Новый этап развития систем хранения данных открывает возможность для распространения объектных технологий и в этой области.

За неимением адекватного перевода для термина storage в отечественной литературе слишком часто используется словосочетание «система хранения данных». Его традиционно относят не только к сложным системам хранения, но и к отдельным устройствам, что, впрочем, вполне корректно, — действительно, современные устройства представляют собой сложные технические системы, — но слишком тяжеловесно. Как следствие, для простоты в профессиональной устной речи обычно используют русифицированное слово «сторидж», однако этот неологизм, допустимый в профессиональном жаргоне, для письменной речи не подходит. Дабы не коверкать язык, возможно, имеет смысл вернуться к старому, но подзабытому «запоминающему устройству», или ЗУ. Если воспользоваться этим несколько архаичным термином для наименования отдельного накопителя, то устройство останется устройством, а система хранения, состоящая из комплекса аппаратных и программных средств, — системой.
В таком случае корпоративной системой хранения данных будем считать систему, которая состоит из следующих трех типов компонентов:
- дисковые и другие запоминающие устройства;
- хосты, т. е. устройства, подключенные к сети и выполняющие функции серверов для файлов, данных и метаданных;
- сеть, объединяющая эти компоненты в единую систему.
Среди различного типа запоминающих устройств на данном этапе главную роль играют дисковые накопители, а вспомогательную — магнитные ленты, оптические и другие устройства, которые используются прежде всего в подсистемах архивации. Но вот что удивительно: несмотря на критически важное место жестких дисков в системах и очевидный прогресс по показателям роста емкости и снижению стоимости хранения, со времен первого диска RAMAC, созданного ровно полвека назад, основные принципы создания дисковых запоминающих устройств, по существу, не изменились. С точки зрения физических принципов магнитной записи сохраняется та же самая продольная запись на вращающуюся поверхность. С точки зрения представления приложениям хранящихся на диске данных через API используется все тот же блочный интерфейс. Сейчас он существует в двух наиболее распространенных версиях SCSI и ATA, а также в многочисленных вариациях на тему этих интерфейсов.
Однако все меняется. С ростом мощности контроллеров появилась возможность возложить на внутреннюю логику дисков более сложные функции, что позволяет перейти от простых блочных интерфейсов к более сложным объектным интерфейсам и соответственно к объектным архитектурам систем хранения (Object-based Storage, ObS) и объектным запоминающим устройствам (Object-based Storage Device, OSD). Всеобщего согласия в том, как именно в данном случае трактовать объектный подход и какой смысл вкладывать в слово «объект», пока нет. На данный момент существует несколько концепций ObS и в каждой из них есть свое собственное определение того, что является объектом. Но в любом случае под объектом понимается порция данных, обладающая определенными характеристиками, к которой можно обращаться как к единому целому. Оболочка объекта представлена метаданными, содержание которых зависит от конкретного решения.
Наряду с объектными подходами к развитию систем хранения исследователи изучают и иные альтернативные решения, направленные на совершенствование блочных дисков. Среди них, пожалуй, наибольший интерес представляют семантические интеллектуальные дисковые системы (Semantically-smart Disk System, SDS), разрабатываемые в Университете Висконсина, однако разработки эти пока находятся на уровне лабораторных экспериментов.
Вне зависимости от конкретной природы объектов, от того, каков состав метаданных, как их интерпретируют авторы того или иного подхода, переход к ObS можно представить как эволюционный переход, восхождение на следующую ступень в архитектуре систем хранения. Объекты можно представить как логическую группировку физических блоков, а потому допустима аналогия между объектным подходом к организации дисковой памяти и заменой физических адресов на символические идентификаторы в языках ассемблера, предложенной много лет назад. Аналогия эта не вполне точна, но у макрокоманд и объектов есть общие черты, поэтому воспользуемся ею.
