 Теме экстремально масштабных вычислений (Extreme-Scale Computing) посвящены вводная заметка приглашенных редакторов, которыми в этот раз являются Адольфи Хойзи и Владимир Гетов (Adolfy Hoisie, Vladimir Getov), и пять больших статей. Редакторская заметка называется «Экстремально масштабные вычисления – там, где не работают стандартные решения» (Extreme-Scale Computing— Where «Just More of the Same» Does Not Work).
Теме экстремально масштабных вычислений (Extreme-Scale Computing) посвящены вводная заметка приглашенных редакторов, которыми в этот раз являются Адольфи Хойзи и Владимир Гетов (Adolfy Hoisie, Vladimir Getov), и пять больших статей. Редакторская заметка называется «Экстремально масштабные вычисления – там, где не работают стандартные решения» (Extreme-Scale Computing— Where «Just More of the Same» Does Not Work).
Направление экстремально масштабных вычислений находится на переднем крае активно развивающейся области высокопроизводительных вычислений (high-performance computing, HPC) и относится к аппаратным и программным средствам, позволяющим решать задачи в петамасштабном диапазоне производительности. Обеспечивая ученым новые возможности проведения имитационного моделирования небывалого размера и точности, экстремально масштабные вычисления играют роль инкубатора научных и технических идей в области компьютинга. Быстрое развитие этого направления оказывает влияние на несколько соседних областей, таких как слабосвязанные распределенные системы, grid, облачные вычисления и сенсорные сети.
Потребность в обеспечении более высокой скорости вычислений является всего лишь одной из многих проблем, возникающих при разработке новых высокопроизводительных компьютерных систем. Необходимость обеспечения высокого уровня параллелизма (в экстремально масштабных системах используются сотни тысяч процессорных элементов и миллионы параллельных потоков управления) приводит к усложнению системы: требуются средства распараллеливания алгоритмов, новое системное программное обеспечение, средства глубокой иерархии памяти, аппарат управления неоднородностью, а также механизмы требования надежности, отказоустойчивости, ограничения энергопотребления и т.д.
Для удовлетворения требований все более и более высокой производительности в направлении экстремально масштабных вычислений одновременно решаются несколько проблем, привлекающих сегодня внимание профессионального сообщества.
- Имеются ли пределы контролируемого параллелизма? Можно ли управлять миллионами потоков управления? Какие модели программирования пригодны для разработки (с осмысленными трудозатратами) приложений, демонстрирующих высокую производительность и эффективность?
- Имеются ли ограничения на число ядер, которые можно использовать для создания одного компьютера? Насколько в этом отношении существенны разнородные и гибридные схемы организации компьютеров?
- Имеются ли принципиальные ограничения на размеры внутренних соединений? Каковы разумные соотношения уровней производительности и надежности?
- Что препятствует достижению высокого уровня стационарной производительности? Как лучше всего оценивать, моделировать и предсказывать производительность в режимах экстремальной масштабности?
- В чем состоят проблемы, ограничения и перспективы системного программного обеспечения? Можно ли разрабатывать программное обеспечение с учетом неоднородности и асинхронности аппаратуры?
- Какими свойствами должны обладать подсистемы ввода-вывода и хранения данных для поддержки гигантских объемов данных, генерируемых в ходе экстремально масштабного моделирования?
- В чем состоят проблемы обеспечения высокого качества обслуживания в имеющихся сегодня и будущих экстремально масштабных системах? Можно ли преодолеть присущие крупномасштабным системам ограничения надежности и отказоустойчивости?
- Является ли неизбежным спутником экстремально масштабных суперкомпьютеров специальная энергетическая установка? Можно ли снизить энергопотребление таких систем без ущерба быстродействия?
Первую статью тематической подборки под названием «Архитектуры для поддержки экстремально масштабных вычислений» (Architectures for Extreme-Scale Computing) представил Йозеп Торрелас (Josep Torrellas).
