Использование нового продукта предполагает несколько основных сценариев.
-
Распознавание документов каждым сотрудником офиса, когда без установки OCR-системы на его персональный компьютер они копируются в одну специальную папку, а из другой забирается результат. Возможен также другой вариант: сотрудник загружает бумажную копию документа в МФУ, а в его индивидуальной папке будет получен результат распознавания.
-
Создание архива документов в формате PDF (Image+Text), при этом сервер обеспечивает сохранение распознанных документов в формате PDF с возможностью дальнейшего поиска по тексту. Важно, что внешний вид документов и особенности оформления электронных копий остаются без изменений.
-
При потоковом вводе благодаря специальному режиму анализа ABBYY Recognition Server 2.0 позволяет распознавать весь текст документа, в том числе текст на картинках, в диаграммах, подписях и логотипах. Результат такой обработки индексируется в системе электронного документооборота или электронного архива, что позволяет включать документы в хранилище с возможностью полнотекстового поиска.
-
Наконец, данный сервер можно использовать как модуль в любой существующей или создаваемой системе ввода и обработки документов благодаря тому, что разработчики имеют возможность управлять всеми параметрами ABBYY Recognition Server посредством открытого интерфейса API.
Структура и функционал сервера
В структуре ABBYY Recognition Server 2.0 выделяются три основных компонента.
-
Менеджер сервера (Server Manager) служит для управления всеми запросами, настройками и сервисами и распределяет задания (Jobs) между станциями обработки (Processing Stations).
-
Станция обработки выполняет распознавание в соответствии с заданными настройками, получает задания от менеджера сервера, при этом количество станций не ограничено и они объединены в кластер.
-
Консоль управления, реализующая интерфейс администратора, которая построена на основе продукта Microsoft Management Console, позволяющего проводить мониторинг заданий и изменений в конфигурации ABBYY Recognition Server. Располагать консоль можно на любом компьютере в сети, по умолчанию совмещая с менеджером сервера.
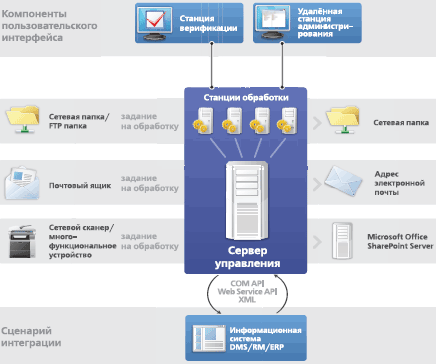
Доступ к серверу допустим через открытый интерфейс API, что поддерживает интеграцию в другие приложения, позволяет анализировать результаты на XML-языке и создавать на нем задания, а также обеспечивает внешнее управление конфигурацией ABBYY Recognition Server.
Сервер поддерживает четыре функциональных входа: из сетевой папки, содержащей PDF-файлы и изображения; со сканера; с МФУ; с FTP-ресурса.
На выходе ABBYY Recognition Server формирует содержимое папок исходящих документов. По первому входу — файлы в формате редактора MS Word. По второму и третьему — файлы форматов PDF, RTF и Excel. По четвертому — файлы форматов HTML и Power Point.
Возможности сервера
Качество распознавания сервера ABBYY Recognition Server 2.0 определяется тем, что он построен на ядре широко известного продукта ABBYY FineReader.
Реализовано распознавание печатных текстов на 191 языке, при этом для 37 основных языков мира — со словарной поддержкой и проверкой правописания. Для пяти европейских языков обрабатываются документы, напечатанные в XVII—XIX вв. Для 135 языков поддерживаются шрифты латинского, кириллического и греческого алфавитов. С помощью сервера можно распознавать тексты на четырех искусственных языках (эсперанто, интерлингва, идо, оксиденталь) и шести языках программирования (Basic, С/С++, Cobol, Фортран, Java и Паскаль), простые химические формулы и цифры, а также 15 наиболее распространенных штрихкодов (одномерные, например Check Code 39, Check Interleaved 25 и др., двумерные — PDF 417).