Специфика табличной организации определяет два присущих блочным системам ограничения. Во-первых, поскольку внутри диска пространство хранения никак логически не делится, решать проблемы безопасности можно только на уровне всего устройства в целом. Во-вторых, из-за недостаточности интеллекта собственного контроллера распределение ресурсов накопителя может быть только внешним по отношению к запоминающему устройству. Если же связать порции данных в блоки, т. е. сделать элементами хранения объекты, иначе говоря, «заменить отдельные команды макрокомандами», наделить контроллер диска большими функциями, то эти ограничения автоматически будут сняты. В программировании замена физической адресации на логическую придает коду мобильность, а в данном случае позволяет контроллеру запоминающего устройства самостоятельно перемещать хранимые данные и распоряжаться адресным пространством хранения. Становится возможным не только читать и записывать объекты, но еще и создавать и удалять их, назначать и в последующем оперировать атрибутами объектов, обеспечивать пообъектную защиту данных.
Известно три относительно независимых, но родственных по своей сути подхода к созданию ObS. Внешне они различаются тем, на каком уровне в общей архитектуре хранения появляются объекты, и тем, какой смысл вкладывается в понятие «объект». Из трех подходов первые два можно назвать низкоуровневыми, в них объекты представляются на уровне файловой системы. Третий подход — высокоуровневый, в нем объекты представляются на уровне прикладных программных интерфейсов API. (В конечном счете, на дисках данные все равно хранятся и будут храниться в обозримом будущем в виде дисковых секторов и сегментов; поэтому, не увлекаясь жонглированием терминами, следует подчеркнуть, что основное различие объектных подходов, по сути, состоит в том, где и как хранятся метаданные, относящиеся к хранимым данным. В системе хранения объектным может быть один из перечисленных уровней — верхний или нижний; но они не являются альтернативными, поэтому объектными могут быть и оба уровня.)
Хронологически первым был подход, предложенный исследователями из Университета Карнеги-Меллона совместно с инженерами компании Seagate [1]. Его авторы ставят своей целью создание объектных запоминающих устройств, которые можно использовать в существующих системах хранения наряду с сетевыми файловыми накопителями категории NAS и блочными устройствами, включаемыми в сети хранения SAN с тем, чтобы суммировать сильные стороны обоих способов хранения.
Второй подход возник в связи с необходимостью комплектовать Linux-кластеры и другие системы с массовым параллелизмом, используемые для высокопроизводительных вычислений, такими системами хранения данных, которые были бы в состоянии обеспечить адекватную скорость обмена в режиме параллельного доступа к данным. Соответствующие запоминающие устройства могут строиться на основании спецификации Object-based Storage Device (OSD), предложенной ANSI в 2004 году. Данная спецификация представляет собой расширенное множество набора команд SCSI. Наиболее продвинутые решения такого типа предлагают компании Panasas, Isilon и OnStor. Все эти решения построены на базе открытой кластерной файловой системы Lustre [2]; в этом названии несложно увидеть указание на Linux и Cluster.
Третий подход к объектному хранению возник как развитие идеи контентно-адресуемых запоминающих устройств (СAS). Любопытно, что такие устройства стали теперь называть Content Aware Storage (aware переводится как «знающий», «осведомленный», «сведущий», «сознающий»), т. е. «запоминающее устройство, знающее о содержании хранимых данных». В этой трактовке аббревиатуры CAS ослабляется связь между хранимым контентом и методом адресации к нему; Content Addressed Storage теперь рассматривается как один из возможных способов адресации к данным. Первой в этой области была компания EMC с ее накопителем Centera, в 2006 году аналогичные решения уже предлагают или намерены предложить в ближайшее время IBM, HP, Sun Microsystems и Hitachi Data Systems.
От DAS к FAS
С момента их создания и на протяжении десятилетий господствовало прямое подключение запоминающих устройств к серверам; это решение казалось единственно возможным. Но относительно недавно появились альтернативные возможности, и тогда потребовалось ввести специальную дефиницию для доселе безымянной организации систем хранения; ее назвали Direct Attached Storage (DAS). Помимо очевидных сложностей, связанных с администрированием и масштабированием, ограничивающих применение DAS, присущий ей единственно возможный блочный способ обмена с запоминающим устройством ограничивает возможности для распределенного доступа к данным. Ограничение следует уже из того, что любая шина — а чаще всего используемая в DAS параллельная шина SCSI — имеет физические ограничения по количеству подключаемых устройств. Это физическое ограничение, но есть еще и ограничение организационное, оно критичнее. Дело в том, что метаданные, необходимые для доступа к файлам, могут находиться на одном сервере, и управлять ими может операционная система именно этого сервера, распределить хранения метаданных сложно. Под метаданными в данном случае понимаются вспомогательные данные, описывающие организацию хранения. Если речь идет о дисковых массивах, то в метаданные входят такие сведения, как «принадлежность данных к массиву», размер и размещение сегментов, описание логических дисков и разделов. Конкретный состав метаданных в файловых системах определяется типом файловой системы (обычно это имя файла, его характеристики, степень секретности, список адресов блоков, в которых данный файл размещается).
