Нелегкая выпала доля тем, кто связал свою жизнь с программированием на языке Cи++. На мой взгляд, для изготовления Cи++ был изуродован прекраснейший язык Cи. Мало того, Cи++ мутирует чуть ли не каждый квартал, постепенно превращаясь в игрушку-трансформер, а сам автор Си++ вынужден выпускать одну книжку за другой для толкования своего детища. С внедрением языка Си++ в коммерческую разработку резко упала надежность программного обеспечения, что пользователи прочувствовали на своей шкуре. Чрезмерная избыточность языка Cи++ привела к тому, что один и тот же алгоритм каждый программист кодирует по-своему и, в соответствии с законами Мерфи и Питерса, не самым оптимальным способом. А надо сказать, что Си++ - просто бескрайнее море перегруженных операторов. Однако нашлись люди, предложившие некую надстройку над Си++, существенно упростившую работу с этим языком и сделавшую ее довольно комфортной. Среди них выделяется фигура нашего соотечественника г-на Степанова, перебравшегося в Америку и создавшего библиотеку Standard Template Library (STL). Теперь это чудо программистской мысли стало частью чернового стандарта языка Си++.
Решение производителей компиляторов заставило нас обратить внимание на новую версию этой библиотеки - STL 2.0. В нашей стране поклонники языка Cи++ смогут получить STL 2.0 в составе либо Borland C++ Builder 3, либо пакета библиотеки классов известного производителя - компании Roue Wave.
Одним из фундаментальных компонентов STL являются итераторы. Итераторы - удобная обертка для указателей, а выполнены они как шаблоны классов. Кстати говоря, обычный указатель тоже можно считать итератором, правда, очень примитивным. Итераторы обладают массой достоинств, например таких, как автоматическое отслеживание размера типа, на который указывает итератор, или автоматизированные операции инкремента и декремента для перехода от элемента к элементу. Именно благодаря этим возможностям итераторы и являются фундаментом всей библиотеки.
Итераторы можно условно разделить на две категории: основные и вспомогательные. Но прежде чем перейти к подробному описанию и тех и других, остановимся на двух важных правилах работы с итераторами: получения итераторов и отслеживания значения "за пределом". Многие функции и методы классов STL возвращают итераторы, вместо того чтобы производить действия над обычными указателями Си++. Классы STL, хранящие информацию, возвратят итератор, указывающий на первый элемент данных, если вызвать их метод begin(). Напротив, вызов метода end() приводит к возврату значения "за пределом" (past-the-end). Так называется значение итератора, при котором он указывает на элемент, следующий за последним разрешенным для ссылки элементом. Начиная со значения "за пределом" находится область данных, из которой нельзя читать и куда нельзя записывать. Нарушение этого запрета приведет к непредсказуемому результату. Представьте себе массив, например, из 10 элементов. Если итератор ссылается на некий одиннадцатый элемент, то говорят, что он ссылается на значение "за пределом". Разумеется, попытка записать в несуществующий элемент данные или оперировать данными этого элемента, как достоверными, приведет к неопределенному результату. Если бы вы попытались проделать такую операцию с блоком памяти в среде Windows, то немедленно получили бы исключение выхода за предел, что, скорее всего, окончилось бы аварийным завершением программы. Вот и судите сами, насколько важно следить за значением "за пределом".
Основные итераторы
Основные итераторы используются наиболее часто. И вы будете сталкиваться с ними постоянно. Поэтому с их рассмотрения мы и начнем.
Основные итераторы взаимозаменяемы. Однако при этом нужно соблюдать иерархию старшинства (рис. 1).
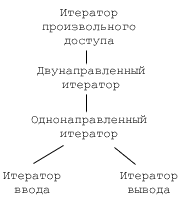
Итераторы ввода
Итераторы ввода (input iterator) стоят в самом низу иерархии итераторов. Это наиболее простые из всех итераторов STL, и доступны они только для чтения. Итератор ввода может быть сравнен с другими итераторами на предмет равенства или неравенства, чтобы узнать, не указывают ли два разных итератора на один и тот же объект. Вы можете использовать оператор разыменовывания (*) для прочтения содержимого объекта, на который итератор указывает. Перемещаться от первого элемента, на который указывает итератор ввода, к следующему элементу можно с помощью оператора инкремента (++). Итераторы ввода возвращает только шаблонный класс istream_iterator. Однако, несмотря на то что итераторы ввода возвращаются единственным классом, ссылки на него присутствуют повсеместно. Это связано с тем, что вместо итератора ввода может подставляться любой из основных итераторов, за исключением итератора вывода, назначение которого прямо противоположно итератору ввода.
