Так, переход на многоядерные процессоры начался задолго до того, как к ним обратились две вышеупомянутые компании.
Раздвоение
Появление многоядерных ЦП можно отнести к началу новой эры «настольных вычислений». Почему же именно в начале XXI в. они стали столь необходимы? Старый способ повышения производительности путем увеличения тактовой частоты приводит к росту энергопотребления. Переход на все более тонкие технологии производства микросхем обостряет проблему утечки электрического тока (при сокращении размеров транзисторов ее вероятность возрастает). Поэтому довольно давно появилась необходимость в развитии методов, повышающих производительность процессора в результате увеличения количества инструкций программного кода, выполняемых за один такт. Для решения данной проблемы было предложено реализовать параллельное исполнение на уровне инструкций (ILP — Instruction Level Parallelism) или потоков (TLP — Thread Level Parallelism).
Распараллеливание на уровне потоков TLP в отличие от ILP управляется программно. Виртуальная многопоточность создается в результате выделения в одном физическом процессоре двух или более логических. Классическим примером такого подхода стала технология Hyper-Threading (НТ) компании Intel (см. «Мир ПК», №2/02, с. 10). Благодаря тому что в течение такта, как правило, не все исполнительные модули процессора задействованы, их можно загрузить параллельным потоком ресурсов. Понятно, вдвое производительность не увеличится, поскольку параллельные потоки используют общие память, кэш и т.д. да к тому же возникают потери из-за синхронизации и распараллеливания инструкций, но, по имеющимся данным, на 35—50% растет. Минусом TLP является возникновение конфликта, когда одному потоку требуются результаты выполнения другого, что приводит к росту количества тактов, необходимых для выполнения инструкций.
Очевидно, во избежание описанных выше проблем нужно изолировать в пределах одного процессора выполнение различных потоков инструкций. Причем каждый из них должен посылать команды на свое ядро, т.е. для реализации процесса параллельного выполнения задач следует интегрировать два ядра или более в одном ЦП. Помимо прочего такая многопроцессорная конфигурация на одном кристалле обеспечивает более высокую скорость обмена между ядрами, чем использование внешних шин, коммутаторов и т.п.
Первые
Компания IBM первой интегрировала в кристалл два процессорных ядра — в технологии Power4. При создании этой архитектуры она ориентировалась прежде всего на рынок высокопроизводительных серверов и суперкомпьютеров, поддерживающих 32-процессорные SMP-системы.
Микропроцессор Power4 создавался для работы как коммерческих (серверных), так и научно-технических приложений. Разработка Power велась на базе RISC-архитектуры (Reduced Instructions Set Computer), подразумевающей уменьшение количества инструкций. Наряду с этим предусматривается фиксирование длины команд, а также использование универсальных регистров. Команды упрощаются для того, чтобы они могли выполняться за один такт. Понятно, что реализация этого возможна только при оптимизации конвейера команд. В процессе создания Power разработчики решили минимизировать не время каждого цикла, а полное время, необходимое для выполнения конкретной задачи, для чего была внедрена технология суперскалярной обработки данных (см. врезку «Суперскалярные процессоры»).
Вернемся к Power4. Каждое из его ядер обладает собственным кэшем первого уровня для данных и инструкций (соответственно LD 1 и LI 1) и общим кэшем второго уровня (L2), управляемым тремя раздельными, автономно работающими контроллерами, которые подключаются к процессорным ядрам через коммутатор (Core Interface Unit, далее CIU). За такт контроллеры могут выдавать до 32 байт данных. Общий кэш для нескольких ядер хорошо сказывается на производительности процессора благодаря более быстрому доступу к совместно используемой информации, однако при таком способе организации велика вероятность возникновения конфликтов, многоступенчатая же организация кэша позволяет использовать его наиболее эффективно.
Очевидно, что скорость передачи данных между процессором и памятью существенно влияет на потенциал многоядерных устройств. Коммуникация каждого из Power4 с CIU осуществляется посредством двух раздельных 256-битовых шин для выборки инструкций и загрузки данных, а также отдельной 64-битовой шины для сохранения результатов.
