 Cтрана, желающая создавать не просто конкурентоспособную продукцию высокого качества, а предлагать инновации завтрашнего дня, должна лидировать в высокопроизводительных вычислениях – суперкомпьютерные технологии нужны и принципиально важны, а объектом для серьезной дискуссии должны стать формы их внедрения на практике.
Cтрана, желающая создавать не просто конкурентоспособную продукцию высокого качества, а предлагать инновации завтрашнего дня, должна лидировать в высокопроизводительных вычислениях – суперкомпьютерные технологии нужны и принципиально важны, а объектом для серьезной дискуссии должны стать формы их внедрения на практике.
Современные суперкомпьютеры обладают поистине фантастическими характеристиками, некоторые образцы уже перешагнули рубеж производительности в 1 PFLOPS, и этот рост продолжается. Потенциал огромен, но какова реальная отдача от суперкомпьютеров? Судя по многозначным числам производительности, возможности большие, но нужно посмотреть на эти данные и с другой стороны – с какой реальной эффективностью суперкомпьютеры работают на практике?
Говоря об эффективности, не будем здесь обсуждать целесообразность приобретения и установки суперкомпьютеров различными организациями, поговорим о нынешней изолированности пользователя от суперкомпьютера. Через Интернет в удаленном режиме он запускает задачу, скажем, на 100 процессорах, и получает результат через 10 часов – это хорошо или плохо, быстро или медленно? Как правило, пользователь не в состоянии ответить на этот вопрос, поскольку не контролирует процесс выполнения своей программы и не знает, что происходило в системе в этот промежуток времени. А ситуация может быть самой разной. Например, сам пользователь неаккуратно задал размеры массивов, что вызвало активный свопинг, и большая часть времени ушла на обмен с дисками, эффективность работы компьютера упала на порядок. Однако пользователь остался в неведении относительно возникших проблем: шуршания дисков не слышно, моргания лампочек не видно, никаких тревожных признаков ему никто не передает. Мощный суперкомпьютер, а работает с крайне низким КПД. Почему?
Суперкомпьютеры и эффективность
Как устроен современный суперкомпьютер? Если не вдаваться в технические детали, то достаточно просто. Основа – многоядерные процессоры (например, от Intel, AMD или IBM), векторные процессоры (например, от NEC или Cray), графические процессоры (от NVidia или AMD), кристаллы с реконфигурируемой архитектурой или же что-то иное. Затем какое-то число выбранных процессоров объединяется над общей памятью в единый вычислительный узел, давая возможность сохранить единое адресное пространство и, тем самым, упростить написание параллельных программ. Далее узлы объединяются с помощью некоторой коммуникационной среды в единую вычислительную систему. При этом часть суперкомпьютерных систем сохраняет однородность архитектуры, опираясь на единую процессорную основу, а в других сознательно идут на комбинацию различных процессоров, получая неоднородные конфигурации. Суперкомпьютер Cray XT5-HE Jaguar, занимающий сегодня первую строчку списка Top500, построен на базе шестиядерных процессоров AMD, за ним идет суперкомпьютер IBM RoadRunner, в составе которого используется комбинация процессоров IBM Cell и двухъядерных процессоров AMD. На пятой строчке списка расположен китайский суперкомпьютер, объединяющий четырехъядерные процессоры Intel и графические процессоры ATI Radeon HD 4870.
Что же понимать под эффективностью суперкомпьютера? Это степень различия между теорией и практикой. Известна пиковая производительность Rpeak каждой вычислительной системы. Иногда ее называют максимальной производительностью, подчеркивая тот факт, что в реальных расчетах выше этого значения производительность данного компьютера никогда не поднимется. Иногда ее называют теоретической, делая акцент на том, что такое значение может быть достигнуто лишь в теории. На практике важна другая величина – реальная производительность Rmax, достигнутая компьютером при решении некоторой задачи и равная отношению числа выполненных операций задачи ко времени ее исполнения. Отношение E = Rmax/Rpeak и есть эффективность работы.
