Разработчики приложений и баз данных, вероятно, сталкивались с чрезвычайно длительным выполнением такими утилитами, как bcp (программа экспорта данных), служба передачи данных DTS и репликации данных, копирования большого количества данных в разнообразные источники. Например, передача снимка базы, которая содержит 500 Мбайт данных, с ограничениями по ключам и индексами, между двумя мощными четырехпроцессорными серверами с оперативной памятью объемом 1 Гбайт и дисковым массивом RAID 5 потребует 2 ч в рабочее время или 1,5 ч в ночное время. Подобная производительность неприемлема для серверов промышленного назначения с круглосуточной нагрузкой или распределенного хранилища данных предприятия, время состояния которого в непиковом режиме слишком мало, чтобы обеспечить перенос большого количества данных на все серверы. Итак, как можно ускорить процесс распределения необходимых данных?
Я остановлюсь на том, что требуется оптимизировать процесс копирования больших снимков данных. Репликация снимка данных копирует набор данных от исходного SQL Server при ее вызове репликации, даже если одновременно происходит выполнение других запросов и изменение тех же данных. Репликация снимка копирует этот набор данных сразу или позже на другой SQL Server. SQL Server, принимающий данные, видит их такими, какими они присутствовали на исходном сервере в момент копирования, пока следующая репликация не обновит полный набор данных. DTS копирует набор данных из источника ODBC (или OLE DB) в другой целевой ODBC-приемник немедленно. И источник, и приемник могут быть совершенно разными провайдерами данных ODBC. Bcp копирует одну таблицу или представление из SQL Server в файл собственного формата, символьный файл либо, наоборот, из файла в таблицу или представление SQL Server.
Репликация снимка на самом деле тоже использует bcp и участвует в двух этапах. На первом этапе (bcps out) снимки выбранных источников данных загружаются в назначенное время. На втором этапе (bcps in) снимок отправляется на один или несколько серверов по разным расписаниям. Хотя DTS также использует bcp, поддерживая задачу BULK INSERT, DTS не может выполнять копирование отдельно по заранее запланированному расписанию, и, кроме того, нельзя отправить одну копию снимка по разным приемникам. Задание DTS может копировать только в один назначенный приемник. Но bcp — утилита командной строки. Ей недостает пользовательского интерфейса и способности копировать напрямую с одного SQL Server на другой. Одним вызовом bcp может скопировать только одну таблицу. Репликация снимка и DTS удобнее для пользователя и функционально богаче по сравнению с утилитой bcp. Чтобы узнать, почему репликация снимка может оказаться предпочтительней, чем транзакционная репликация для конкретного проекта, прочтите врезку «Почему не транзакционное реплицирование?».
Как работает репликация снимка
Прежде чем начать процесс оптимизации, сначала кратко просмотрим основы репликации, которая происходит в две стадии. На первой стадии агент снимков Snapshot Agent копирует выбранные таблицы (называемые опубликованными статьями) из базы данных источника (издателя) в область распределения (распределитель) как набор файлов .bcp посредством запуска утилиты snapshot.exe. Заметим, что в SQL Server версии 2000 можно также определить статью, базирующуюся на представлениях, хранимых процедурах или пользовательских функциях (UDF).
На второй стадии агент распределения Distribution Agent копирует набор файлов .bcp в базу-источник (подписчик) с помощью утилиты distrib.exe. Утилиты snapshot.exe и distrib.exe используют bcp для того, чтобы копировать статьи по одной за раз, агент снимков копирует данные в файлы .bcp выполнением простого предложения SELECT, которое может содержать фильтр по столбцу и оператор WHERE (для фильтрации строк). Затем агент Snapshot Agent записывает результирующие наборы в файлы .bcp. Когда агент распределения копирует (вставляет) файлы .bcp в таблицы базы данных, ему приходится удалять существующие строки, а также протоколировать удаление и вставку и пересобирать индексы.
Перед началом второй стадии реплицирования данных необходимо создать для этого рабочую среду. Рассмотрим шаги, выполняемые по умолчанию для настройки репликации снимков данных.