Автономные машины могут сегодня выполнять уже около 1015 операций в секунду, что стало возможным благодаря использованию высоко параллельных архитектур. К их числу относятся суперкомпьютер Roadrunner из Лос-Аламосской национальной лаборатории Министерства энергетики США, в котором традиционные процессоры дополняются акселераторами на базе процессора Cell, в результате чего образуется гибридная платформа, а также установки IBM Blue Gene/P, использующие огромное число простых традиционных процессоров и основанные на тесной системной интеграции. К этому семейству скоро добавится система Blue Waters Иллинойского университета, основанная на применении высокопроизводительных процессоров, новых компонентов и средств интеграции.
Однако эти архитектуры почти не масштабируемы и потребляют мощность в несколько мегаватт, а один мегаватт обходится почти в миллион долларов в год. По этим причинам создатели высокопроизводительных архитектур фокусируются сегодня на экстремально масштабных вычислениях. Очевидно, что достижение возможности производить терамасштабные чипы общего назначения, петамасштабные серверы и экзамасштабные центры данных привело бы к революции в компьютерном мире, однако для разработки и построения таких систем требуется решить ряд технических проблем на всех уровнях компьютерного стека, включая схемотехнику, архитектуру, программные системы и приложения.
Следующая статья называется «Tofu: шестимерная сетчато-тороидальная топология внутренних соединений для экзамасштабных компьютеров» (Tofu: A 6D Mesh/Torus Interconnect for Exascale Computers) и написана Юхиро Аджима (Yuichiro Ajima), Шинджи Сумимото (Shinji Sumimoto) и Тошиюки Шимицу (Toshiyuki Shimizu).
Исследователи продолжают совершенствовать высокопроизводительные вычислительные системы, увеличивая число процессорных ядер в узлах и число узлов в системе. Для связывания десятков тысяч узлов во многих высокопроизводительных системах используются сетчато-тороидальные топологии, поскольку они хорошо масштабируются и экономически эффективны.
В системах с внутренними связями, построенными на базе сеток, особо важна настройка с учетом топологии. Система должна обладать возможностью непрерывно обслуживать задания, обеспечивая каждому из них тороидальную топологию, а для обеспечения высокого уровня загрузки также важна поддержка подсеток изменяемого размера. Для удовлетворения этих потребностей авторы разрабатывают архитектуру внутренних соединений Tofu (Tofu – torus fusion, слияние торов), отличающуюся более основательной сетчато-тороидальной топологией. Система Tofu может быть разделена на произвольное число прямоугольных подсеток, и в каждой подсетке обеспечивается тороидальная топология.
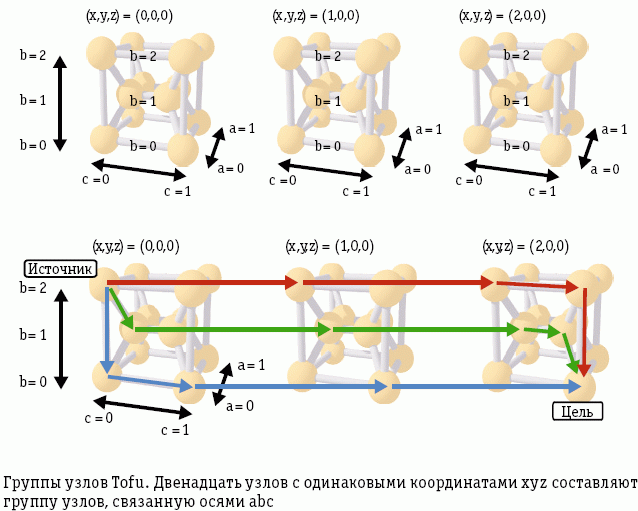
В Tofu имеется шесть осей координат: x, y, z, a, b и c. На осях a и c располагается по два узла, на оси b для обеспечения отказоустойчивости – три. Всего у каждого узла имеется 10 соединений. Двенадцать узлов с одними и теми же координатами xyz составляют группу узлов, связанную осями abc. Группу узлов можно рассматривать как единицу выделения вычислительных ресурсов для задания. На рисунках показаны три группы узлов с координатами (0,0,0), (1,0,0) и (2,0,0) и возможные маршруты между узлами разных групп.
Следующую статью под названием «Использование моделирования производительности при разработке крупномасштабных систем» (Using Performance Modeling to Design Large-Scale Systems) представили Кевин Баркер, Кей Дэвис, Адольфи Хойзи, Дарен Кербисон, Майкл Лэнг, Скотт Пэкин и Хосе Карлос Санчо (Kevin Barker, Kei Davis, Adolfy Hoisie, Darren Kerbyson, Michael Lang, Scott Pakin, Jose Carlos Sancho).