Эффективность современных процессоров
Предположим, что в распоряжении пользователя имеется четырехъядерный процессор Intel Clowertown/1,6 ГГц и не сложно определить реальную производительность одного ядра данного процессора на различных простых вычислительных ядрах. Если пользователь хочет ускорить расчеты и для этого собирается перейти на процессор с большей частотой, например, на Intel Clowertown/2,66 ГГц, то он обычно рассчитывает получить ускорение, равное отношению частот процессоров. Однако на практике реальное значение будет намного меньше. На рис. 1 сиреневым цветом показаны значения реальной производительности процессора Intel Clowertown 1,6 ГГц на соответствующих вычислительных ядрах. Малиновым цветом показаны «ожидаемые» значения производительности, полученные из «сиреневых» умножением на отношение частот 2,66/1,6 (на рисунке это отмечено как Clowertown/2,66 ГГц Ideal). А ярко-красным цветом показаны значения реальной производительности, полученные на тех же ядрах в ходе живых экспериментов на Clowertown/2,66 ГГц. Реальная разница в производительности оказывается намного ниже, чем ожидалось. Почему? Частота процессоров отвечает скорости обработки готовых данных. Для доставки данных из памяти в процессор используется шина FSB, которая в платформе на базе Clowertown-1,6 имеет частоту 1,066 ГГц, а в платформе на базе Clowertown/2,66 – 1,33 ГГц. Скорость работы процессора определяется пропускной способностью FSB. Для каждой из этих платформ отношение частоты процессора к частоте шины равно 1,5 и 2 соответственно (данное отношение – это число тактов процессора, приходящихся на каждый такт работы системной шины). Найдем отношение полученных значений: 1,5/2 = 0,75 – это реальное замедление работы с памятью при переходе с первой платформы на вторую. На этот поправочный коэффициент и нужно было в самом начале умножить идеальные значения, чтобы получить оценку реальной производительности при переходе с Clowertown 1,6 ГГц на 2,66 ГГц. На рис. 1 светло-голубым цветом показан результат такого умножения, и, как мы видим, он очень хорошо соответствует реально замеренным «ярко-красным» значениям. Для более сложных случаев нужно учитывать и множество других параметров архитектуры процессоров.
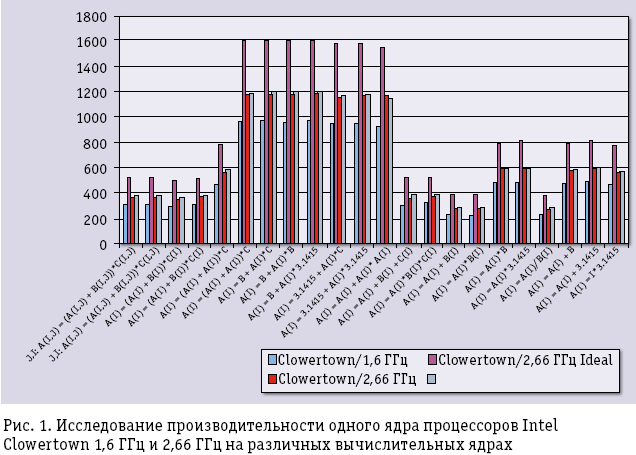
А как обстоят дела с эффективностью процессоров на тех же простых вычислительных ядрах – чему равно отношение Rmax/Rpeak? Данные, приведенные на рис. 2 для некоторых платформ, не могут не настораживать. Эффективность даже для столь простых операций лежит в интервале от 20 до нескольких процентов, причем эффективность очень зависит от интенсивности работы с памятью: если выбрать ядра с разным числом массивов и разным числом арифметических операций в теле самого ядра, то легко заметить, что эффективность процессоров быстро снижается до 3-5%.
