
Неоднократно отмечено: компьютерные системы развиваются волнами. Строгой классификации этапов данного волнового процесса нет, но, ограничившись только аппаратным обеспечением, можно назвать пять или шесть таких волн: компьютеры первого и второго поколения, мэйнфреймы, мини-ЭВМ, Unix-станции и серверы, персональные компьютеры, локальные сети. Вместе с аппаратными волнами возникали и волны программного обеспечения. Между двумя этими волновыми процессами нет строгой согласованности, скорее имеется заметный фазовый сдвиг.
История показывает, что ни одна из волн — за исключением, пожалуй, самой первой — не ушла насовсем; каждая в каком-то скрытом виде продолжает свое существование. И сегодня компьютерная индустрия переживает очередную волну, на этот раз порожденную виртуализацией аппаратных ресурсов, конвергенцией сетевых и Web-технологий в приложении к корпоративным информационным системам. Пока мы находимся ближе к началу этой волны, поэтому текущий момент отличается заметной неопределенностью. То, какой нынешняя волна окажется в действительности, станет ясно через несколько лет, а пока перед нами проступают ее наиболее очевидные проявления: grid-среды и кластерные архитектуры, распределенные приложения, объединяемые в сервис-ориентированные архитектуры, системы, управляемые событиями и др.
Для «новой волны» характерна еще одна особенность, смена более частной парадигмы — переход от централизованного к распределенному хранению данных (это, в частности, подтверждается активизацией работ в области встроенных баз данных). Одно из решений, служащих для перехода к распределенному хранению данных, получило название матрицы данных предприятия (Enterprise Data Fabric, EDF)*. Основная задача технологий EDF состоит в интеграции и виртуализации тех данных, которые содержатся во включенных в корпоративную ИТ-систему серверов.
Предпосылки
В процессе эволюции корпоративных систем сложилось так, что отдельное приложение (или некоторый их набор), входящее в современную информационную систему, имеет собственную базу данных, поддерживающую его собственную модель данных и обеспечивающую этому приложению оптимальный доступ к хранимым данным. Когда-то давно такое положение вещей было вполне естественным, однако с появлением композитных приложений возникла необходимость в интегрировании разрозненных данных для получения целостного представления бизнеса. Еще одна причина, вызывающая потребность в интеграции данных, связана с тем, что у предприятия может быть несколько экземпляров систем CRM, ERP и т.п. Если каждый из них имеет свой собственный набор данных, это существенно осложняет проблемы управления, защиты информации, восстановления и др. Кроме того, фрагментация снижает эффективность принятия решений на основе анализа данных, понижая уровень удовлетворенности пользователя услугами ИТ.
Нет ничего удивительного в том, что на протяжении последних 25 лет предпринимаются настойчивые, но, увы, не слишком успешные попытки приведения всех приложений к одной стандартной базе данных. Среди предлагавшихся средств — системы интеграции приложений предприятия (Enterprise Application Integration, EAI), системы интеграции данных предприятия (Enterprise Information Integration, EII), системы извлечения, трансформации и загрузки (Extract, Transform, Load, ETL), средства репликации данных. В них интеграция данных достигалась с помощью двух основных приемов — либо путем синхронизации нескольких идентичных экземпляров базы, либо путем интеграции данных в реальном времени по предопределенным правилам и с использованием заготовленных интерфейсов. Перечисленные технологии страдают недостатком гибкости, требуют предопределения потоков данных и неэффективно используют ресурсы.
Перечисленные недостатки особенно остро ощущаются в новых условиях, характерных тем, что объемы данных в приложениях растут (в Forrester считают, что рост составляет 50% в год; с появлением новых решений, таких, как RFID, этот рост будет еще выше), повышаются требования к защищенности данных, увеличивается объем данных, востребованных в реальном времени, многократно возрастает сложность центров обработки данных.
Решением указанных проблем может стать EDF тем более что возможность для появления подобных решений обеспечивается новыми тенденциями в управлении данными.