Проиллюстрируем это на примере алгоритма for_each. Если вы использовали ранее библиотеку контейнеров Borland BIDS, то операция for_each вам уже знакома. В STL она реализована следующим алгоритмом:
templateFunction for_each (InputIterator first, InputIterator last, Function f) { while (first != last) f(*first++); return f; }
В этом примере итератор ввода выступает как первый параметр, указывающий на начало цепочки объектов, а второй параметр - также итератор ввода - это значение "за пределом" для этой цепочки. Тело алгоритма выполняет переход от объекта к объекту, вызывая для каждого значения, на которое указывает итератор ввода first, функцию. Указатель на нее передается в третьем параметре. Здесь задействованы все три перегруженных оператора, допустимые для итераторов ввода: сравнения (!=), инкремента (++) и разыменовывания (*). Так что лучше примера и не найти. В качестве первого и второго аргументов алгоритма сгодятся даже обычные указатели, о чем уже было сказано. Проиллюстрируем это. Пусть у нас имеется массив чисел, которые нужно распечатать. Тогда программа печати с использованием for_each может выглядеть так:
#include#include #pragma warning (disable: 4550) using namespace std; void printValue(int num) { cout << num << " "; } main(void) { int init[] = {1, 2, 3, 4, 5}; for_each(init, init + 5, printValue); }
Программа чрезвычайно проста. Есть массив init с пятью числами. Вызывается алгоритм for_each, ему в качестве входных итераторов передаются указатели на начало массива и на адрес, следующий за концом массива, т. е. на значение "за пределами". Третьим параметром является указатель на функцию printValue, которая печатает элементы массива. Чтобы включить в программу возможность использования потоков, добавляется включаемый файл iostream, а для описания прототипа алгоритма for_each в программу включается заголовочный файл algorithm (algorith для продуктов Borland). Обязательным при использовании STL является использование директивы:
using namespace std,
включающей пространство имен библиотеки STL. Поскольку пример изготовлен в среде компилятора Microsoft Visual C++ 5.0, была добавлена следующая директива:
#pragma warning (disable: 4550)
Она отключает назойливое предупреждение об отсутствии параметров, что, впрочем, ни на скорость (ни на зарплату!), конечно, не влияет, так что эту строку вполне можно опустить.
Итераторы вывода
Если итератор ввода предназначен для чтения данных, то итератор вывода (output iterator) служит для ссылки на область памяти, куда выводятся данные. Итераторы вывода можно встретить повсюду, где происходит хоть какая-то обработка информации средствами STL. Это могут быть алгоритмы (aлгоритмы STL - специальные блоки кода, выполняющие определенные операции по обработке данных) копирования, склейки и т. п. Для данного итератора определены операторы присвоения (=), разыменовывания (*) и инкремента (++). Однако следует помнить, что первые два оператора предполагают, что итератор вывода располагается в левой части выражений, т. е. во время присвоения он должен быть целевым итератором, которому присваиваются значения. Разыменовывание нужно делать лишь для того, чтобы присвоить некое значение объекту, на который итератор ссылается. Итераторы ввода могут быть возвращены итераторами потоков вывода (ostream_iterator) и итераторами вставки inserter, front_inserter и back_inserter (описаны в разделе "Итераторы вставки").
Ниже приведен типичный пример использования итераторов вывода:
#include#include #include using namespace std; main(void) { int init1[] = {1, 2, 3, 4, 5}; int init2[] = {6, 7, 8, 9, 10}; vector v(10); merge(init1, init1 + 5, init2, init2 + 5, v.begin()); copy(v.begin(), v.end(), ostream_iterator (cout, " ")); }
В отличие от предыдущего примера, здесь, помимо потоков и алгоритмов, использован контейнер (kонтейнеры STL - структуры данных для хранения информации определенным способом) типа "вектор", т. е. одномерный массив. У него имеются специальные методы begin() и end(), задача которых - возвращать итератор, указывающий на начало вектора и значение "за пределом" соответственно. В приведенном нами примере создаются и инициализируются два массива - init1 и init2. Далее их значения соединяются вместе алгоритмом merge и записываются в вектор. А для проверки полученного результата мы пересылаем данные из вектора в поток вывода, для чего вызываем алгоритм копирования copy и специальный итератор потока вывода ostream_iterator. Он перешлет данные в поток cout, разделив каждое пересылаемое значение символом окончания строки. Для шаблонного класса ostream_iterator требуется указать тип выводимых значений. В нашем случае это int.