Кроме того, обрабатываются документы популярных форматов. Например, входящие документы могут быть представлены в виде графических файлов форматов: BMP (черно-белый, серый, цветной), TIFF (черно-белый, серый, цветной, многостраничный, сжатый и несжатый и др.), JPEG (серый, цветной), JPEG 2000 part1 (серый, цветной), PCX, DCX (черно-белый, серый, цветной), PNG (черно-белый, серый, цветной) или PDF, — которые находятся в папках в локальной сети или на FTP-сервере.
Результаты распознавания сохраняются в виде файлов в формате Adobe Acrobat (. PDF) — только тексты с картинками, только образы, тексты поверх изображения страницы и текст под изображением страницы с возможностью полнотекстового поиска, а также в форматах DOC, RTF, XML, HTML, PPT, CSV, TXT, XLS и DBF, который поддерживает кодовые страницы Windows, DOS, Mac и ISO.
ABBYY Recognition Server предоставляет возможность распределенной обработки задач на нескольких компьютерах на многопроцессорных и многоядерных аппаратных платформах, что, естественно, означает хорошую масштабируемость программного продукта.
Ведется детальная настройка всех этапов работы с документами, от поиска и открытия исходных изображений до сохранения результатов, распознавание изображений в соответствии с заданным расписанием или в порядке поступления заданий и с учетом приоритетов. Поддерживается получение документов от сетевых сканеров и МФУ. При задании уровня качества распознавания будет осуществляться его автоматический контроль.
Периодическая проверка состояния станций обработки и сервера, а при необходимости в случае сбоя — автоматический перезапуск оборудования обеспечивают высокий уровень отказоустойчивости.
Средствами XML-описания предусмотрена возможность управления параметрами работы ABBYY Recognition Server, в том числе из внешних приложений благодаря открытому интерфейсу API.
Интеграция и настройка сервера производится с помощью API и консоли управления Remote Administration Console.
Сопроводительная техническая документация продукта включает встроенную справочную систему в формате CHM, содержащую описание API и общие сведения о лицензировании продукта, примеры кода, демонстрирующие использование API для решения типовых задач, и руковод-
ство системного администратора, содержащее информацию об установке продукта, активации лицензии и собственно администрировании сервера.
Системные требования для возможности эксплуатации продукта задаются его компонентами и API: компьютеры многих производителей с процессорами с тактовой частотой не менее 500 МГц; ОС Microsoft Windows Server 2003, Windows XP/2000; оперативная память не менее 128 Мбайт; пространство на жестком диске для установки и работы не менее 115 Мбайт. Необходимо иметь права на чтение и запись для следующих разделов системного реестра: HKEY_CLASSES_ROOT, HKEY_LOCAL_MACHINESoftwareABBYY, HKEY_CURRENT_USERSoftwareABBYY.
Для станции обработки: аналогичный компьютер, но 230 Мбайт для рабочего пространства на жестком диске; оперативная память на 128 Мбайт и дополнительно по 100 Мбайт для каждого процесса распознавания.
Для консоли управления можно иметь менее производительный компьютер с процессором от 200 МГц и пространством на жестком диске 15 Мбайт. Столь же щадящие требования предъявляются к компьютеру с API, к тому же в этом случае можно использовать более «древние» ОС, например Windows Me/98.
Благодаря возможности выбора схемы лицензирования продукта покупатель ABBYY Recognition Server 2.0 может регулировать стоимость его приобретения. Она зависит от объема обрабатываемых документов и от набора дополнительных модулей или функциональности. Когда предполагается постоянная обработка больших объемов документов, во внимание принимаются количество обрабатываемых страниц
в месяц, общее количество страниц и число процессоров, одновременно выполняющих операции распознавания. В ином случае учитывается необходимость выполнения следующих операций: открытие и сохранение документов в формате PDF, экспорт в формате XML, распознавание печатного текста на китайском, корейском или японском языках, а также документов, напечатанных в XVII—XIX вв.
Полную версию статьи см. на "Мир-ПК диске"