Рост производительности и емкости оперативной памяти серверов открывает возможность для использования средств промежуточного слоя, ориентированных на работу с распределенными данными (Distributed Data Middleware, DDM). Такие технологии были известны и прежде. Одно время много ожидали от Internet Data Integration. В этом направлении работали несколько компаний, в том числе Cohera, основанная знаменитым Майклом Стоунбрейкером, и Cerebellum, но их разработки остались невостребованными из-за почти недоступности на тот момент серверов. Размещение достаточно крупных баз данных непосредственно в оперативной памяти (такую возможность предоставляет, в частности, СУБД TimesTen) позволяет создавать распределенные системы хранения, в которых эти базы играют роль буферов-кэшей.
Распределенные по системе кэши могут быть объединены высокопроизводительными шинами, обеспечивающими обмен сообщениями в реальном времени, что позволяет синхронизировать большие объемы данных посредством сообщений об изменениях без перекачивания значительных объемов данных.
Сервис-ориентированная архитектура и ее реализация с помощью сервисной шины предприятия не решает проблемы управления распределенными данными, но позволяет организовать дисциплину обмена данными, в которой какой-то определенный сервис отвечал бы за доставку поставленных ему в соответствие данных, таким образом можно обеспечить рациональное снабжение данными.
Прежде чем определить, что такое EDF, отметим, с чем EDF путать не стоит. Есть две близкие технологии. Во-первых, это виртуализация систем хранения, низкоуровневое архитектурное решение, приближенное к устройствам хранения; она не связана с созданием синхронизированного представления бизнес-данных, на этом уровне не требуется знания о структуре и семантике тех данных, с которыми эти технологии имеют дело. Во-вторых, так называемые «гриды данных»; они действительно обеспечивают виртуализацию распределенного хранения данных, однако являются частным техническим решением и могут предоставлять свои инфраструктурные сервисы EDF.
Место и роль EDF
Корпоративные информационные системы собираются из больших блоков нескольких типов; перечислим основные.
Система управления базами данных. Дисковые СУБД великолепно адаптированы к безопасному и надежному хранению больших объемов данных, однако они оптимизированы для работы с данными внутри некоторого собственного домена и оказываются малоэффективны, если данные поступают из распределенных источников, асинхронно, в режиме реального времени.
Серверы приложений. Их называют «регулировщиками», потому что они обеспечивают выполнение программных приложений на различных аппаратных платформах, оценивают потребность в ресурсах и регулируют распределение нагрузки по имеющимся вычислительным мощностям. У них тоже есть один недостаток: перераспределение приложений по платформам чревато перемещением огромных объемов данных, что снижает общую системную производительность.
Программное обеспечение обмена сообщениями. Подобный инструментарий, ставший в последнее время популярным, позволяет организовать обмен данными в стандартном формате, вызывать приложения, обеспечивая возможность взаимодействия и прозрачность данных. Однако при этом не удается обеспечить высокую скорость обмена данными и высокую готовность данных.
Средства интеграции приложений и управления бизнес-процессами. Программное обеспечение этой категории позволяет организовать потоки работ и данных между приложениями и пользователями, обеспечить нужную последовательность выполнения компонентов, позволяющую выполнить бизнес-процесс.
В этом перечне средств явно не хватает промежуточного компонента, который позволил бы наладить мгновенный, с высокой степенью готовности доступ к распределенным данным вне зависимости от того, где находятся эти данные и где размещаются приложения. Данные должны представляться в различных форматах, быть синхронизированными, иметь общий интерфейс вне зависимости от физического источника. Именно эту функцию может взять на себя EDF, выступая в роли высокопроизводительного интерфейса между данными и системами хранения, с одной стороны, и приложениями, использующими эти данные — с другой.