Задание и настройка издателей и подписчиков. Можно без труда определить и сконфигурировать репликацию снимка, используя утилиту Enterprise Manager или системные процедуры. Обычно когда создается новая публикация, сначала выбираются статьи, которые нужно включить, затем устанавливаются свойства публикации и статей. На следующем шаге применяют утилиту Enterprise Manager для добавления подписчиков. За один раз оформляют подписку на все статьи от одного издателя. Или же можно задействовать хранимую процедуру sp_addsubscription для выбора только тех статей, на которые хочется подписаться, или выбрать все статьи сразу. Можно вызвать процедуру, используя в качестве названия статьи параметр @article, и запускать ее для каждой статьи отдельно или применить all для всех статей одновременно. Например, в окне анализатора запросов Query Analyzer в результате потребуется набрать
EXEC sp_addsubscription @publication = N?pubs?, @article = N?authors?, @subscriber = N?CGIS1?, @destination_db = N?pubs?, @sync_type = N?automatic?, @update_mode = N?read only?, @offloadagent = 0, @dts_package_location = N?distributor? GO
для того чтобы подписаться только на статьи определенного автора (здесь authors), подписчика CGIS1. Параметр @article = N?all? следует использовать, если необходимо подписаться на все статьи. Подписка может быть типа push или pull. Подписка push создается на издателе и применима в полностью интегрированной, объединенной и централизованно управляемой среде, такой, как сервер разработки (издатель), подсоединенный к производственной ферме серверов (подписчики). Агент распределения в этом случае запускается на сервере-распределителе. Любая подписка типа pull создается на подписчике и более всего подходит для слабо связанных, без установления соединения, более автономных связей, таких, как между переносным компьютером менеджера по продажам и сервером в офисе. В этом случае агент распределения запускается на подписчике. Методику оптимизации я опишу в этой статье как для подписки типа pull, так и для push.
Связывание снимков и Distribution Agents. После того как мы определили и сконфигурировали публикации и подписку, мастер Create Publicatioin Wizard из Enterprise Manager связывает Snapshot Agent с каждой публикацией. Далее по умолчанию мастер Create Push Subscription Wizard связывает только одного агента распределений Distribution Agent для распределения всех публикаций в какой-нибудь базе данных, на которую подписался подписчик. Например, подписчик может подписаться на обе публикации A или B от одного и того же издателя и базы публикаций. По умолчанию только один Distribution Agent предоставляет эти две публикации подписчику. Если агенты снимков данных публикаций запускаются в одно и то же время, нельзя распределить эти два снимка по разным расписаниям. Для того чтобы сделать расписание распределения более гибким для каждой из публикаций в большой репликационной среде, я предпочитаю связать одного агента с публикацией А и одного — с публикацией В. Для этого перейдем в окно свойств публикации, выберем закладку Options, затем параметр Use a Distribution Agent that is independent of other publications from this database («Использовать агента так, чтобы не зависеть от остальных публикаций в базе данных»), как показано на Экране 1.
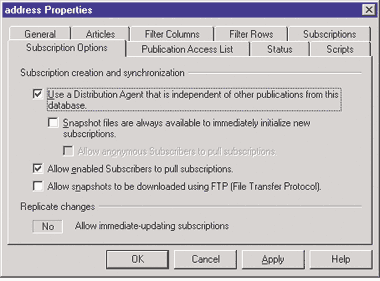
|
| Экран 1. Назначения разных агентов распределения разным публикациям. |
Связывание снимков и заданий агента распределения. Утилита Enterprise Manager автоматически определяет задание SQL Server для каждого Distribution Agent. Эти агенты выполняют репликацию, проходя по этапам заданий. По умолчанию задание агента состоит из трех этапов — Log agent startup message, Run agent и Detect nonlogged agent shutdown. На Экране 3 эти шаги показаны на закладке Steps в окне свойств CGIS1-EGH-address-28 Properties-CGIS1. На Экране 4 отображена команда, работающая на этапе Run agent, когда используется snapshot.exe.