Для поддержки когерентности в L2 применена расширенная версия известного протокола MESI (см. врезку «Протокол MESI») с длиной строки 128 байт, а в L3 использована модель с пятью состояниями когерентности (поддержка осуществляется на уровне 128-байтных секторов). Отдельный функциональный блок, так называемый контроллер матрицы, отвечает за обмен данными между контроллерами кэш-памяти второго и третьего уровней и за коммуникационные функции архитектуры Power4. В процессоре широко применяются механизмы прогнозирования ветвлений. Адресное пространство составляет 512 Гбайт.
Отметим, что протокол MESI применяет и AMD, точнее, доработанный MESI-MOESI. В нем процессоры могут использовать данные кэш-памяти друг друга, для чего во время чтения информации происходит проверка кэшей соседей и при обнаружении необходимых сведений считывание происходит прямо оттуда. Причем эти данные в оперативной памяти не сохраняются, а владелец информации делает пометку Owner напротив соответствующей строки. Свойства Owner-строк похожи на свойства Shared-строк, любое их изменение приводит к устареванию аналогичных строк в кэшах других процессоров, однако в случае вытеснения Owner-строк они записываются в оперативную память.
При разработке была поставлена задача оптимизации SMP-конфигурации, для того чтобы сервер на базе Power4 был готов к работе в многозадачных средах с высокими требованиями к пропускной способности. Четыре процессора могут быть упакованы в один модуль, образуя восьмипроцессорный SMP. Для соединения вместо центрального коммутатора используется множество независимых шин c топологией типа «точка—точка». Подробнее об архитектуре Power4 читайте на «Мир ПК-диске».
Следующий шаг
Архитектура следующего представителя этой линейки, процессора Power5, построена на принципах, примененных в Power4: два процессорных ядра на одном кристалле имеют раздельный кэш L1 для данных и инструкций и общий L2, выполненный в виде трех отдельных блоков, у каждого из которых есть свой контроллер. Ядра могут обращаться независимо друг от друга к любому из трех контроллеров.
Ряд важных нововведений начинается со с того, что хотя L3 и располагается вне кристалла, он напрямую связан с L2, что снижает задержки при работе с кэшем и улучшает масштабируемость — система на базе Power5 может включать до 64 процессорных конфигураций. В нем IBM впервые реализовала технологию микроразделов (Micro-Partitioning), позволившую представить каждый физический процессор как несколько (до 10) логических. Micro-Partitioning также предусматривает единую консоль для управления системами любых типов и широкий набор системных сервисов для управления рабочими нагрузками и перераспределения ресурсов, что дает возможность выполнить б?ольший объем работы.
С переходом на 130-нм технологию разработчики интегрировали в кристалл процессора Power5 не только два процессорных ядра, но и элементы управления памятью и заданиями, ранее реализовавшиеся на внешних элементах. Кстати, встроенный контроллер памяти используется и в технологиях, представленных AMD (поколение K8: Athlon 64 и Opteron). Недостаток такой системы — необходимость заменять процессор для перехода на системную плату с новым типом памяти.
Многопоточность в Power4 реализуется на аппаратном уровне: каждое из двух ядер выполняет свой поток команд, при задержке выполнения одного потока ресурсы обслуживающего его ядра нельзя передать другому потоку. В Power5 эта задача решена с помощью многопоточной технологии SMT.
В ней распределение приоритетов выполнения вычислительных потоков происходит на аппаратном уровне. Микропроцессор поддерживает восемь уровней приоритета (от седьмого, соответствующего наивысшему приоритету потока, до нулевого). Потоку с более высоким приоритетом предоставляется б?ольшая часть ресурсов. Когда приложению требуется использовать всю полосу пропускания обмена данными с памятью, то процессор автоматически переходит в однопоточный режим.
Очевидно, что применение SMT позволяет каждому ядру выполнять больше команд за такт, вследствие чего увеличивается и энергопотребление. Решение этой проблемы обеспечивают два механизма: при низком приоритете обоих потоков (0 или 1) включается встроенная технология энергосбережения; также возможно временное отключение тех компонентов процессора, которые не потребуются во время следующих тактов. В результате Power5 при прочих равных условиях выполняет на 50% больше инструкций, чем Power4, без какого-либо ущерба для производительности и при одинаковых затратах энергии.