На практике данные, помещенные в DAS, могут быть общим ресурсом только для машин, входящих в единый, жестко связанный кластер. Альтернативой DAS является структурированная и коммутируемая система хранения Fabric Attached Storage (FAS). Сегодня решения, попадающие в категорию FAS, могут быть реализованы в виде двух возможных конфигураций — либо Network Attached Storage (NAS), либо Storage Area Network (SAN). Они появились независимо друг от друга и существуют практически параллельно; введение же понятия FAS можно рассматривать как стремление к конвергенции SAN и NAS, желание не противопоставлять их друг другу, чем грешат некоторые авторы. Жизнь показывает, что решения типа FAS в том или ином виде становятся почти повсеместными, а DAS превращаются в нишевые. Преимущества системы хранения FAS заключаются в том, что она позволяет консолидировать метаданные в централизованный репозитарий, что обеспечивает распределенный доступ к ним множеству серверов. Инфраструктура такой системы хранения может быть создана с использованием сетевых технологий (например, Ethernet, iSCSI или Fibre Channel).
Решение NAS отличает то, что оно базируется на файловой архитектуре, серверы подключаются к запоминающим устройствам посредством IP-соединений (например, по локальной сети), что обеспечивает распределенный доступ к данным в виде файлов. Управляющие этой архитектурой файловые серверы размещаются в самих запоминающих устройствах, благодаря чему они получают монопольное право работать с метаданными, описывающими данные, а клиенты для доступа к файлам могут использовать стандартные протоколы, такие, например, как CIFS (Common Internet File System) или NFS (Network File System). Поскольку файловый сервер, расположенный в NAS, выполняет всю работу с метаданными, его клиенты освобождены от необходимости помнить о метаданных, знать, где файлы физически размещены: для обращения к ним достаточно имени.
Второе лицо FAS — сеть хранения SAN. Она отличается тем, что является коммутируемой: обязательная в NAS шина заменяется коммутируемой структурой (switched fabric), а элементом хранения является не файл, а блок. Достоинство коммутации в том, что она позволяет увеличивать и объем хранения, и скорость доступа к данным. Чаще всего для организации SAN используется протокол Fibre Channel, реже протокол iSCSI, позволяющий передавать команды SCSI по стандартным IP-сетям. Технология SAN позволяет преодолеть ограничения технологии NAS, но и она не свободна от определенных недостатков. Во-первых, хотя SAN и позволяет объединять в распределяемую структуру множество хостов, включая серверы и ЗУ, возможности серверов по части распределенного доступа к данным весьма ограниченны. Причина заключается в том, что все серверы должны единым образом интерпретировать метаданные, следовательно, подобно DAS, среда SAN остается жестко связанной. Во-вторых, проблема обостряется безопасности. В SAN безопасность основывается на маскировании LUN — логических номеров устройств (т. е. идентификационных номеров, присвоенных устройствам, подключенным к адаптерам SCSI), а это достаточно грубое решение.