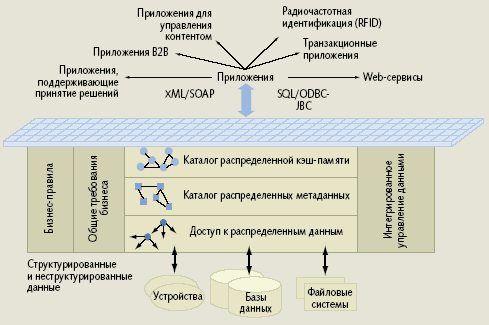 |
| Рис. 1. Компоненты EDF |
EDF образует архитектуру, которая распространяется преимущественно на данные, хранящиеся в оперативной памяти на множестве распределенных узлов. Проще всего ее представить как механизм управления кэш-памятью, расположенной в непосредственной близости от приложения и содержащей наиболее востребованные данные. Этот механизм (рис. 1) состоит из четырех основных частей: каталога распределенной кэш-памяти, центрального каталога распределенных метаданных, программных средств промежуточного слоя для доступа к распределенным данным и интегрированного управления данными. В качестве интерфейсов могут использоваться XML/SOAP (с языком запросов XQuery), а также SQL для работы с реляционными СУБД. Архитектура EDF должна гарантировать возможность работы со всеми видами данных — структурированными, неструктурированными и полуструктурированными, обеспечивая прозрачный доступ к ним вне зависимости от местоположения, с необходимой безопасностью и в соответствии с требованиями, предъявляемыми со стороны бизнеса.
Компоненты EDF
Рассмотрим основные компоненты EDF подробнее.
Каталог распределенной кэш-памяти (Distributed Cache Directory, DCD) Производительность дисков всегда была и остается важнейшим фактором, ограничивающим скорость работы приложений. Особенно она критична в тех случаях, когда требуется доступ к большому объему случайно распределенных данных или когда данные распределены по большому числу серверов. Чтобы повысить скорость использовались специальные, адаптированные к приложениям и конкретным аппаратным конфигурациям кэши. Внедрение DCD (рис. 2) позволяет преодолеть «ведомственные» ограничения, поскольку предоставляет универсальный масштабируемый виртуализированный кэш, охватывающий произвольное множество серверов.
 |
| Рис. 2. Данные в распределенном кэше |
DCD не является простым арифметическим дублированием содержимого кэшей отдельных серверов, обладая интеллектом, позволяющим управлять процессом выборки данных в виртуализированный общий кэш, используя образы данных и интенсивность их использования. Вне зависимости от расположения данных DCD может обращаться ко всем серверам, используя реестр распределенного кэша (Distributed Cache Registry, DCR). Этот реестр содержит ссылку к содержимому кэшей других серверов, входящих в EDF, обеспечивая прямую маршрутизацию в «домашние» кэши этих серверов, или создает синхронизированные копии удаленных данных.
DCD поддерживает различные типы операционных систем, обеспечивает целостность кэшированных данных, поддерживает все виды данных (структурированные, неструктурированные и полуструктурированные). В случае физического дублирования данных в разных кэшах он обеспечивает оптимальность маршрутизации для получения доступа к данным.
Репозитарий распределенных метаданных (Distributed Metadata Repository, DMR). Интеграция данных представляет собой сложную задачу; она еще более усложняется, если приходится иметь дело с большими объемами данных, особенно в случае, когда есть необходимость выполнять интеграцию в режиме реального времени. В известных интеграционных технологиях (EII, EAI, ETL) и подходах, основанных на репликации данных, приемы, используемые для доступа к данным, предопределены заранее. В отличие от них подход, основанный на DMR, обладает гибкостью, здесь распределенные данные интегрируются непосредственно «по ходу исполнения», никаких заранее определенных путей не требуется (рис. 3). Использование DMR предполагает, что метаданные распределяются по серверам, а синхронизация осуществляется в процессе исполнения. Благодаря этому DMR не сфокусирован на требованиях какого-то одного приложения или пользовательского контекста, а может настраиваться на различные специальные или универсальные приложения.
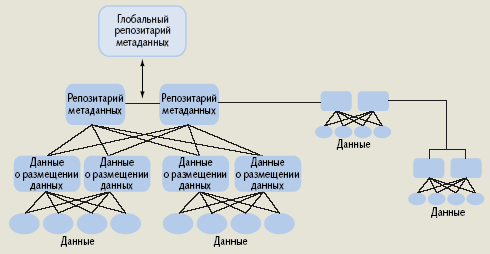 |
| Рис. 3. Репозитарий распределенных метаданных |
Инструментарий промежуточного слоя для доступа к распределенным данным (Distributed Data Access, DDA). Этот уровень отвечает за доступ к данным, распределенным по различным источникам, включая реляционные, иерархические и специализированные СУБД, плоские файлы и т.д. DDA обеспечивает работу со структурированными, полуструктурированными и неструктурированными данными (аудио, видео, электронная почта, другие форматы). Он должен понимать структуру всей этой информации и быть в состоянии помещать ее в требуемый контекст.