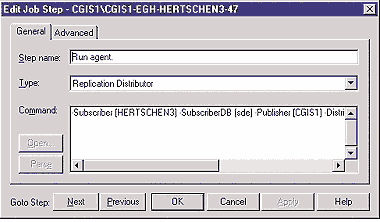
|
| Экран 4. Команда запуска Snapshot Agent. |
snapshot -Publisher [CGIS1] -PublisherDB [EGH] -Distributor [CGIS1] -Publication [address] -DistributorSecurityMode 1
Snapshot.exe копирует схемы, индексы и записи опубликованных статей от издателя к распределителю. Затем в папке Snapshot на распределителе сохраняется схема со статьями в файлах сценариев T-SQL с расширением .sch (как видно в кусочке кода на Рисунке 1), а индексы хранятся в файлах с расширением .idx files (см. Рисунок 2).
| Рисунок 2. Файлы сценария T-SQL (.idx) для определения индексов схемы. |
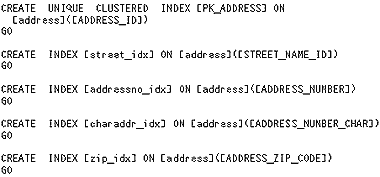
|
Также по умолчанию задание Distribution Agent выполняет те же три шага, что и Snapshot Agent. Однако на этапе Run agent выполняется distrib.exe, как видно из кода на Экране 5. Полный синтаксис этой команды таков:
distrib -Subscriber [HERTSCHEN3] -SubscriberDB [sde] -Publisher [CGIS1] -Distributor CGIS1 -DistributorSecurityMode 1 -PublisherDB [EGH]
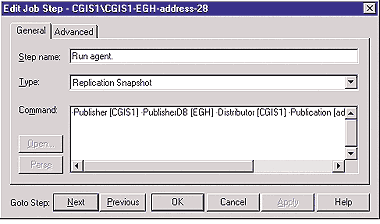
|
| Экран 5. Команда запуска Distribution Agent. |
Сначала исполняемый файл distrib.exe применяет схемы из файлов с расширением .sch к базе подписки (для удобства я назвал его шагом sch). На следующем шаге используются файлы .bcp, для того чтобы переписать данные из файлов с расширением .bcp в таблицы, которые были созданы на этапе sch (этап bcp). Наконец, применяются индексы из файлов с расширением .idx (этап idx).
Исполняемый файл Snapshot.exe генерирует набор файлов с расширениями .sch и .idx в соответствии со свойствами статьи, которые устанавливаются на закладке Snapshot диалогового окна свойств соответствующей статьи. Например, как показано на Экране 6,
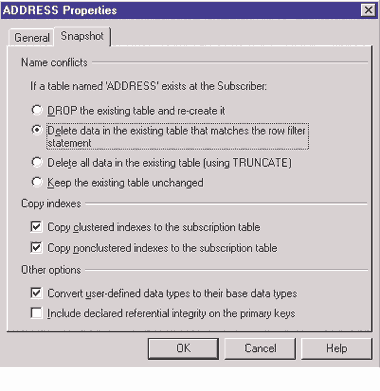
|
| Экран 6. Установка свойство статьи. |
| Рисунок 1. Файлы сценария T-SQL (.sch) для определения схемы статьи. |

|
sp_changearticle ?pubs?, ?authors?, ?schema_option?, ?0x01?, 1, 1 sp_addarticle @publication = N?pubs?, @article = N?authors?, @schema_option =0x0000000000000001, ...
Где ожидать помех
Агенты снимка и распределения выполняют свои задачи в соответствии с заданием, но пара таких задач может стать помехой в работе сервера баз данных, которая будет отрицательно сказываться на производительности. Давайте оценим производительность агентов, применяя стандартный набор критериев.
Введение критериев выполнения. Чтобы определить время исполнения приложения, можно или эмпирически оценить его выполнение, или математически оценить его алгоритм. В этом разделе я сделаю и эмпирическую, и математическую оценку шагов выполнения агентов, чтобы сравнить результаты, полученные разными методами. Для исследования требуемого количества времени математически считается, что время исполнения алгоритма увеличивается при увеличении количества данных на входе. Тенденция роста времени исполнения показывает, как алгоритм хорошо масштабируется с нагрузкой. Например, если время, затраченное на обработку данных размера n, растет в линейной зависимости от роста количества данных (например, обработка 1000 записей занимает 2 с, а обработка 10 тыс. записей занимает 20 с), то время выполнения алгоритма — линейно вместе с размером данных. Эта тенденция роста как функция от количества данных называется временной зависимостью алгоритма и обозначена как O(n) (или порядка n) для линейной зависимости от времени. Алгоритм, который всегда завершается за одно и то же время независимо от того, сколько данных предложено на вход, имеет постоянную величину зависимости от времени, которую я обозначил как O(c).