Очевидно, что NAS и SAN являются взаимодополняющими технологиями: NAS обеспечивает кросс-платформное разделение доступа к файлам, а SAN — распределенный доступ к устройствам на уровне блоков. Но между ними образовался технологический «зазор». Было бы вполне естественным преодолеть этот зазор и каким-то образом совместить оба подхода, тогда можно компенсировать недостатки и ограничения каждого из решений. Однако для этого нужен принципиально новый подход, позволяющий радикальным способом избавиться от отмеченных ограничений. Сегодня представляется, что объектные запоминающие устройства (Object-based Storage Device, OSD) можно рассматривать как базис для такого подхода, они смогут совместить в себе лучшее из двух миров
Объектные запоминающие устройства
Пионерами в области OSD были исследователи из лаборатории Parallel Data Lab Университета Карнеги-Меллона, с 1999 года работавшие вместе с сотрудниками компаний Seagate и Intel. По их определению, «работу с объектами можно представить как конвергенцию двух технологий, блочной и файловой; конвергенция достигается за счет внедрения в файловую систему промежуточного слоя, состоящего из объектов».
В представлении Майка Мейснера и его коллег объекты занимают промежуточное положение между файлами и блоками. Объекты можно рассматривать как универсальные контейнеры для данных, которые ведут себя как файлы с точки зрения резервирования адресного пространства и доступа к данным и обеспечения их безопасности, но при этом как блоки удобны для распределенного доступа к ним. От файлов объекты заимствуют атрибуты данных, недоступные пользователям, и те метаданных, которые используются для управления запоминающих устройств. Как результат в объектах воплощаются сильные стороны двух подходов. Они, как файлы, обеспечивают более высокий уровень абстракции данных и, следовательно, возможность доступа независимо от типа платформы, осуществляющей доступ, а также возможность организации безопасности хранения в соответствии с заданными правилами, но одновременно как блоки доступны посредством коммутируемых устройств. Объекты могут быть произвольного размера и могут хранить любые типы данных; один объект может стать хранилищем всей файловой системы или всей базы данных. Соответственно пользователями этих контейнеров могут быть приложения, предназначенные для работы с системами хранения, такие как файловые системы или базы данных, которые в состоянии решить, что именно хранить в объекте. Но поскольку размеры объектов меняются динамически, степень занятости адресного пространства запоминающего устройства может быть известна только ему самому, поэтому оно должно ведать вопросами его распределения.
В качестве физического устройства OSD может выступать отдельный диск, дисковый контроллер, а в некоторых случаях — даже лента или оптический диск. Основное отличие OSD от дискового блочного устройства заключено не физике носителя, а в способе организации интерфейса с ним. При использовании обычного блочного устройства любую файловую систему можно условно разделить на два уровня. На системном уровне действуют пользовательский компонент и локальный компонент, управляющий запоминающим устройством; последний переносится непосредственно на устройство (рис. 1а). Пользовательский компонент ответственен за предоставление данных приложениям в форме традиционных логических структур файлов и каталогов, а компонент запоминающего устройства отображает логические структуры в физические блоки. В OSD компонент запоминающего устройства переносится непосредственно на устройство, в таком случае устройство становится более интеллектуальным; обмен с ним становится возможным на уровне объектов (рис. 1б).
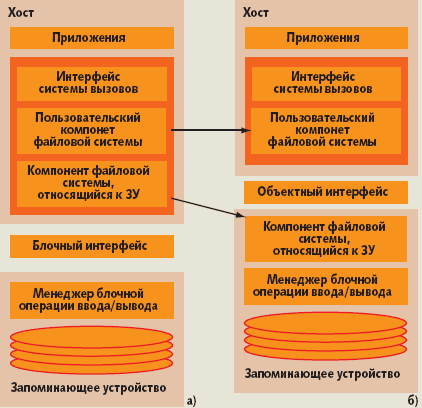
|
| Рис. 1. Файловая система в блочном и объектном запоминающем устройстве |
Разделение ответственности за работу с данными между двумя уровнями позволяет перенести функции управления устройством непосредственно в OSD; при этом интерфейс с пользовательским компонентом файловой системы остается неизменным. В этом и заключается основное достоинство ObS, характерное для многоуровневых систем. Здесь просматривается полная аналогия с программным обеспечением промежуточного слоя. Наличие посредников-объектов сохраняет для приложений все привычные способы доступа к данным, и в то же время совершенно равный доступ к тем же объектам получает множество приложений, обеспечивая тем самым распределенный доступ к данным. Распределение становится возможным благодаря тому, что приложениям, размещенным на разных серверах, оказываются доступными не только данные, но и метаданные; используя их, они могут получить доступ к одним и тем же объектам.