Интегрированное управление данными (Integrated Data Management, IDM). IDM отвечает за доступ к данным и их целостность, а также за интеграцию всех остальных компонентов механизма EDF в единую систему.
На протяжении ряда лет крупные телекоммуникационные, финансовые и страховые компании решали проблему кэширования корпоративных данных, но эти решения были частными («проприетарными»), а потому чрезвычайно дорогими и не предназначались для тиражирования. Буквально в последний год начали появляться первые продуктовые решения. По данным аналитической компании Forrester, пока ни один из производителей не может предложить комплексное решение, в котором бы на равных присутствовали все перечисленные четыре компонента EDF. Участников формирующегося рынка можно разделить на три категории — компании, специализирующиеся на СУБД, средствах интеграции и системах кэширования. Первые успешны в управлении распределенными данными, но им не хватает технологий для работы с неструктурированными данными и каталогами распределенных данных и метаданных. Вторые, естественно, сильны в интеграции, но им также не хватает технологий для работы с неструктурированными данными и каталогами распределенных данных и метаданных. Третьи, специалисты по кэшированию, имеют слабости в вопросах управления распределенными ресурсами. Аналитики приходят к выводу, что в ближайшее время должна произойти консолидация возможностей разных производителей.
EDF и SOA
Структура EDF может быть встроенной в виртуальную машину сервера приложений или распределена в виде кэшей по кластеру, состоящему из серверов. EDF можно рассматривать как программный инструментарий промежуточного слоя, дополняющий сервисную шину предприятия (Enterprise Service Bus, ESB). Точно так же, как ESB оперирует потоками сервисов и управлением, EDF может обеспечивать распределенные операции над данными, благодаря чему компоненты, входящие в ESB, смогут получить к ним надежный доступ, используя для этого различные форматы.
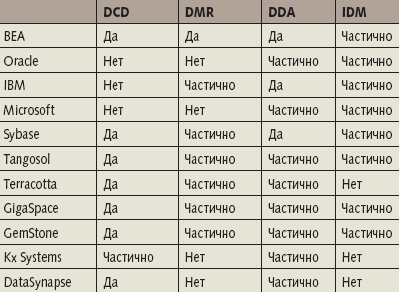 |
| Сравнение предложений участников рынка EDF |
Чем же вызвана потребность в EDF? Если мы сравним традиционные архитектуры, которые построены с использованием классического набора, состоящего из СУБД и клиент-серверных систем, и архитектуры SOA, то обнаружим принципиальные различия. В первом случае все жестко связано и заблаговременно предопределено, а в среде SOA сервисы связаны слабо, и, следовательно, пути перемещения данных (data path) и шаблоны доступа к данным (data access pattern) заранее не известны и не могут быть определены. В то же время количество сервисов может возрастать, неожиданным образом могут увеличиваться объемы передаваемых данных. Эта неопределенность влияет на надежность и масштабируемость системы, может стать причиной нарушения соглашений об уровне обслуживания. Очевидно, что складываются условия, аналогичные тем, которые привели к появлению программного обеспечения промежуточного слоя*.
На рис. 4 структура EDF представлена как платформа промежуточного слоя для работы с данными. В ее функции входит:
- обеспечение сервисов операционными данными с минимальной задержкой и виртуализация информации, используемой приложениями;
- обеспечение доступа со стороны сервисов к данным, размещенным в системах хранения заднего плана;
- управление распределенными данными и координирование работы сервисов с данными;
- обеспечение работы с потоковыми данными и поддержка процессов, управляемых событиями;
- предоставление надежной сети с высокой степенью готовности, устойчивой по отношению к нарушениям в работе сети и приложений;
- поддержка динамической интеграции данных, агрегация данных с использованием метаданных;
- сохранение данных в различных форматах.

