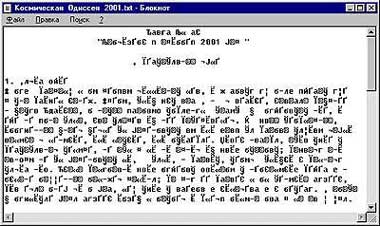
 |
| Так выглядит в Windows текст, созданный в программах для DOS |
В чем же тут дело? Что такое «кодировки», почему их так много и все они такие разные? И наконец, каким образом можно решить эту проблему? Не запускать же каждый раз Norton Editor, чтобы прочитать и напечатать свои старые файлы?
Кодовая страница
Применительно к ПК для записи текстовой информации используется кодирование символов последовательностями из восьми бит — одного байта. Иными словами, чтобы сформировать букву, цифру или какой-нибудь сложный символ, нужна последовательность из восьми нулей и единиц.
Когда программа получает с жесткого диска, компакт-диска или из Internet данные, содержащие текст, то она выделяет из получаемого массива информации последовательности по восемь бит, которые соответствуют конкретному символу и определяются программой из так называемой «таблицы символов», или «кодовой страницы». Затем уже используется именно этот символ.
Естественно, таблица символов должна соответствовать жесткому стандарту. Для английского алфавита (латиницы) во всех существующих таблицах символов каждая латинская буква кодируется лишь одной строго определенной последовательностью бит. Такое соответствие было разработано около двадцати лет назад на основе порядка букв в латинском алфавите.
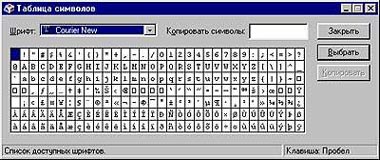 |
| Программа «Таблица символов» |
Каждая последовательность восьми бит имеет свое числовое значение, и это число из двоичной системы счисления легко перевести в десятичную. Например, 01010101 в десятичной системе счисления означает 85 и соответствует символу U, а в данном случае число 85 — код символа U. Таблицу символов можно вывести на экран. В Windows для этого есть программа «Таблица символов», где символы расставлены по степени возрастания их кодов.
С помощью восьми бит можно закодировать до 256 символов, из них по 26 английских строчных и прописных букв, а цифры, знаки препинания и служебные символы займут еще около 50 мест. Поэтому, чтобы облегчить адаптацию ОС к другим алфавитам, было принято строгое соответствие отображаемым символам лишь 127 последовательностей восьми бит, находящихся в первой половине кодовой страницы. Вторую же отдали «на откуп» производителям ПО и информационных ресурсов для размещения национальных алфавитов.
Тогда же появилась кодировка ASCII, где коды первых 127 символов могут кодироваться всего семью битами информации. Первые 32 кода (от 0 до 31) были предоставлены управляющим символам (например, 13 — символ конца абзаца), остальные — строчным и прописным латинским буквам, цифрам, знакам препинания и знакам математических операций. Коды второй половины 256-символьной страницы были отведены для национальных алфавитов, а также символов псевдографики, математических и прочих. Начальный бит кода символа второй половины имел значение «1», а в первой — «0». Любой символ можно легко отобразить на экране, набрав, например, в Word его код (десятичный на цифровой клавиатуре, с нулем в начале) при нажатой клавише
Таким образом, появились всевозможные версии кодовых страниц, различающиеся второй половиной, которым были присвоены определенные номера. Чтобы незаполненные участки исходной английской кодовой страницы «не пропадали», на места, соответствующие кодам символов, превышающих 127, были поставлены символы псевдографики, а также гласные буквы английского алфавита с надстрочными знаками, которые используются для обозначения определенным образом произносящихся букв в некоторых европейских языках, например во французском. Программы, создаваемые в неанглоязычных странах, рассчитаны на работу с национальными кодовыми страницами, и при получении кода символа, большего 127, они отображают свой конкретный символ. Код этого символа передается в программу с помощью драйвера клавиатуры при включении ее соответствующей раскладки. И тогда при нажатии клавиши с символом драйвер передает в программу код, соответствующий этому символу в национальной кодовой странице.
Российская особенность
Большинству стран, как правило, для национального алфавита хватает одной кодовой страницы, однако Россия и здесь имеет свои особенности.
Первые версии поставляемых в Россию англоязычных программ не могли работать с русским алфавитом (в них не было русской кодовой страницы), поэтому была создана русская кодовая страница ISO-8859-5, в которой кодам символов, большим 127, соответствовали русские буквы. Так как последних всего 33, а с заглавными — 66, то осталось место и для символов псевдографики. Чтобы с этой кодовой страницей можно было работать, требовалось либо написать программы, позволяющие отображать символы в соответствии с ней, либо создать ОС, которая сама сможет обеспечивать ввод-вывод текста, либо разработать специальную программу для работы вместе с ОС и обработки ввода-вывода информации в соответствии с нужной кодовой страницей. В настоящее время повсеместно применяются локализованные ОС, в которых не только имеются функции, обеспечивающие работу с русской кодовой страницей, но и переведен на русский язык интерфейс.
Наряду с ISO-8859-5 была разработана и альтернативная русская кодовая страница. Она отличалась порядком следования русских букв до строчной «р», а также тем, что символы псевдографики кодировались теми же кодами, что и в исходной английской таблице символов. При установке в ОС этой кодовой страницы можно было использовать нелокализованные версии западных программ, работающих с псевдографикой. Несмотря на то что в альтернативной кодовой странице русские символы шли не подряд, а с разрывом между строчными буквами «п» и «р», именно она стала наиболее распространенной. Кодовая страница ISO-8859-5 применялась при русификации поставлявшихся в Россию компьютерных систем Sun.
Заслуга внедрения русских кодовых страниц принадлежит российской компании «Диалог». В 1989 г. эта фирма, партнер Microsoft, первой локализовала ОС MS-DOS 4.1. При этом в качестве основной кодовой страницы была взята альтернативная кодировка под названием Dos(866), где корректно отображались символы псевдографики. Она получила широкое распространение и стала основной ОС для ПК.
При разработке локализованной версии ОС Windows компания Microsoft решила изменить Dos(866), поскольку с появлением графического интерфейса отпала необходимость в символах псевдографики. Это позволило принять последовательный порядок символов русского алфавита в кодовой странице, а также разместить там различные специальные символы, например изображение торговой марки. Так появилась кодировка Windows-1251. В ней порядок следования русских букв по сравнению с Dos(866) изменился, и поэтому для чтения Windows русского текста, набранного в DOS, потребовались программы-перекодировщики.
Продолжение в следующем номере.
Орлов Антон Александрович,
antorlov@mail.ru, http://antorlov.chat.ru