Распределенный доступ к данным естественно потребует создания специального механизма для координации. Интерфейс распределенного доступа может быть построен на принципах, заимствованных из стандартов Common Internet File System (CIFS) или Network File System (NFS), что дает возможность для доступа из разных платформ. Наличие объектов позволяет построить гибкую систему обеспечения безопасности, защита может распространяться на все запоминающие устройства в целом, на набор объектов или отдельный объект, и даже на отдельные байты в объектах.
Работы по стандартизации OSD начались в 1995 году, они велись силами рабочей группы ISIC NASD (Information Storage Industry Consortium, Network Attached Secure Disks). Впоследствии эта функция перешла в SNIA, и в 2004 году комитетом Т10 был выпущен стандарт ANSI INCITS 400-2004, являющийся развитием системы команд SCSI.
Объектное запоминающее устройство представляется как дисковый накопитель, содержащий непосредственно вращающийся на шпинделе диск, процессор, оперативную память и сетевой интерфейс, позволяющий локальными данными и обслуживать запросы, поступающие из сети. Подобное устройство является основой для архитектуры Object Storage Architecture, являющейся аналогом SAN в традиционных системах хранения. В объектной сети хранения Object SAN предусмотрено использование Gigabit Ethernet и протокола iSCSI, которые транспортируют команды SCSI по TCP/IP. Стандарт SCSI поддерживает несколько наборов команд, предназначенных для управления блочными устройствами, дисковыми устройствами, принтерами; теперь же он дополняется командами, предназначенными для OSD, что позволяет запоминающим устройствам, подключенным к коммутирующей структуре iSCSI over Ethernet, быть доступным для всех узлов сети. Устройство типа OSD обеспечивает выполнение четырех основных функций.
- Хранение данных. Данные хранятся в виде треков и секторов, но вовне доступны с использованием идентификаторов объектов (object ID). Чтобы тем или иным образом использовать данные, узел сети должен вычислить конкретный идентификатор объекта, смещение относительно начала объекта и размер порции необходимых для чтения или записи данных. (Здесь наблюдается полная аналогия с адресацией данных, используемой в языках ассемблера.)
- Интеллектуальное размещение. Память и процессор устройства для оптимизации процессов размещения данных на диске и подготовки к чтению (pre-fetching). Для этого используется информация, сопровождающая данные; так, метаданные, указывающие длину записи, могут быть использованы для выделения непрерывной области на диске, а сведения о читаемых данных — для заблаговременной переписи их в кэш-память.
- Управление метаданными. Устройство оперирует метаданными, относящимися к тем объектам, которые оно хранит.
- Обеспечение безопасности. Каждая команда или фрагмент данных снабжается криптографическим средством идентификации, так называемым «токеном»; устройство хранения использует его для авторизации обращений и отвергает те обращения, которые не проходят проверку.
В апреле 2005 года на конференции Spring 2005 компании IBM, Seagate и Emulex продемонстрировали первые работающие устройства OSD. В настоящее время ведется работа над общим отраслевым стандартом SNIA/T10 OSD.
Объектные системы хранения для кластеров
Вероятно, самой первой практической областью применения OSD стали системы хранения для высокопроизводительных систем с массовым параллелизмом. Появление тонких серверов и серверов-лезвий открыло широкую возможность для создания высокопроизводительных кластеров, связанных посредством Gigabit Ethernet или InfiniBand. Но как только они появились, обнаружилось, что ни одна из существующих архитектур хранения не соответствует потребностям этих компьютеров. И SAN, и NAS удовлетворяют требованиям кластеров весьма ограниченного размера. Поэтому для распараллеливания доступа к данным приходится искусственным образом разделять данные, создавая из них избыточные копии (этот процесс назвали staging), а затем собирать результат вновь (destaging).