Технология сверхплотной компоновки, особенность которой заключается в применении общей оперативной памяти и межузловых соединений с большой пропускной способностью, позволяет реализовать высокоскоростные соединения между восемью процессорами Power5. Четыре кристалла Power5 с четырьмя кристаллами L3 упаковываются в многокристальный модуль Multichip Module (MCM) размерами 95Ё95 мм. Так как Power5 нацелен на работу с системами хранения данных нового поколения, то поддерживается адресация хранилища данных емкостью до 96 Пбайт! Отметим также, что Power5 обратно совместим с Power4 на уровне программного обеспечения.
Прибавление
Следующим шагом для IBM стал Power5+, представляющий собой так называемый «сервер-на-кристалле». Он содержит два процессора, поддерживающих SMT-технологию, высокопроизводительный системный коммутатор, встроенную кэш-память объемом до 72 Мбайт, интерфейс ввода-вывода. Пиковая пропускная способность шины процессор—память составляет 42,6 Гбайт/с. Серверы, оснащенные микропроцессорами Power5+, сконструированы с учетом требований к вычислительным системам малого и среднего бизнеса, они учитывают ограниченность ресурсов, характерную для многих таких компаний. У них есть удобный программный инструментарий, и они обладают возможностью «внутреннего масштабирования» за счет реализации технологий виртуализации Micro-Partitioning. Использование логических разделов позволяет создавать ИT-системы уменьшенных размеров и повышенной производительности.
Технология Power была положена и в основу процессоров PowerPC. Последний продукт этой серии, PowerPC 970MP, представляет собой первую двухъядерную 64-битовую версию PowerPC, созданную на базе архитектуры Power4 с использованием 90-нм технологии. Между 64- и 32-битовыми конфигурациями возможно динамическое переключение. Эффективность работы поддерживается механизмом SMP-оптимизации. Каждое ядро в PowerPC 970MP обладает собственным кэшем L2, а также независимым термодиодом и шиной питания. По сравнению с предыдущими модификациями у него увеличена пропускная способность процессорной шины и размер кэша L2. Раздельный кэш L2 позволяет отключать или переводить в спящий режим одно из ядер. За такт может быть выполнено до восьми инструкций. Для сравнения: процессоры AMD на базе архитектуры к8 выполняют не больше шести. Тактовые частоты ядер регулируются синхронно.
Серьезные игры
Архитектура PowerPC привычно отметилась и в ПК Apple (как 6,5), но там в итоге все же уступила место х86-процессорам. Зато она отыгралась на игровых приставках: в Xbox 360 вместо процессора Intel, установленного в первой Xbox, применяется кристалл на базе PowerPC, который IBM назвала «компьютер-на-кристалле» (SoС, System-on-Chip). На одной подложке интегрированы три идентичных ядра, объединенных диспетчерской шиной XBAR, причем каждое из них способно выполнять по два независимых потока команд. Этот процессор, созданный специально для игровых и мультимедийных приложений, эффективен и для обработки больших объемов потоковых данных. В ЦП также реализована возможность обхода кэша L2 с пересылкой до восьми пакетов данных предварительной выборки непосредственно в кэш L1 каждого из трех ядер процессора. При этом части кэша L2 могут быть распределены в качестве буферов для потоковых данных. Xbox 360 стала первой приставкой с процессором седьмого поколения, появившейся на рынке.
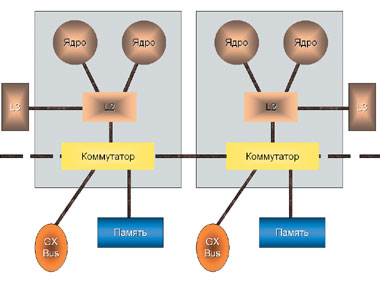
|
| Схема процессора Power5+ |
На базе архитектуры Power в рамках трехстороннего партнерского соглашения между IBM, Sony и Toshiba Corporation был создан и процессорный элемент Cell, представляющий собой «суперкомпьютер-на-кристалле». Его архитектура включает восемь взаимодополняющих вычислительных элементов SPE (Synergistic Processor Element) и ядро на базе Power. Все эти компоненты соединены между собой скоростной шиной EIB. Встроенный двухканальный контроллер памяти способен работать с памятью XDR незабываемой компании Rambus (максимальный объем 256 Мбайт). Связь с остальными компонентами производится посредством системной шины FlexIO (кодовое название Redwood) с пиковой тактовой частотой 6,4 ГГц, при этом FlexIO может связывать с данным элементом и другие процессоры Cell.