Теперь с помощью этих формул нам нужно оценить производительность агента снимков. Независимо от числа подписок, по которым следует копировать данные, утилита snapshot.exe выполняется только один раз для каждой из публикаций в назначенное время. Генерация сценариев .sch и.idx в этой команде занимает всегда одно и то же время по длительности, т. е. зависимость O(c) при любом количестве строк (обозначенное как n) в публикации. Время, которое требуется утилите snapshot.exe для того, чтобы создать файлы .bcp, тем не менее непосредственно пропорционально размеру публикации (зависимость от времени O(n)). Мое эмпирическое измерение на публикации в 500 Мбайт, в которой 6 млн строк, показало, что snapshot.exe потребовалось 7 с, чтобы создать файлы .sch и.idx, и требуется 2 мин и 38 с, чтобы произвести файлы .bcp. Эти результаты подтверждают, что скорость производства файлов .bcp зависит от размера публикации. По сравнению с командой агента распределения (distrib.exe), которую я оценивал потом, команда агента снимков (snapshot.exe) работает все еще очень быстро, даже в производстве больших файлов .bcp. На производительность выполнения этой команды ничто не влияет.
Поскольку агент снимков не замедляет процесс репликации снимка, виной всему должен быть агент распределения. Применение формул к шагам этого агента подскажет место возникновения помех.
Первый вариант помех: удаление целевых записей. Distrib.exe исполняется один раз для каждой из подписок. С точки зрения функциональности эта команда — полная противоположность snapshot.exe. Она применяет (в определенном порядке) все файлы .sch, .bcp и.idx публикации к целевой базе данных подписки. При этом команда создает служебные записи протоколирования всех предложений DELETE в шаге sch и индексирования всех таблиц в целевой базе в шаге idx. Предложение DELETE по умолчанию удаляют все записи в целевой таблице в шаге sch (предполагается отсутствие фильтра). Этот процесс имеет зависимость от времени O(n), где n — число записей в целевой таблице. Кроме того, каждое удаление записывает удаляемую запись в журнале транзакций и убирает соответствующую строку в кластерном и некластерном индексе B-деревьев. Согласно плану исполнения, который представлен на Рисунке 9, команда DELETE копирует каждую строку в tempdb (Table Spool) один раз для некластерного индекса и удаляет каждую строку из каждого индекса B-дерева. Всякое копирование или удаление в этом плане исполнения приводит приблизительно к 10 % от полных затрат на команду DELETE. Более того, для таблицы с m-индексами каждый индекс добавляет примерно 1/m от общих затрат. В целом зависимость от времени предложения DELETE на шаге sch будет следующей — O (m*n). В примере, который я представил ранее (используется четырехпроцессорный сервер разработки — с 1 Гбайт оперативной памяти и RAID 5 — для публикации 500 Мбайт данных, содержащих 6 млн записей), обычная задержка при удалении всех записей в целевых таблицах — 58 мин. Можно заметить, что удаление целевых записей порождает помеху, которая тем значительней, чем больше размер публикации и количество индексов.