С этим примером вы можете проделать эксперимент, чтобы узнать, к чему приводит обращение к значению по адресу "за пределом". Для этого достаточно сделать вектор размером не 10, а 9 элементов:
vectorv(9);
Однонаправленные итераторы
Если соединить итераторы ввода и вывода, то получится однонаправленный итератор (forward iterator), который может перемещаться по цепочке объектов в одном направлении, за что и получил такое название. Для такого перемещения в итераторе определена операция инкремента (++). И разумеется, в однонаправленном итераторе есть операторы сравнения (== и !=), присвоения (=) и разыменовывания (*). Все эти операторы можно увидеть, если посмотреть, как реализован, например, алгоритм replace, заменяющий одно определенное значение на другое:
templatevoid replace (ForwardIterator first, ForwardIterator last, const T& old_value, const T& new_value) { while (first != last) { if (*first == old_value) *first = new_value; ++first; } }
Чтобы убедиться в правильности работы всех операторов однонаправленных итераторов, составим программу, заменяющую в исходном массиве все единицы на нули и наоборот, т. е. произведем инверсию. С этой целью все нули изначально заменяются на некоторое нейтральное значение, например на двойку, затем все единицы обнуляются, а все двойки становятся единицами:
#include#include using namespace std; main(void) { replace(init, init + 5, 0, 2); replace(init, init + 5, 1, 0); replace(init, init + 5, 2, 1); copy(init, init + 5, ostream_iterator (cout, " ")); }
Как видите, алгоритм replace, умело используя однонаправленные итераторы, читает значения, заменяет их и перемещается от одного к другому.
Двунаправленные итераторы
Двунаправленный итератор (bidirectional iterator) аналогичен однонаправленному итератору. В отличие от последнего двунаправленный итератор может перемещаться не только из начала в конец цепочки объектов, но и наоборот. Это становится возможным благодаря наличию оператора декремента (-). На двунаправленных алгоритмах базируются различные алгоритмы, выполняющие реверсивные операции, например reverse. Этот алгоритм меняет местами все объекты в цепочке, на которую ссылаются переданные ему итераторы. Следующий пример был бы невозможен без двунаправленных итераторов:
#include#include using namespace std; main(void) { int init[] = {1, 2, 3, 4, 5}; reverse(init, init + 5); copy(init, init + 5, ostream_iterator (cout, " ")); }
Итераторы двунаправленного доступа возвращаются несколькими контейнерами STL: list, set, multiset, map и multimap.
Итераторы произвольного доступа
Итераторы произвольного доступа - самые "умелые" из основных итераторов. Они не только реализуют все функции, свойственные итераторам более низкого уровня, но и обладают большими возможностями. Глядя на исходные тексты, в которых используются итераторы произвольного доступа, можно подумать, что имеешь дело с арифметикой указателей языка C++. Реализованы такие операции, как сокращенное сложение и вычитание (+= и -=), сравнение итераторов (<, >, <= и >=), операция обращения к заданному элементу массива ([]), а также и некоторые другие операции.