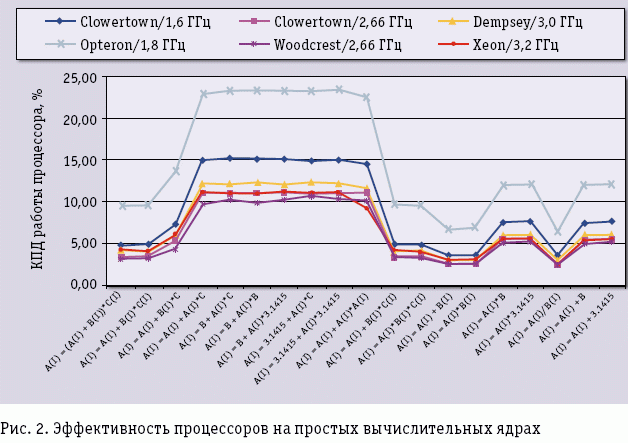
Возможно, это проблема только платформы Intel? Нет, это беда отрасли в целом. Если провести исследование эффективности реальных приложений, то понятно, что ситуация стать лучше никак не может. С помощью собственных программных инструментов компании Intel было проведено исследование эффективности работы одного ядра процессора Intel Clowertown 2,66 ГГц при выполнении задачи компьютерного дизайна лекарств. Реальная производительность оказалась примерно 400 MFLOPS при пиковой производительности 10,64 GFLOPS – выходит, что КПД работы процессора на данной задаче около 4%, что меньше, чем КПД паровоза. Сказать, что программа написана плохо, нельзя – над ней работали классные специалисты-профессионалы как в прикладной области, так и в ИТ. Аналогичная картина будет наблюдаться и на любой другой современной платформе AMD, IBM и т.п.
Для того чтобы попытаться улучшить результат, нужно углубиться в архитектуру процессоров, поскольку причин снижения производительности может быть очень много – желание повысить эффективность потребует исследования таких понятий, как: степень суперскалярности процессоров, загрузка конвейерных функциональных устройств, число уровней и объем кэш-памяти, ее ассоциативность, размеры и стратегия замещения строк, и многое другое. Работа, которая не под силу большинству прикладных специалистов.
Эффективность параллельных компьютеров и программ
Эффективность процессорной основы суперкомпьютеров низка, но хуже то, что КПД суперкомпьютера в целом относительно данного значения увеличиться никак не может, а может стать только еще меньше. На скорость исполнения параллельной программы оказывает влияние сразу целое множество факторов, поэтому анализ эффективности необходимо проводить комплексно, последовательно рассматривая все основные уровни: алгоритмы прикладной программы, системы разработки ПО, системное ПО, структура компьютера.
Эффективность процессоров мы уже оценили, а далее, на основе какого-то числа процессоров (а это сотни, тысячи и десятки тысяч) формируется суперкомпьютер в целом, что добавляет множество новых поводов опять задуматься об эффективности. В суперкомпьютерах с общей памятью, которые сегодня имеют архитектуру ccNUMA, появляется неоднородность времени доступа к оперативной памяти, а также проблемы обеспечения корректности данных в кэш-памяти (cache coherence). Заметим, что раньше это было свойственно только классическим суперкомпьютерам типа HP Superdome, IBM Regatta или SGI Altix, но сегодня это становится характерной чертой всех многоядерных систем. В суперкомпьютерах с распределенной памятью (Cray XT, IBM BlueGene, кластеры) необходимо учитывать влияние латентности и скорости передачи данных в коммуникационной среде. На КПД работы любого суперкомпьютера скажется неравномерность распределения работы между отдельными вычислительными узлами и процессорами. Эффективность суперкомпьютера может свести к нулю и бич параллельных вычислений – закон Амдала, согласно которому, если в программе 1% всех операций является последовательным (что, вроде бы и не много), то вне зависимости от числа используемых процессоров ускорения больше 100 получить нельзя. С каким КПД будет работать суперкомпьютер из 1000 процессоров на данной программе? Страшно даже подумать, а одновременно с законом Амдала наложатся и все другие упомянутые проблемы.