Второй вариант помех: массированное копирование исходных данных. После того как шаг sch завершен, шаг bcp производит массированные вставки записей из файлов .bcp в индексированные целевые таблицы. Можно настроить выполнение агента распределения, регулируя параметры в его профиле (чтобы получить доступ к профилю, нужно щелкнуть на Agent-CGIS1:pubs в правой панели на Экране 2 и выбрать Agent Profile). Например, увеличивая значение параметра BcpBatchSize (количество переписываемых записей на один файл bcp), в профиле может уменьшить журналы истории распределения. Или можно настроить значение MaxBcpThreads (число потоков bcp на шаге bcp) на соответствие количеству процессоров на сервере распределений. Однако при выполнении своих тестов я не заметил, что действия с профилем улучшают исполнение и маштабируемость. Кроме того, утилите distrib.exe не хватает полезного параметра, имеющегося у утилиты bcp, — ключа ORDER. При вызове этого ключа bcp сортирует данные согласно кластерному индексу (или любому) целевой таблицы перед копированием данных в целевую таблицу. В действительности, данные реплицируются согласно кластерному индексу, и скопированные ранее записи потом уже никогда не заставляют SQL Server перестраивать кластерный индекс, упорядочивая более ранние записи. Следовательно, упорядоченная bcp однозначно быстрее, чем удаление кластерного индекса до и воссоздание его после применения неупорядоченной bcp.
Давайте математически оценим лучший вариант исполнения для шага bcp, принимая, что установлен ключ ORDER. Шаг bcp в этом сценарии по существу включает в себя вставку n отсортированных строчек (т. е. записей в соответствии с кластерным индексом) в каждую целевую таблицу и вставку каждой строки индексных столбцов этой таблицы в каждый из m индексов B-дерева (предполагая, что существует m индексов). Зависимость от времени будет подсчитываться так — O(m * n) + O(n * log(n)), где O(n * log(n)) — типичная зависимость от времени сортировки, O(m * n) — зависимость от времени вставки n записей и упорядочивания m индексов для каждой из n вставленных записей. Нужно иметь в виду, что это — зависимость от времени для лучшего варианта исполнения для шага bcp. Если рассматривать более ранний пример с 500 Мбайт данных, публикацией в 6 млн записей, выполняемой на четырехпроцессорном сервере разработок с памятью объемом 1 Гбайт и с RAID 5, шаг bcp потребует 55 мин, т. е. почти так же, как и шаг sch. Этот результат подтверждает сходство зависимостей шагов bcp и sch. Подобно шагу sch, шаг bcp создает помеху, которая растет с размером публикации и числа индексов.
Оптимизация скорости выполнения
Очевидно, что помехи, которые возникают, когда пользователи пытаются копировать большое количество данных, могут сделать репликацию крупномасштабных снимков бесполезной. Однако можно предпринять шаги, для того чтобы избежать этих проблем.
Избавление от помехи, вызванной оператором DELETE. Можно легко устранить помеху, которую оператор DELETE создает в шаге sch, выбирая параметр «Удалит, все данные в существующей таблице (использование TRUNCATE)» на закладке Snapshot, в диалоговом окне свойства статьи, изображенном на Экране 6. В результате мы получим команду TRUNCATE
вместо DELETE FROM
|
Преодоление помехи от bcp. К сожалению, нельзя ликвидировать помеху от bcp тем же методом, что и при настройке предложения TRUNCATE. Единственный способ оптимизировать шаг bcp состоит в том, чтобы удалить все индексы и ограничения по ключам перед шагом bcp и пересоздать их после шага bcp. Удаление и пересоздание индексов и ключевых ограничений уменьшают зависимость от времени bcp линейно, пропорционально размеру публикации — O(n), — потому что bcp больше не должен выполнять сортировку и индексацию. Эта оптимизация шага bcp приведет к независимости от числа индексов в публикации. Публикация в моем примере включает 10 кластеризованных индексов, 29 некластеризованных индексов и одно ограничение по внешнему ключу. Удаление всех индексов и ключей занимает 2 мин и 8 с; пересоздание всех индексов и ключей — 10 мин и 36 с, и завершение шага bcp занимает 28 мин — всего 41 мин в отличие от 55 мин. Эти испытания показывают, что результат оптимизации шага bcp впечатляет не так, как результат оптимизации шага sch из-за линейной зависимости от времени шага bcp. Преимущество по устранению помех на обоих шагах sch и bcp в приведенном примере — выигрыш в 72 мин.