Основной ресурс для повышения производительности систем хранения заключается в распараллеливании работы хостов и устройств хранения, но на этом пути барьером встает усложнение каталогов и файловых систем. Так, если устройство хранения снабжено некоей собственной файловой системой, доступ к которой должен распределяться между множеством хостов, то хосты эти вынуждены каким-то образом кооперироваться с целью синхронизации их действий в части доступа к данным и метаданным. Сложность в данном случае состоит в том, чтобы, с одной стороны, увеличить производительность и масштабируемость, а с другой — сохранить семантику файловых операций, иначе говоря, распределить каким-то образом локальную файловую систему между множеством серверов, но при этом сохранить последовательными — то есть сериализовать — их действия.
В рамках файловых систем для решения возникающих технических проблем используется несколько подходов. В частности, для преодоления неизбежных при сериализации узких мест используются приемы блокировки, передачи полномочий и разного рода методы кластеризации. Все эти методы сохраняют семантику файловой системы, имеют предел, до которого можно распараллеливать доступ к данным, а также предел распараллеливания доступа к метаданным и обладают теми или иными возможностями распределения оставшихся точек последовательного доступа. Создание системы хранения становится сложной инженерной задачей, поскольку требует найти компромисс в управлении перечисленными свойствами, которые не являются независимыми: усиление одного приводит к ослаблению другого. Итогом такого компромисса являются три класса систем: серверы NAS с ускорителями, а также два вида распределенных файловых систем на базе SAN, централизованные и децентрализованные.
Банальное использование простого NAS-массива чревато двумя проблемами: во-первых, усложняется путь миграции данных; во-вторых, возникает системное «бутылочное горло» в виде доступа к NAS. В современных дисковых массивах эти проблемы решаются. К примеру, в NetApp SpinServer предусмотрен кластер серверов, работающих совместно и обеспечивающих множество точек входа; клиент обращается к устройству через один из серверов, но серверы общаются между собой и создают общую карту размещения файлов, обеспечивающую синхронизацию доступа к файлам, и, таким образом, серверы еще и одновременно выполняют функции коммутаторов. В EMC используют другой подход: серверы HighRoad разделяют компоненты данных и метаданных, один сервер метаданных сериализует операции, выполняемые над метаданными, чем обеспечивается распараллеливание работы с данными, но при этом сам этот север превращается в еще одно узкое место. Производительность системы вступает в зависимость от способности этого сервера обрабатывать мелкие транзакции метаданных.
Транзакционные и высокопроизводительные вычисления предъявляют более высокие требования к доступу к файлам, чем те, которые обеспечивают решения, построенные на основе NAS; в частности, возникает необходимость в блокировке открытых файлов. Один из способов преодоления такого рода сложностей состоит в использовании централизованных файловых систем CXFS (компания SGI) или Shared QFS (Sun Microsystems); централизованными они являются в том смысле, что используют единый сервер метаданных. Существенное различие таких файловых систем от обычных состоит в том, что данные и метаданные хранятся врозь. К примеру, CXFS поддерживает гетерогенную среду, включая Sun Solaris, Linux, Mac OS X, IBM AIX и Windows, а хост, выполняющий функции брокера, который хранит и обрабатывает метаданные, может работать на отдельном сервере под управлением SGI Irix или Linux.
Предложенная IBM файловая система TotalStorage SAN File System, построенная на основе технологии IBM Storage Tank, представляет собой интегрированное аппаратно-программное решение. В SAN File System файлы и файловые системы не управляются индивидуальными компьютерами, а рассматриваются как общий системный ресурс с единым централизованным администрированием. Эта файловая система призвана компенсировать недостатки популярных сетевых файловых систем NFS и CIFS.
Централизация в какой-то мере ограничивает масштабирование, поэтому появляются децентрализованные файловые системы. Кластерная файловая система General Parallel File System (GPFS), разработанная IBM и работающая под управлением ОС AIX или Linux, обеспечивает высокую производительность ввода/вывода благодаря тому, что разносит блоки данных из индивидуальных файлов по разным дискам.
Lustre, также кластерная файловая система, разрабатываемая на принципах Open Source, состоит из четырех функциональных узлов: сервер метаданных, хранящий метаданные, хранилище объектов, где хранятся собственно данные, сервер объектов и клиенты. Lustre используется преимущественно на компьютерах с массовым параллелизмом.