Много хлопот доставляет неэффективность взаимодействия программы пользователя с программно-аппаратной средой суперкомпьютера. И беда в том, что во многих случаях пользователю необходимые данные о работе его программы просто недоступны. Посмотрим на данные мониторинга динамики выполнения параллельной программы, показанные на рис. 3. Классическая ситуация. Сначала задача на всех узлах считается с максимальной эффективностью: левые области всех картинок верхнего ряда закрашены полностью, что говорит об использовании двухпроцессорных узлов суперкомпьютера на 100%. Затем в некоторый момент эффективность резко падает. Начинаем исследовать причины: одновременно с падением эффективности видим усиление свопинга (третий ряд) на фоне отсутствия каких-либо иных процессов, которые могли бы мешать работе программы (второй ряд, значение параметра loadaverage равно 2, т.е. числу процессоров на узле), и отсутствия обменов в сети (нижний ряд). Теперь становится понятным источник проблем: недостаток оперативной памяти. Увы, несмотря на их очевидную полезность, с такими данными, как правило, работает только системный администратор, а к пользователю они попадают редко.

Рис. 3. Снижение эффективности выполнения программы из-за недостатка оперативной памяти и активизации свопинга
Весьма поучительный пример показан на рис. 4а. Из него ясно следует, что КПД работы суперкомпьютера определяется не только квалификацией пользователей, но и аккуратной настройкой системного окружения администраторами. Более того, пользователям разобраться самостоятельно в таких ситуациях почти невозможно. По серому цвету верхней половины верхней диаграммы видно, что двухпроцессорный узел используется лишь наполовину, один процессор все время простаивает – на узле выполняется однопроцессорная задача. Работа другого процессора (нижняя часть верхней диаграммы) регулярно прерывается, причем с той же периодичностью резко возрастает как значение параметра loadaverage (вторая диаграмма сверху), так и активность обмена страницами оперативной памяти (нижняя диаграмма) при отсутствии сколько-нибудь заметного использования области свопинга (вторая диаграмма снизу). В системе явно порождаются новые более приоритетные процессы, захватывающие процессор на значительное время. Детальный разбор показывает, что причиной такой ситуации стала ошибка в одной строке таблицы программы cron, в результате которой трудоемкая системная операция, обычно запускаемая раз в неделю, выполнялась намного чаще.
 Снижение эффективности работы программы из-за регулярного появления посторонних процессов; б) Падение эффективности выполнения программы из-за медленной работы сетевого диска")
Рис. 4. а) Снижение эффективности работы программы из-за регулярного появления посторонних процессов; б) Падение эффективности выполнения программы из-за медленной работы сетевого диска
Падение эффективности работы программы (рис. 4б) вызвано другими причинами. С параметром loadaverage никаких проблем нет, его значение всегда около 2. Зато резко возрастает активность работы с сетевым диском (вторая диаграмма снизу, nfs_client), и пользовательский процесс ждет завершения операций записи на диск. Кстати, плохо организованная работа с сетевыми дисками часто является причиной низкой эффективности работы суперкомпьютеров в целом. Причем слова «плохо организованная работа» могут относиться и к архитекторам суперкомпьютерного проекта, и к администраторам, и к пользователям. Архитекторы могли бы учесть специфику будущих задач и предусмотреть для передачи файлов, скажем, не Gigabit Ethernet, а подумать об использовании намного более эффективных решений, например, на основе Panasas. Администраторы могли бы проверить эффективность установки NFS на своей системе и изменить значения ключевых параметров, выставляемых автоматически по умолчанию, в некоторые средние значения. Пользователь, в свою очередь, вполне мог бы задуматься о том, что на кластере есть как сетевые, так и локальные диски.
Исключительно серьезный срез, существенно определяющий эффективность работы суперкомпьютера, но который сегодня почти всегда игнорируется – анализ эффективности алгоритма, заложенного в программу. Причины, по которым выбирается тот или иной алгоритм, могут быть самыми разными, например, исторические предпочтения разработчиков, которые на протяжении многих лет использовали только определенные методы и не хотят подстраиваться под современные реалии. Это могут быть и соображения другого рода, например, необходимость быстрого получения конкретного результата, когда вопросы эффективности сознательно отодвигаются на второй план.