Неудавшийся обходной маневр оптимизации. Чтобы осуществить оптимизацию для шагов sch и bcp, можно попробовать пойти обходным путем. Например, предположим, что установлен параметр @creation_script в хранимой процедуре sp_addarticle в каждом файле сценария, при добавлении каждой статьи для публикации. Такой файл сценария удалил бы все индексы и ключи в каждой целевой таблице. О создании сценария рассказано во врезке «Настраиваемый сценарий в SQL Server 2000». Нужно помнить, что агент распределения применяет шаги sch, bcp и idx последовательно. Цель состоит в том, чтобы заменить файл .sch сценарием при сохранении оригинальных сценариев .bcp и .idx. Задача выглядит легкой, потому что замена файла .sch не требует существенных затрат, кроме подготовки сценариев.
К сожалению, эта идея не работает по двум причинам. Во-первых, можно подумать, что следует использовать файл .idx, созданный агентом снимка, для того, чтобы пересоздать ограничения по внешним ключам и индексам, которые были удалены настраиваемым сценарием. Однако файл .idx не включает в себя ограничений по первичным и уникальным ключам, потому что в файле .idx агент снимка захватывает эти ключи как индексы. Например, на Рисунке 2 UNIQUE CLUSTERED INDEX [PK_ADDRESS] вызвано условием первичного ключа по имени [PK_ADDRESS], но продолжает существовать только как индекс. Во-вторых, хотя параметр @schema_option хранимой процедуры sp_addarticle позволяет отключить сценарий агента снимка и использовать параметр @creation_script, настройки параметра @creation_script также отключают генерацию файлов сценариев .sch и .idx. Поэтому ни один файл .idx не будет доступен для воссоздания индексов, удаленных файлом @creation_script. Установка параметра @creation_script в настраиваемом сценарии не позволяет достичь цели.
Настройка репликации снимка
Теперь рассмотрим концептуальные шаги для настройки — оптимизации — репликации снимка. Подробнее о выполнении этих шагов я расскажу во второй статье этой серии. Нужно помнить, что каждый агент распределения действует в пределах задания, как видно из Рисунка 3. Шаг задания Run agent — это команда, которая обращается к целой публикации; нельзя прерывать этот шаг между статьями, чтобы настроить его. Однако Enterprise Manager позволяет настраивать задание, вставляя новые шаги и модифицируя последовательность шагов. Можно вставить шаг — который я называю шаг drop — перед шагом Run agent, чтобы удалить все индексы и ключи, и вставить другой шаг, называемый receate, чтобы пересоздать все индексы и ключи. Поскольку эти шаги вставляются, подшаг bcp в пределах шага Run agent (который выполняет distrib.exe) никогда не видит индексы и ключи и, следовательно, линейно зависит от времени. Далее, поскольку вставленный шаг receate будет отвечать за пересоздание всех индексов и ключей, нет больше нужды в файле .idx. Так, на закладке Snapshot диалогового окна свойств статьи (см. Экран 6) следует очистить все параметры Copy indexes, чтобы очистить файл .idx, и выбрать параметр Delete all data in the existing table (using TRUNCATE), чтобы настроить файл .sch. Поскольку шаг drop удалил все ограничения по внешним ключам, подшаг sch в пределах шага Run agent может выполнить команду TRUNCATE успешно и, таким образом, он полностью оптимизирован с постоянной зависимостью от времени. Итак, оптимизированные шаги выполняются в следующем порядке: drop, sch (TRUNCATE), bcp, idx (пустой) и recreate. На Экране 7 показаны шаги настроенного задания агента распределения.
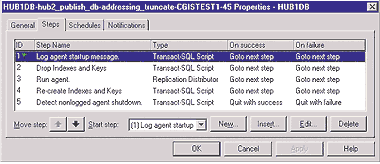
|
| Экран 7. Измененные шаги задания для Distribution Agent. |
Подстраиваем под свою среду
Единственное препятствие на пути к оптимизации состоит в том, что между шагами drop и recreate задания агента распределения шаг drop удалил все индексы и ключи всех целевых таблиц для одного подписчика. Удаленные индексы и ключи могут вызывать замедление исполнения одновременных запросов и нарушить ограничения по ключам в течение этого окна. Однако для большинства настроенных только на чтение хранилищ данных главное требование состоит в том, что синхронизация данных хранилища и данных представлений должна выполняться быстро в пределах ограниченных непиковых рабочих часов при минимальной поддержке параллельных запросов. Оптимизация приспособлена для таких условий очень хорошо.