Все чаще научные открытия основываются на компьютерном моделировании, что вызывает потребность во все более быстрых суперкомпьютерах, однако по мере повышения скорости суперкомпьютеров возрастает и их сложность. Если современный высокопроизводительный настольный компьютер содержит 16 процессорных ядер, единое адресное пространство основной памяти и простую внутреннюю сеть, связывающую все ядра по принципу «каждое с каждым», то наиболее быстрые суперкомпьютеры содержат от десятков до сотен тысяч ядер, множество раздельных адресных пространств и несколько сетей внутренних соединений с разными свойствами и характеристиками производительности.
Все эти компоненты сложным образом взаимодействуют в иерархической среде и конкурируют за ограниченный набор системных ресурсов, поэтому соседние процессорные ядра должны координировать свое поведение быстрее, чем удаленные ядра, а удаленные ядра не должны конкурировать между собой за доступ к основной памяти. Петамасштабные вычислительные системы Roadrunner, Jaguar и Jugene уже не отличаются простотой, а индустрия идет дальше, и не за горами экзамасштабные системы, появление которых ожидается через пять-шесть лет и которые будут обладать пиковой производительностью, в тысячу раз превышающей производительность сегодняшних систем. Соответствующим образом возрастет и их сложность.
Сложность суперкомпьютерных архитектур затрудняет оценку того, насколько реально быстрее будут выполняться на экзамасштабных суперкомпьютерах приложения, работающие на сегодняшних менее мощных машинах, – тысячекратное повышение пиковой производительности редко приводит к аналогичному повышению скорости выполнения приложений. Сложность неизбежно приводит к падению производительности. Практически невозможно точно экстраполировать производительность приложений при переходе от одной системы к другой на основе всего лишь интуиции и умозаключений. Однако возможность предсказания производительности очень важна, поскольку помогает системным архитекторам выбирать правильные проектные решения, а ученым – стратегию переноса приложений на новые системы.
Распространенным подходом к предсказанию производительности является использование симуляторов – программ, выполняемых на существующих системах и имитирующих целевые системы. Хотя имитационное моделирование хорошо работает для быстро выполняемых приложений на ограниченном числе процессоров, у этого подхода имеются трудности с предсказанием производительности приложений, требующих продолжительного выполнения на экстремально масштабных системах. В этом случае либо симулятор должен работать на системе, размер которой сопоставим с размером целевой системы, либо протяженность времени его работы будет недопустимой, либо будет потеряна точность моделирования.
В статье описывается альтернативный подхода к симуляции – моделирование производительности. Подобно тому как модель некоторого физического процесса описывается набором формул, отражающих характерные свойства соответствующего физического явления, модель производительности представляет собой набор аналитических формул, описывающих основные характеристики сложного искусственного явления – выполнения приложения на ожидаемом в будущем суперкомпьютере. Более того, как и в случае моделирования физических процессов, модель производительности поддерживает не только предсказание, но также понимание и интерпретацию сути происходящего.
В Лос-Аламосской национальной лаборатории такое моделирование в последнее десятилетие применяется почти ежедневно для исследования производительности многочисленных систем на разных стадиях их жизненного цикла – от начального проектирования до производственного использования.
Авторами статьи «Разработка параллельных сценариев для пета- и более масштабных приложений» (Parallel Scripting for Applications at the Petascale and Beyond) являются Майкл Вильде, Ян Фостер, Камил Искра, Пит Бекман, Жао Жанг, Эллан Эспиноза, Михаэль Хейтган, Бен Клиффорд и Иоан Райку (Michael Wilde, Ian Foster, Kamil Iskra, Pete Beckman, Zhao Zhang, Allan Espinosa, Mihael Hategan, Ben Clifford, Ioan Raicu).
Использование скриптовых языков революционизирует разработку приложений для настольных компьютеров и серверов, ускоряя и упрощая программирование за счет того, что программисты могут составлять композицию существующих программ для получения более мощных приложений. Может ли разработка сценариев быть настолько же полезна для параллельных компьютеров, включая экстремально масштабные компьютеры? Авторы полагают, что да.