Рис. 4. Структура EDF
На системном уровне EDF размещается между уровнем сервисов и уровнем систем хранения данных. EDF образует основу для работы сервисов с данными, размещенными в кэшах в оперативной памяти, включая доступ к данным, выполнение запросов, передачу данных и совместное использование разными сервисами. При этом решается проблема согласования форматов данных. В силу своей универсальности сервисы должны иметь доступ к корпоративным данным по стандартным интерфейсам, однако большинство традиционных репозитариев данных используют собственные форматы. С помощью EDF эта проблема снимается, эта структура замещает традиционные репозитарии сервис-ориентированными, представляя данные такими API-интерфейсами, как SOAP или XML:DB, кроме них могут быть использованы Java, C++ и C#. Структура EDF поддерживает языки запросов Xpath, SQL и OQL (Object Query Language). Этими средствами в совокупности обеспечивается прозрачность размещения данных; другими словами, сервис может получить требуемую ему информацию, не зная источника данных и без настройки на форматы и интерфейсы.
Средства для управления метаданными, заложенные в EDF, можно рассматривать как развитие посреднической функции в работе с данными, выполняемой спецификацией Service Data Objects (SDO). Напомним, что спецификация SDO, разработанная совместными усилиями компаний BEA Systems и IBM, была одобрена участниками процесса Java Community Process. В версии 2.0 она была опубликована в ноябре 2005 года как составная часть компонентной сервисной архитектуры Service Component Architecture. Она не только обеспечивает стандартизованный канал для доступа к данным, но и одновременно служит хранилищем для XML-документов, объектов и реляционных данных.
Внедрение EDF помогает решить несколько важных проблем.
Кэширование в оперативной памяти часто используемых данных — распространенная техника. Однако при использовании 32-разрядных серверов размер кэша ограничен 4 Гбайт, да и при переходе на 64-разрядную архитектуру размер кэш-памяти ограничен ее стоимостью. Постоянная же доступность данных, обеспечиваемая EDF, служит серьезному ускорению бизнес-процессов.
Нередки ситуации, когда близкие данные оказываются востребованными разными сервисами. При использовании централизованной системы хранения (например, такой, как СУБД) может возникнуть коллизия, называемая «бутылочным горлышком ввода/вывода». Внедрение EDF дает возможность распределять данные между сервисами, поскольку предполагает реализацию модели множественного доступа сервисов к общему массиву данных; в таком случае возникновение коллизии исключено.
Слабая связанность сервисов помимо достоинств имеет недостатки. Один из них состоит в том, что между сервисами и процессами есть противоречие: сервисы по определению не могут иметь собственного состояния, а бизнес-процессы, что не менее очевидно, его имеют. Наличие состояния процессов отражается в работе с данными, последовательность потребления данных отражает состояние бизнес-процесса. Если это обстоятельство не учитывать, не создавая благоприятных условий для использования данных из предыдущих фаз бизнес-процесса, то возрастает латентность. Кэширование позволяет преодолеть этот недостаток; средствами EDF удается косвенным образом отразить состояние и контекст бизнес-процесса, поскольку ранее использованные данные уже оказываются загруженными в кэш. Очевидна полная аналогия использования кэш-памяти в микропроцессоре при выполнении программ.
В тех случаях когда доступ клиентов к сервисам осуществляется с использованием многоуровневой Web-модели, управление сессиями становится болевой точкой SOA. При этом проблема, связанная с возникновением узких мест, возникает из-за необходимости хранить объекты. Их можно хранить либо в базах данных, либо в Web-контейнерах (например, в серверах приложений J2EE). И в данном случае EDF предлагает более эффективную модель управления сессиями, поскольку сессионные данные хранятся в оперативной памяти.
Использование EDF позволит шире раскрыть возможности SOA. Например, еще одно преимущество EDF проявляется в тех случаях, когда необходимо наладить обмен данными между «родственными» бизнес-процессами. Кэширование близких данных позволяет заменить поток работ, создаваемый посредством сообщений (Messaging-Centric Workflow), на поток работ, создаваемый с использованием корпоративной структуры данных (Data Fabric-Centric Workflow). Отказ от обмена сообщениями в пользу работы с общими данными — как и любая «антибюрократическая» мера — способствует повышению эффективности. Ускорение работы сервисных систем может оказаться особенно критичным при переходе к обработке потоковых данных, поступающих от систем радиочастотной идентификации или обработки событий в системах, управляемых событиями.