| Рисунок 3. Примерный план исполнения для предложения DELETE. |
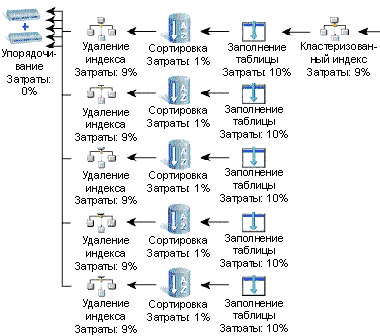
|
Почему не транзакционное реплицирование?
Возможно, у кого-то возник вопрос, почему я не рассматривал транзакционное реплицирование для распределения только изменений в большом снимке на целевые серверы. Давайте рассмотрим пример из реального мира, который проиллюстрирует причину моего выбора. Хотя при использовании транзакционного реплицирования можно копировать только изменения вместо целого снимка, что уменьшило бы размер данных очень сильно, транзакционное реплицирование неприменимо для многих ситуаций. Например, географическая информационная система (GIS), в которой я работаю, поддерживает приложение GIS, объединяющее данные о плане участка, его стоимости и целевом использовании. Однако городские службы эти данные не обслуживают. Вместо этого две отдельные группы в каждой из трех управ, налоговая и земельная (а также департамент строительства), поддерживают данные в различных форматах. Полный снимок данных плана участка приходит в формате Microstation?s CAD, и снимки данных оценки стоимости и целевого использования прибывают в текстовом формате с разделителями. Приложение GIS ожидает табличные данные от SQL Server, а не эти файлы, так что я должен импортировать файлы в базу данных, преобразовать данные из различных источников в единый набор схем и устранить дубликаты. Также из-за того, что импортированные файлы — это полные снимки вместо набора изменений, и преобразование — совсем не один в один, хранение последовательного набора изменений данных слишком затруднительно и не стоит потраченного времени. Загрузка, преобразование и объединение полных наборов внешних данных проще и эффективнее. Для предоставления такого полного набора импортированных данных нескольким узлам мы копируем полный снимок.
Настраиваемый сценарий в SQL Server 2000
Среди особенностей утилиты репликации снимков SQL Server 2000 — настраиваемый сценарий. Как же это работает? В закладке Snapshot диалогового окна с названием Publication Properties можно определить два sql-сценария. Исполняемый файл distrib.exe применяет оба сценария к подписавшейся базе данных. Distrib.exe выполняет первый сценарий перед другим новым сценарием, названным snapshot.pre, за которым следует шаг sch. Затем команда применяет второй сценарий сразу после шага bcp. По существу, новые сценарии делают то же самое, если вставлять шаги до и после шага Run Agent, который был описан в основной статье. Фактически из-за того, что новые сценарии — статические сценарии, а не параметризованные хранимые процедуры, их приходится переписывать всякий раз, когда конфигурация изменяется и когда сценарии обращаются только к одной публикации (предполагая, что каждая публикация работает со своим агентом распределения Distribution Agent). Для выполнения задач настройки я рекомендую использовать агента снимка, вместо предварительных сценариев и сценариев, выполняемых после, если только это не простые, статичные или постоянные сценарии.
Кроме того, если выбран режим Delete all data in the existing table (with TRUNCATE) («Удалять все присутствующие данные (Оператором TRUNCATE)») в диалоговом окне свойств статьи, новый сценарий удаляет ограничения по внешним ключам для целевой таблицы в базе подписки, выполняя новую хранимую процедуру sp_Msdropfkreferencingarticle в базе данных master. Нужно иметь в виду, что агент распределения не восстанавливает эти удаленные ключи к концу работы репликации снимка. Шаг recreate в моем случае восстанавливает все ограничения по ключам и индексы.
Хертс Чен — архитектор данных в группе Corporate GIS в Портланде, шт. Орегон. Отвечает за интеграцию и моделирование городских и региональных данных. С ним можно связаться по адресу: herts@ci.portland.or.us