Скриптовые языки позволяют пользователям быстро собирать сложные приложения путем композиции уже существующего кода. При разработке параллельных сценариев пользователи могут применять к имеющимся последовательным и параллельным программам конструкции параллельной композиции. Это позволит программистам быстро специфицировать параллельные приложения, для выполнения которых в зависимости от масштаба задачи может потребоваться 16-ядерная рабочая станция или 160000-ядерная петамасштабная система.
Большая часть исследований и разработок моделей программирования для экзамасштабных машин относится к средствам разработки приложений категории SPMD (single program, multiple data). К таким приложениям относятся, например, программы вычислительной гидродинамики, применяемые для моделирования погодных условий, или строительной механики, используемые при проектировании автомобилей. Для подобных приложений требуется большая вычислительная мощность и высокопроизводительная инфраструктура обмена сообщениями. Однако было бы недальновидно полагать, что только для приложений такого рода требуются высокопроизводительные суперкомпьютеры. По опыту авторов, имеется значительная и неудовлетворенная потребность в выполнении существующих программ на новых системах, когда целесообразно одновременно выполнять много копий одной и той же программы. Каждая такая программа может быть параллельной программой, основанной на передаче сообщений, многопотоковой или даже чисто последовательной программой. Разработчикам приложений этой категории, как и разработчикам SPMD-приложений, требуются методы и инструменты, снижающие сложность разработки, повышающие уровень повторного использования и оптимизирующие производительность на различных платформах. И основу таких методов и средств могут обеспечить скриптовые языки.
Поэтому среди приоритетных исследований моделей параллельного программирования следующего поколения должны находиться исследования методов масштабирования средств написания сценариев к компьютерам XXI века. Результатам, полученным авторами в этом направлении, посвящается основная часть статьи.
Последняя статья тематической подборки написана Дэвидом Донофрио, Леонидом Оликером, Джоном Шалфом, Майклом Венером, Крисом Роуеном, Йенсом Крюгером, Шоабом Камилем и Марфубом Мохиюддином (David Donofrio, Leonid Oliker, John Shalf, Michael F. Wehner, Chris Rowen, Jens Krueger, Shoaib Kamil, Marghoob Mohiyuddin) и называется «Энергоэффективные вычисления в экстремально масштабной науке» (Energy-Efficient Computing for Extreme-Scale Science).
Вычислительная мощность, требуемая для точного моделирования сложных проблем, не может быть обеспечена при применении традиционных подходов. Построение все более крупных кластеров на основе аппаратных средств массового производства заходит в тупик из-за ограничений по энергоснабжению и охлаждению. Поэтому имеет смысл использовать опыт, полученный при разработке энергоэффективных архитектур встроенных систем. С этой целью авторы разрабатывают управляемую приложениями систему Green Flash, в которой используются многоядерный процессор, а также новые подходы к обеспечению когерентности кэшей и автоматической настройке, позволяющие повысить эффективность вычислений. Эти подходы позволяют достичь повышения эффективности на два порядка при решении задачи имитационного моделирования климата по сравнению с традиционными SMP-архитектурами.
У проблемы перевода высокопроизводительных вычислительных архитектур на экзауровень имеются экономические и политические аспекты. Для достижения вычислительной мощности, которая требуется для экстремально масштабного моделирования с точностью, достаточной для поддержки принятия политических решений, нужен новый вид компьютеров. Какие системы требуется построить, чтобы можно было решить наиболее важные научные проблемы? Например, модель глобальной климатической системы атмосферы километрового масштаба предусматривает «разбиение» атмосферы Земли на 20 млрд отдельных клеток, что требует машину с небывалой производительностью для ее обработки.
Только лишь энергоэффективных встраиваемых процессоров, хотя это и является важным первым шагом, недостаточно для решения проблемы снижения энергопотребления. Компьютерная индустрия достигла точки перегиба – подвергаются сомнению фундаментальные принципы архитектуры компьютеров. Проект Green Flash не только дает представление о том, как процессы разработки, успешно зарекомендовавшие себя в области встроенных систем, могут быть применены в научном компьютинге, но также позволяет решить некоторые сложные проблемы управления экспоненциальным ростом уровня внутрипроцессорного параллелизма, свойственные всей ИТ-индустрии.