В этой связи отличной иллюстрацией является школьная задачка определения количества всех счастливых билетов, имеющих шестизначный номер. Билет считается счастливым, если сумма первых трех цифр равна сумме последних. После непродолжительных раздумий, можно предложить примерно следующий вариант программы:
count = 0;
for ( I1 = 0; I1 < 10; ++I1)
for ( I2 = 0; I2 < 10; ++I2)
for ( I3 = 0; I3 < 10; ++I3)
for ( I4 = 0; I4 < 10; ++I4)
for ( I5 = 0; I5 < 10; ++I5)
for ( I6 = 0; I6 < 10; ++I6) {
if(I1 + I2 + I3 == I1 + I5 + I6) ++count;
}
Число счастливых билетов будет выдано почти любым современным компьютером мгновенно, а что если количество цифр в номере будет увеличиваться? Для 8 цифр ответ будет выдан быстро, для 10 компьютер немного задумается, для 12 цифр ему потребуется больше часа, а для 14 цифр у вас не хватит терпенья дождаться ответа. Почему?
Сложность нахождения ответа, если действовать по данному алгоритму, равна 10N, где N – количество цифр в номере билета. Можно пытаться это время сократить, выполняя оптимизацию данного алгоритма, например, принимая в расчет соображения симметрии. Однако эффект от этого будет небольшой, вероятно сможет продвинуться на шаг и найти ответ для следующего значения, не для 14, а для 16 цифр. Альтернативный вариант, который кажется весьма разумным – предложить эту задачку суперкомпьютеру. Потенциал параллелизма в алгоритме огромен – если в суперкомпьютере будет 10 тыс. процессоров, значит можно эффективно использовать их все. Однако ускорение в 10000 раз в плане решения задачи позволит сделать лишь еще пару шагов – найти решение для числа цифр 20 или 22, но дальше все равно с этим алгоритмом не продвинуться.
Данный алгоритм мы реализовали быстро, он простой, но чудовищно неэффективный. Поразмышляв минут 20-30 можно найти другой алгоритм со сложность уже не 10N, а всего лишь N2. Для такого алгоритма решить задачу для 100 или 1000 цифр вообще не проблема даже на обычном ПК. Это заставляет задуматься, а часто ли авторы программ для суперкомпьютеров утруждают себя оценкой эффективности своих алгоритмов или же, как в случае первого алгоритма, суперкомпьютеры работают вхолостую?
Говоря о КПД суперкомпьютеров, нельзя не сказать и об организации работы самих суперкомпьютерных центров. В самом деле, если в некоторых центрах суперкомпьютер на выходные выключают, то показатели его эффективности можно смело умножать на 5/7. Если вычислительные узлы, содержащие по два четырехъядерных процессора, часто блокируются под монопольное выполнение последовательных задач, то КПД умножается еще на 1/8. Для запуска программы на 1000 процессоров, стоящей в очереди пользовательских заданий, требуется дождаться освобождения всех 1000 процессоров. Однако это происходит постепенно, освобождающиеся от других заданий процессоры приходится блокировать, пока не будет набрано необходимое число, а заблокированные процессоры простаивают, но общее КПД суперкомпьютера от всего этого не увеличивается.
***
Если эффективность работы суперкомпьютера на отдельной параллельной программе еще можно оценить некоторой заметной величиной, то многие суперкомпьютерные комплексы явно не дотягивают даже до КПД паровоза. Необходима целенаправленная работа по сертификации эффективности параллельных программ и вычислительных систем. Ситуация не безнадежна, но проблема есть, и воспринимать ее нужно исключительно серьезно, особенно в свете оживления интереса к отечественной суперкомпьютерной индустрии.
Владимир Воеводин (voevodin@parallel.ru) – заместитель директора НИВЦ МГУ им. М.В. Ломоносова. Работа поддержана грантом РФФИ N09-07-00168-а.
