимо определить для себя базовое состояние, относительно которого уже оценивать серьезность ситуации. Так, например, просматривая статистику производительности, следует учитывать допустимые отклонения от нормы и критические значения, приводящие к нарушениям в работе системы.
По умолчанию Exchange записывает большое количество данных в системные журналы. Определив базовое состояние, можно сэкономить время, поскольку уже будет известно, на какие именно сообщения следует обратить внимание. Одни информационные сообщения, такие как были описаны выше (о выполнении резервного копирования), критичны для регулярного контроля, другие — нет. Например, событие с ID 1221 сообщает об освобождении свободного пространства в хранилище. Когда пользователи удаляют свои сообщения из почтовых ящиков, Exchange не уменьшает размер хранилища почтовых ящиков, а вместо этого устанавливает флаг, означающий, что данные удалены. Такой тип информации поможет сэкономить дисковое пространство. В табл. 2 приведен список событий, на которые обычно можно не обращать внимания при ежедневном осмотре.
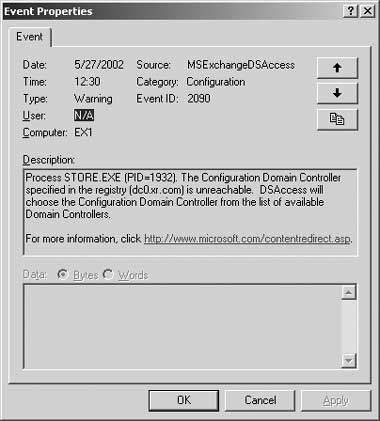
При определении базового состояния следует сосредоточиться на сообщениях об ошибках и предупреждениях. При изучении таких событий необходимо понять, что есть причина, а что следствие. Например, в журнале обнаружено событие с ID 2090, показанное на экране 2. Если разбираться с этим сообщением, то надо отыскать в свойствах сервера Exchange закладку Directory Access (она появилась в Exchange 2000 Service Pack 2) для определения ситуации с контроллером домена (DC) или сервером глобального каталога (GC), к которому необходим доступ, но в данный момент он недоступен. Из всех перечисленных DC и GC оставить надо только те, которые необходимо, так как сбой может быть следствием того, что Exchange и текущий сервер GC находятся на разных территориях и между ними — медленный канал связи.
|
| Экран 2. Событие, вызванное недосягаемостью контроллера домена |
Если в сети много серверов Exchange, просмотр системных журналов становится нелегкой задачей. Для ее решения можно задействовать автоматизированные средства мониторинга, такие как Microsoft Operations Manager (MOM), Aelita Software EventAdmin, NetIQ AppManager Suite (AppManager) или Hewlett-Packard HP OpenView. Эти продукты предоставляют механизмы, позволяющие фильтровать события, которые нет необходимости отслеживать. Кроме того, эти продукты предоставляют дополнительные возможности по уведомлениям в случае возникновения важных событий.
3. Проверка дисковой системы
Серверы Exchange могут останавливаться из-за недостаточного количества свободного места на диске, что является серьезной проблемой для многих администраторов. Обычно на серверах Exchange имеются отдельные диски для операционной системы, для журналов транзакций и для хранилища. На некоторых серверах также могут быть отдельные диски для других компонентов, таких как журналы отслеживания сообщений, очереди коннекторов SMTP, карантины для перехваченных антивирусным программным обеспечением файлов. Важно проверять свободное дисковое пространство на каждом диске каждый день, чтобы быть уверенным в том, что система не остановится из-за нехватки свободного места. Достаточное количество свободного пространства на дисках зависит от таких факторов, как объем передаваемой информации через почтовую систему в день и требования стандартных процедур Exchange по работе с журналами, файлами карантина и другими файлами. Для выполнения соответствующих проверок свободного дискового пространства необходимо следующее.
- Убедиться, что Exchange чистит журналы транзакций. Перед выполнением полного резервного копирования всех баз данных в рамках группы хранения (SG) можно увидеть журналы транзакций со времени последнего выполнения такого резервного копирования. Exchange чистит журналы транзакций только при успешном завершении резервирования всех баз данных в SG. Если вы увидите старые журналы, это означает, что Exchange не очищал их, и это косвенно говорит о том, что базы данных не были успешно скопированы.