Как правило, все сложные алгоритмы, требующие расширенных вычислений, оперируют итераторами произвольного доступа. Ниже приводится пример, в котором мы используем практически все операции, допустимые для них. Исходный текст разбит на части, к каждой из которых мы приводим комментарии. Сначала нужно включить требуемые заголовочные файлы и определить константу пробела^:
#include#include #include #define space " "
Затем включить использование STL:
using namespace std;
В функции main мы описываем массив числовых констант и вектор из пяти элементов:
int main(void)
{
const int init[] = {1, 2, 3, 4, 5};
vector v(5);
Создаем переменную типа "итератор произвольного доступа". Для этого берем итератор и на его основе создаем другой, более удобный:
typedef vector::iterator vectItr; vectItr itr ;
Инициализируем вектор значениями из массива констант и присваиваем адрес его первого элемента итератору произвольного доступа:
copy(init, init + 5, itr = v.begin());
Отсюда начинается самое интересное. Воспользовавшись разнообразными доступными операторами, мы последовательно читаем элементы вектора, начиная с конца, и выводим их на экран:
cout << *( itr + 4 ) << endl; cout << *( itr += 3 ) << endl; cout << *( itr -= 1) << endl; cout << *( itr = itr - 1) << endl; cout << *( -itr ) << endl;
После этого итератор, претерпев несколько изменений, снова указывает на первый элемент вектора. А чтобы убедиться, что значения в векторе не были повреждены, и проверить оператор доступа ([]), выведем в цикле значения вектора на экран:
for(int i = 0; i < (v.end() - v.begin()); i++)
cout << itr[i] << space;
cout << endl;
}
Как видите, операции с итераторами произвольного доступа реализованы так, чтобы программист не чувствовал разницы между использованием обычных указателей и итераторов.
Итераторы произвольного доступа возвращают такие контейнеры, как vector и deque.
Вспомогательные итераторы
Вспомогательные итераторы названы так, потому что они выполняют вспомогательные операции по отношению к основным. Часто можно встретить выражения, в которых основные итераторы и вспомогательные работают "рука об руку".
Реверсивные итераторы
Некоторые классы-контейнеры спроектированы так, что по хранимым в них элементам данных можно перемещаться в заданном направлении. В одних контейнерах это направление от первого элемента к последнему, а в других - от элемента с самым большим значением к элементу, имеющему наименьшее значение. Однако знайте, что существует специальный вид итераторов, называемых реверсивными. Такие итераторы работают "с точностью до наоборот": т. е. если в контейнере итератор ссылается на первый элемент данных, то реверсивный итератор ссылается на последний. Получить реверсивный итератор для контейнера можно вызовом метода rbegin(), а реверсивное значение "за пределом" возвращается методом rend(). Следующий пример использует нормальный итератор для вывода значений от 1 до 5 и реверсивный итератор для вывода этих же значений, но в обратном порядке:
#include#include #include using namespace std; main(void) { const int init[] = {1, 2, 3, 4, 5}; vector v(5); copy(init, init + 5, v.begin()); copy(v.begin(), v.end(), ostream_iterator (cout, " ")); copy(v.rbegin(), v.rend(), ostream_iterator (cout, " ")); }
Итераторы потоков
Важную роль в STL играют итераторы потоков, которые делятся на итераторы потоков ввода и вывода. Практически во всех показанных в этой статье примерах вы найдете итератор потока вывода для отображения данных на экране. Суть применения потоковых итераторов в том, что они превращают любой поток в итератор, используемый точно так же, как и прочие итераторы: перемещаясь по цепочке данных, считывает значения объектов и присваивает им другие значения.
Итератор потока ввода - это удобный программный интерфейс, обеспечивающий доступ к любому потоку, из которого требуется считать данные. Конструктор итератора имеет единственный параметр - поток ввода. А поскольку итератор потока ввода представляет собой шаблон, то ему передается тип вводимых данных. Вообще-то должно передаваться четыре типа, но последние три имеют значения по умолчанию, и вряд ли вы решитесь их изменять прежде, чем досконально изучите STL. Каждый раз, когда вам нужно ввести очередной элемент информации, используйте оператор ++ точно так же, как с основными итераторами. Считанные данные можно узнать, если применить разыменовывание (*).
Итератор потока вывода весьма схож с итератором потока ввода, но у его конструктора имеется дополнительный параметр, которым указывают строку-разделитель, добавляемую в поток после каждого выведенного элемента. Ниже приведен пример программы, читающей из стандартного потока cin числа, вводимые пользователем и дублирующие их на экране, завершая сообщение строкой " - last entered value". Работа программы заканчивается, как только пользователь введет число 666:
#include#include #include using namespace std; main(void) { istream_iterator is(cin); ostream_iterator os(cout, " - last entered value "); int input; while((input = *is) != 666) { *os++ = input; is++ ; } }
Потоковые итераторы имеют одно существенное ограничение - в них нельзя возвратиться к предыдущему элементу. Единственный способ сделать это - заново создать итератор потока.