Единственная большая статья, опубликованная вне тематической подборки, называется «Сервис-ориентированная архитектура, основанная на обязательствах» (Commitment-Based Service-Oriented Architecture) и представлена Муниндаром Сингхом, Амитом Чопрой и Нирмитом Десаи (Munindar Singh, Amit Chopra, Nirmit Desai).
Концепция сервис-ориентированных вычислений (service-oriented computing, SOC) сулит создание динамической Всемирной паутины услуг. В соответствии с этой концепцией любой человек, желающий предложить другим людям что-либо ценное, может создать и внедрить соответствующий сервис, а каждый, кто желает воспользоваться этой ценностью, может просто выбрать один или более сервисов и объединить их в требуемое приложение или другой сервис.
Нынешние сервисные архитектуры претендуют на поддержку концепции SOC, но на самом деле значительно ее ограничивают. Эта концепция подразумевает, что сервисы являются бизнес-сервисами, однако в существующих реализациях SOA сервисы интерпретируются более узко – как суррогаты вычислительных объектов. Бизнес-сервисы привлекаются (engaged) с учетом конкретных бизнес-соображений, скрытых внутри вычислительных артефактов, поэтому важно то, что бизнес-сервисы являются автономными сущностями.
Рассмотрим, как моделируется известный сценарий совершения покупки при использовании ведущих подходов SOA. Поддержка процесса покупки – это бизнес-сервис, объединяющий индивидуальные сервисы, такие как оформление заказа, платеж и доставка. Эти сервисы могут обеспечиваться разными организациями. При использовании Business Process Modeling Notation (BPMN) и Business Process Execution Language (BPEL) составные сервисы представляются как процессы, специфицируемые потоками управления и данных поверх задач. Например, на основе BPMN покупка моделировалась бы в виде трех задач (заказ, платеж и доставка), а потоки управления и данных (идентификатор книги и цена) направлялись бы из заказа к платежу и доставке.
В другом подходе к SOA, основанном на Choreography Description Language (WS-CDL), описывается процедура обмена сообщениями между сервисами. В отличие от вызовов процедур, обмен сообщениями разъединяет участвующие стороны и поэтому больше подходит для распределенных систем. На языке WS-CDL специфицируется, как сервис оформления заказа посылает сообщения сервисам платежа и доставки. Декларативные подходы способствуют повышению уровней модульности и контролируемости, но
и в них продолжают главенствовать потоки управления и данных.
В отличие от существующих подходов, в сервис-ориентированной архитектуре, основанной на обязательствах (commitment-based SOA, CSOA), главенствует бизнес-смысл привлечения сервиса, который фиксируется на основе взаимных обязательств участников. При применении CSOA задачи или сообщения ограничиваются только в тех случаях, когда это влияет на бизнес-смысл. Технически каждый участник представляется в виде агента, взаимодействие между которыми осуществляется через сервис манипулирования их взаимными обязательствами.
До следующей встречи, Сергей Кузнецов (kuzloc@ispras.ru).
Группы узлов Tofu. Двенадцать узлов с одинаковыми координатами xyz составляют группу узлов, связанную осями abc
|
Интеграция информационных систем в окружающую среду требует создания нового поколения технологий, рассчитанных на обработку больших объемов транзакций, eXtended Transaction Processing. |
|
Параллельные программы для вычислительных кластеров и сетей Разработка параллельных программ требует использования моделей параллелизма по данным и управлению, а также соответствующих языков, позволяющих написать один вариант программы для последовательного и параллельного выполнения. Такая программа, помимо описания алгоритма должна содержать правила его параллельного выполнения, «невидимые» для стандартных компиляторов с последовательных языков. |
|
Сценарии: высокоуровневое программирование для XXI века В условиях постоянного роста производительности компьютеров и изменений в масштабах и номенклатуре приложений особое значение приобретают языки сценариев, которые становятся стилем программирования XXI века. |
|
С увеличением сложности программных систем повышается роль моделирования, позволяющего интегрировать бизнес-процессы, однако и сами модели требуют к себе все больше внимания – растет не только их сложность, но и количество. Препятствием на пути эффективного использования моделей становится отсутствие доступной инфраструктуры. |