- Проверить размер антивирусных карантинов и отчетов. Некоторые поставщики антивирусных программ заявляют, что производительность их продуктов может падать при большом увеличении файлов в зоне карантина. Это, вероятно, происходит потому, что программное обеспечение записывает файлы на диск последовательно и со временем их может скопиться очень много. Но эта проблема не является реально опасной в промышленной среде. В большинстве случаев отчеты и файлы карантина хранятся от 15 до 30 дней, в зависимости от организации и принятых в ней порядков. Такой период времени позволяет восстановить файл в случае ошибочного попадания в карантин.
- Проверить размер каталога журналов SMTP и очистить в случае необходимости. Несмотря на то что Exchange позволяет управлять файлами журналов, они все равно последовательно заполняются и старые журналы автоматически не удаляются. Нельзя позволять журналам накапливаться бесконтрольно, это может привести к сбою. Если каталог с журналами находится на системном диске по умолчанию, то Windows может дать сбой при заполнении всего дискового пространства. Если каталог с журналами находится на диске с каталогами виртуального сервера SMTP, то этот сервер SMTP может остановить обработку писем, пока не освободится дисковое пространство. Журналы имеет смысл хранить от 21 до 30 дней. В случае возникновения проблем этого срока вполне достаточно, чтобы разобраться в причинах.
- Удалить устаревшие архивные сообщения. Если используются возможности архивирования протокола SMTP, следует убедиться в том, что архивные сообщения удалены или перемещены в другой каталог, прежде чем заканчивается срок хранения сообщений для данного каталога, установленный исходя из здравого смысла. Компании архивируют сообщения по разным причинам - от выявления неполадок до контроля содержимого переписки. Но если не слишком активно заниматься управлением архивом сообщений и удалением лишнего, все доступное дисковое пространство будет быстро заполняться.
4. Проверка обновлений антивирусных баз
Когда в систему попадет очередной вирус, неизвестно. Лучшей защитой от вирусов является регулярное обновление баз установленного антивирусного программного обеспечения. Проверять наличие обновлений антивирусных баз необходимо не реже чем один раз в день. Обычно антивирусное программное обеспечение, обработав и установив новые базы, делает соответствующую запись в системный журнал Windows. Если антивирусная программа не вносит записи в журнал событий, то, возможно, она записывает информацию в собственный журнал. Например, Sybari Software Antigen записывает информацию об обновлениях в файл programlog.txt, а Trend Micro ScanMail for Microsoft Exchange записывает свои события в update.log. Проверяя журнал Windows или собственный журнал антивирусной программы, необходимо убедиться, что обновления баз были успешно получены и корректно установлены.
Можно считать это неинтеллектуальной задачей, но в некоторых случаях могут возникать серьезные проблемы. Например, одна компания отключила соединение с Internet, когда появился вирус Nimda. Поскольку антивирусное программное обеспечение не могло получить доступ к сайту разработчика для загрузки обновлений, администратор Exchange использовал коммутируемое соединение для загрузки обновлений и записи их на компакт-диск. Когда администратор скопировал обновления с компакт-диска на сервер, он оставил у файлов атрибут read-only. Позднее, когда компания восстановила соединение с Internet, процесс автоматического обновления завершился со сбоем, поскольку новые файлы антивирусных баз не могли перезаписать старые файлы.
5. Проверка очередей
Сервер Exchange, обрабатывая очень большой объем почтовых сообщений, может на некоторое время задерживать их в своих очередях. Наличие сообщений в очередях в течение длительного срока обычно указывает на ненормальную работу системы, о чем может сообщаться в системном журнале. Пиковый рост очередей может возникать при отправке сообщений по большим спискам рассылки (DL), при отправке очень больших сообщений нескольким получателям или когда сервер получателя подключен по медленному сетевому каналу. Такие ситуации не являются аварийными. Аварийной можно считать ситуацию, когда в очередях накапливаются тысячи сообщений для одних серверов получателей или когда появляется множество очередей для разных серверов и доменов. Наличие тысяч сообщений в очереди для одного получателя говорит о зацикливании при отправке почты или об атаке типа «отказ в обслуживании» (Denial of Service, DoS). Наличие множества очередей с сообщениями для разных серверов и доменов говорит о том, что на сервере произошел сбой, системная служба остановлена или сбои в сети не позволяют серверу установить соединение.