Итераторы вставки
Появление итераторов вставки (insert iterator) было продиктовано необходимостью. Без них просто невозможно добавить значения к цепочке объектов. Так, если в массив чисел, на которые ссылается итератор вывода, вы попытаетесь добавить пару новых значений, то итератор вывода попросту запишет новые значения на место старых, и они будут потеряны. Любой итератор вставки: front_inserter, back_inserter или inserter выполнит ту же операцию вполне корректно. Первый из них добавляет объекты в начало цепочки, второй - в конец. Третий итератор вставляет объекты в заданное место цепочки. При всем удобстве итераторы вставки имеют довольно жесткие ограничения. Так, front_inserter и back_inserter не могут работать с наборами (set) и картами (map), а front_inserter к тому же не умеет добавлять данные в начало векторов (vector). Зато итератор вставки inserter добавляет объекты в любой контейнер. Одной интересной странностью обладает front_inserter: данные, которые он вставляет в цепочку объектов, должны передаваться ему в обратном порядке. Очень неудобно, однако можно привыкнуть.
Приведем пример, как всегда разбитый на части для удобства комментирования. В нем создается список (list) с двумя значениями, равными нулю. После этого в начало и конец списка добавляются значения 1, 2, 3. Третья последовательность 1-1-1 вставляется в середину списка между нулями. Итак, после описания заголовочных файлов мы создаем массивы, необходимые для работы, и контейнер типа "список" из двух элементов:
#include#include #include using namespace std; main(void) { int init[] = {0, 0}; int init1[] = {3, 2, 1}; int init2[] = {1, 2, 3}; int init3[] = {1, 1, 1}; list
l(2);
Затем список инициализируется нулями из массива init и его значения отображаются на экране:
copy(init, init + 2, l.begin()); copy(l.begin(), l.end(), ostream_iterator(cout, " ")); cout << " - before front_inserter" << endl;
Итератором вставки в начало списка в обратном порядке добавляются значения массива init1, и производится повторный показ данных из списка на экране:
copy(init1, init1 + 3, front_inserter(l)); copy(l.begin(), l.end(), ostream_iterator(cout, " ")); cout << " - before back_inserter" << endl;
Теперь итератор вставки в конец добавит элементы массива init2 в "хвост" списка:
copy(init2, init2 + 3, back_inserter(l)); copy(l.begin(), l.end(), ostream_iterator(cout, " ")); cout << " - before inserter" << endl;
Сложнее всего обстоит дело с итератором insertes. Для него, кроме ссылки на сам контейнер, нужен итератор, указывающий на тот объект в контейнере, за которым будет произведена вставка единичек из массива init3. С этой целью мы создаем переменную типа "итератор", инициализируя ее итератором, указывающим на начало списка:
list::iterator& itr = l.begin();
Теперь специальной операцией advance делаем приращение переменной итератора так, чтобы она указывала на четвертый объект в цепочке данных списка:
advance(itr, 4);
Остается добавить данные в цепочку посредством insertes и показать итог нашей работы на дисплее:
copy(init3, init3 + 3, inserter(l, itr)); copy(l.begin(), l.end(), ostream_iterator(cout, " ")); cout << " - the end!" << endl; }
Константный итератор
Последний итератор, который мы рассмотрим, - константный (constant iterator). Он образуется путем модификации основного итератора. Константный итератор не допускает изменения данных, на которые он ссылается. Можно считать константный итератор указателем на константу. Чтобы получить константный итератор, можно воспользоваться типом const_iterator, предопределенным в различных контейнерах. К примеру, так можно описать переменную типа константный итератор на список:
list::const_iterator c_itr;
Операции с итераторами
Существуют две важных операции для манипуляции ими. С одной из них - advance - вы познакомились в последнем примере. Это просто удобная форма инкрементирования итератора iter на определенное число n:
void advance (InputIterator& iter, Distance& n);
Вторая операция измеряет расстояние между итераторами first и second, возвращая полученное число через ссылку n:
void distance(InputIterator& first, InputIterator& second, Distance& n);
Как показывает практика, этими операциями придется пользоваться весьма часто, так что тренировка вам не помешает.