Специализированные микрокомпьютеры SPE рассчитаны на работу на тактовых частотах свыше 4 ГГц, выполнение массовой обработки данных с плавающей запятой и поддержку нескольких ОС одновременно. Напомним, что процессоры х86 пока не покорили эту планку. Отдельно взятый вычислительный элемент Cell имеет теоретическую мощность 250 GFLOPS (миллиарды операций с плавающей запятой в секунду). Кроме того, процессор оптимизирован для выполнения широкополосных медиаприложений (например, игры, развлекательные программы, видео и другие ресурсоемкие формы цифрового контента) и обладает встроенной технологией управления энергопотреблением. Сначала было объявлено о применении Cell в игровой приставке Sony PlayStation 3, однако сейчас стали доступны и серверы на его базе, так как он хорошо справляется с серьезными вычислительными задачами.
Конечно, наше внимание к IBM вполне понятно — она первой запустила двухъядерные процессоры, однако следует рассказать и про ее конкурентов, о которых читайте в следующем номере.
Продолжение следует.
Полный вариант статьи см. на «Мир ПК-диске».
На пути к многоядерности
Предшественниками многоядерных процессоров были многопроцессорные системы. По общепринятой классификации существует три способа соединений процессоров.
SMP (Symmetric Multiprocessing) — симметричные многопроцессорные системы, в которых ЦП имеют одинаковые права для доступа ко всем системным ресурсам и управлению ими. Задачи между процессорами распределяет операционная система. Оперативная память для них является разделяемым ресурсом.
NUMA (Non-Uniform Memory Access) — системы, организующие процессоры в блоки (по четыре) с общей памятью. Для обращения к памяти соседнего блока используется коммутатор.
Кластеры — несколько процессоров (начинка отдельного ПК или сервера), связанных с помощью широкополосных коммутаций. Основная область применения кластеров — суперкомпьютеры, нацеленные на быстрые вычисления.
Суперскалярные процессоры
Они используются как в современных RISC-, так и в х86-архитектурах. Суть их заключается в следующем: несколько функциональных устройств, параллельно работающих в процессоре, исполняют по мере возможности инструкции, находящиеся в специальном буфере, куда они поступили после декодирования. Распараллеливание происходит на уровне команд, совмещая выполнение двух или более арифметических операций, благодаря чему исчезает необходимость применять специальные алгоритмы, использующиеся при разработке программ для машин с несколькими процессорами. Чтобы эффективно применять такую архитектуру, кэш первого уровня должен обладать высокими пропускной способностью и емкостью.
Протокол MESI
MESI — протокол поддержания когерентности кэшей. Вся информация делится на частную, данные которой содержатся только в кэше одного процессора (Exclusive), и общую, находящуюся в кэше нескольких процессоров (Shared). Если изменяется Exclusive-строка, данные которой не записаны в оперативную память, то она помечается как Modified. При попытке обращения к такой строке со стороны других процессоров операция прерывается на то время, в течение которого строка записывается в оперативную память, а затем пометка Modified снимается и чтение возобновляется. Когда вносятся изменения в Shared-строку, то передается сигнал о проверке кэшей процессоров, в случае же возникновения ошибок напротив такой строки ставится пометка Invalid. Данные из Exclusive-, Invalid- и Shared-строк в оперативную память не заносятся.
Виртуализация от IBM
Micro-Partitioning входит в состав технологии виртуализации IBM — Virtualization Engine, позволяющей использовать несколько копий операционных систем на одном сервере, что сокращает число необходимых серверов и уменьшает расходы на программные лицензии.
Многопоточность
SMT (Simultaneous Multi-threading) обеспечивает эффективную загрузку функциональных устройств и оптимизирует доступ к памяти. Эта динамичная технология позволяет системе в случае возникновения длительной задержки при выполнении команды одного потока все ее исполнительные блоки временно передать другому, т.е. вместо последовательного выполнения команд из двух потоков данная технология реализует их параллельную обработку. Она аналогична Hyper-Threading, примененной ранее Intel в Xeon и Pentium 4.