Для того чтобы оценить критичность ситуации, необходимо определить базовое состояние, по которому решать — нормальное положение или нет. Для табличного отображения очередей можно задействовать утилиту MailQ из Microsoft Exchange Server Resource Kit. Если по очередям будет видно наличие проблемы, исследовать ее причины можно с помощью Exchange System Manager (ESM).
6. Проверка квитанций о недоставке (NDR)
NDR приходят всегда. Основные причины появления NDR — неверное написание имени получателя или отказ сервера получателя принять сообщение. Серверы посылают NDR отправителю сообщения, но систему можно настроить так, чтобы копии отчетов шли в назначенный администратором почтовый ящик. Эта возможность настраивается в ESM в диалоговом окне свойств для каждого виртуального сервера SMTP. На закладке Messages следует ввести соответствующий адрес в формате SMTP в поле Send copy of non-delivery reports to. После внесения такого изменения в настройках надо остановить и снова запустить виртуальный сервер.
Пробовать определять и корректировать информацию для каждого NDR — это задача не на каждый день. Вместо этого достаточно будет сравнивать количество NDR с выбранным базовым состоянием. Для определения такого базового состояния надо выбрать среднее значение отправленных или принятых NDR в течение недели. Их количество может варьироваться. Например, в понедельник может приходить 25 NDR каждые 10 минут, а в пятницу — 25 NDR в час.
Резкий скачок в количестве NDR обычно говорит о проблеме, такой как атака DoS или зацикливание в отправке почты. Зацикливание в отправке почты может возникнуть, когда у пользователя настроено правило для пересылки на личный почтовый ящик у провайдера Internet. Пользователи могут настраивать такую конфигурацию, несмотря на то что корпоративная почтовая система может не иметь выхода в Internet. Теоретически такие настройки не являются серьезной ошибкой. Однако можно ошибиться в имени личного почтового ящика у провайдера, этот почтовый ящик может переполниться или возникнет другой сбой, и сервер провайдера услуг Internet будет отсылать NDR, а пользовательское правило будет успешно их пересылать обратно на тот же адрес, который в данный момент недоступен. В результате возникает цикл NDR.
7. Проверка оборудования
Одной из задач является регулярная проверка оборудования. Следует по крайней мере один раз в день заходить в компьютерную комнату и проверять каждый сервер. Например, надо проверять индикацию серверов, чтобы убедиться в отсутствии сбоев и проверять консоли, дабы убедиться, что нет сообщений от приложений.
Даже если для контроля серверов используются административные утилиты, все равно необходимы визуальные проверки на случай непредвиденных ситуаций. Например, некоторые приложения при серьезном сбое выдают предупреждение только на системную консоль. В такой ситуации система не может корректно завершить процесс, освободить файл или записать сообщение в системный журнал, пока не будет нажата кнопка OK в диалоговом окне. Кроме того, подобные проверки позволяют поддерживать антивирусные базы в актуальном состоянии. При сбое процесса обновления баз может появиться предупреждающее диалоговое окно. Если не проводить визуальных проверок серверных консолей, такое диалоговое окно будет оставаться на экране долго и последующие обновления антивирусных баз будут завершаться со сбоем, поскольку некоторые файлы могут быть заблокированы.
Базовое состояние
Какой тип событий сервер Exchange обычно записывает в системный журнал? Как много сообщений обычно находится в очереди? Сколько NDR отправляется и принимается каждый день? Важно знать ответы на такие вопросы. Если не принимать во внимание типичное состояние системы, сложно вовремя заметить критическую для сервера ситуацию. Помочь в данном случае могут ежедневные проверки и определение на их основе базовых состояний, а также профилактический контроль состояния системы Exchange.
Джозеф Ньбауэр - Старший технический консультант HP, специалист по Windows и Microsoft Exchange Server. joseph.neubauer@hp.com