EDF и grid
С тех пор как Дэвид Фабер впервые выдвинул идею объединения компьютеров в grid, прошло 33 года. Попытки ее реализовать, предпринимавшиеся на протяжении прошедших лет, остаются не слишком успешными, хотя перспективность совместного использования вычислительных ресурсов не вызывает сомнения. Причину этого обычно видят в неэффективности нынешних моделей grid применительно к работе с данными. Допустим, что клиент обратился к grid для решения некоторой задачи, диспетчер обнаружил некоторые узлы и осуществил необходимую маршрутизацию. После этого выделенные узлы обращаются к клиенту за необходимыми данными, как следствие возникает интенсивный поток обращений к хранилищу данных клиента, далее в процессе работы распределенного по узлам grid приложения могут возникать ситуации, когда появляется необходимость в синхронизации по данным между узлами grid или во взаимном обмене данными. Традиционные источники данных, такие как файловые системы или базы данных, используют для хранения исключительно диски, как следствие — непрогнозируемая и негарантированная латентность и ограничения по части масштабирования. Поэтому до сих пор grid связывали в основном с научными задачами, где объем вычислений превалирует над объемом обрабатываемых данных. Однако с появлением SOA возросла привлекательность grid с точки зрения задач обработки больших объемов данных. Необходим инструментарий, который бы позволил обеспечить доступ к большим объемам распределенных данных с низкой латентностью и высокими показателями готовности и надежности; на эту роль претендует EDF.
На рис. 5 представлена гипотетическая модель grid с использованием EDF. Ее отличает ряд особенностей. Прежде всего, это виртуализация данных. EDF конвертирует фрагменты памяти, распределенные по различным узлам, выделяя один узел данных с его логической моделью. Приложения работают только с ним, не имея доступа к источникам данных. Таким образом обеспечивается прозрачность размещения и нейтральность по отношению к форматам. Кэширование и распределение данных осуществляются на уровне оперативной памяти. Конкретная же реализация кэширования может быть различной — от виртуализации памяти отдельных узлов до выделения специального сервера, память которого играла бы роль физического кэша. Характерная для EDF репликация данных служит основой для высокой готовности.

Рис. 5. Гипотетическая модель grid с использованием EDF
* Слово fabric можно перевести и иначе — «корпоративная структура», «строение», «сооружение», «здание» но только не как «фабрика», как того хотелось бы некоторым — Прим. автора.
* Термин middleware (программное обеспечение промежуточного слоя) относится к числу самых старых в программной инженерии; он впервые прозвучал в 1968 году на знаменитой конференции НАТО в Гармиш-Партенкирхене (Германия), где обсуждался кризис в программном обеспечении — Прим. автора.
Полезные советы желающим внедрить EDF
Ноэль Юханна и Майк Гилпин, аналитики Forrester, дают следующие советы желающим внедрить EDF (см. Noel Yuhanna, Mike Gilpin Information Fabric: Enterprise Data Virtualization, An Emerging Trend That Will Revolutionize Access To Information. Forrester Research, January 2006).
- Разберитесь с данными. Одна из самых сложных задач заключается в классификации данных по их значимости, по источникам, по тому, как они интегрированы в систему. Необходимо уточнить метаданные и интерфейсы каждого приложения.
- Разделите приложения и данные. Приложения должны быть сосредоточены на собственной логике и интерфейсах, а не заниматься ни интеграцией данных, ни управлением ими.
- Больше внимания уделяйте стандартам. Отказ от частных решений в пользу таких стандартов, как SQL, XML, SOAP, XQuery, X-Path и т.п., упростит внедрение EDF.
- Внедряйте постепенно. Не следует сразу пытаться включить все четыре компонента EDF — DCD, DMR, DDA и IDM — одновременно.
- Начинайте с небольшого числа приложений. Не следует браться сразу за амбициозный проект, для начала достаточно двух-трех приложений.
- Развивайте свою корпоративную структуру данных плавно. EDF — это не проект, а инициатива, которая определяет пункт назначения; путешествие может быть долгим.