|
| Рис. 2. Архитектура Lustre |
Одноименная объектная система хранения Lustre (рис. 2) разрабатывается компанией Cluster File Systems [2]. В перспективе эта система предназначена для обслуживания кластеров, состоящих из десятков тысяч узлов, и сможет поддерживать скорость обмена данными, измеряемую сотням гигабайтов в секунду. В своей первой версии Lustre 1.0 способна работать с кластером, состоящим из 1000 узлов, и может хранить до 100 Тбайт. Система Lustre строится преимущественно из обычного, имеющегося на рынке оборудования, а ее изюминкой является использование объектных дисков для хранения данных и метаданных. От традиционных систем хранения Lustre отличается специальными компонентами двух типов. Первый компонент — серверы метаданных (Metadata Server, MDS), один из них является основным, другой резервным. Второй компонент — специализированное устройство для управления дисковыми массивами (Distributed Object Storage Target, DOST). Данный модуль является посредником между пользовательскими запросами и реальными физическими устройствами. Этими устройствами могут быть как объектные устройства хранения, так и обычные диски, снабженные специальными драйверами.
Идея Lustre состоит в том, что серверы MDS выполняют функции централизованных хранилищ для идентификаторов объектов, и только. Приложение обращается в MDS лишь для того, чтобы получить соответствующий идентификатор, реальный же доступ к данным по идентификатору осуществляют распределенные модули DOST. Таким образом удается исключить узкие места, поскольку устройства хранения распределены, но в то же время централизованное хранилище метаданных гарантирует целостность данных и возможность для масштабирования.
Контентно-адресуемые системы хранения
Контентно-адресуемые системы хранения (Content Addressed Storage, CAS) также можно отнести к категории объектных систем хранения. (Самый известный образец таких систем — EMC Centera.) От описанных выше систем ObS они существенно отличаются представлением о том, что такое «объект». В иерархии инфраструктуры объектных запоминающих устройств объекты находятся на более низком уровне, чем файлы. И наоборот, в CAS объекты находятся на более высоком уровне, чем файлы. Своими продуктами, попадающими в категорию CAS, помимо первооткрывателя этого сегмента рынка EMC, известны компании Nexsan, Sun Microsystems (StorageTek), Permabit, HP, Bycast, IBM и Avamar. По своей внутренней логике решения всех этих компаний очень схожи, совместимости между ними на данный момент нет, все они относятся к категории «проприетарных».
Все известные системы категории CAS предназначены для надежного хранения редко используемых данных, в тех случаях, когда критичным является снижение стоимости хранения. Однако стоимость не главное: системы CAS позволяют преодолеть недостатки существующих средств архивирования. Ленты являются слишком медленными, они уязвимы с точки возможности зрения потери или даже кражи. Дисковые систем страдают тем, что часто из-за разного рода процедур резервного копирования хранят несколько копий одного и того же файла, и не всегда известно, какая из версий на самом деле является последней. Кроме того, традиционные метаданные, сопровождающие файл во время его жизненного цикла (имя, время создания), не содержат достаточно сведений о самом файле, и это затрудняет его поиск в случае необходимости.
В качестве единиц хранения в CAS вместо файлов, которыми оперирует файловая система, вводятся объекты. Объектам этого типа присваиваются уникальные идентификаторы, что исключает появление клонов и упрощает процедуру поиска, поскольку поиск не связан с конкретным физическим размещением объекта. Если расширить состав метаданных, то при индексировании объектов можно использовать контекст для поиска объектов и т.д. Эта область еще недостаточно исследована, а границы возможного не обозначены. Следует иметь в виду, что данные не попадают в CAS автоматически, решения о том, когда и как передавать данные в CAS, принимаются теми специалистами, которые администрируют системы хранения. С появление этих систем возрастет значение средств, служащих для классификации данных, — ICM (Information Classification Management) и IIM (Intellectual Information Management). Проще говоря, возникает потребность в выполнении работы, аналогичную которой в классических библиотеках выполняют библиографы, т. е. необходимость в появлении «системных библиотекарей».
В основе известных систем CAS лежит использование тех или иных алгоритмов хеширования, когда в соответствие файлу или какой-то иной порции данных ставится вычисленный по контенту идентификатор. В процессе записи можно проверить, не существует ли уже такой идентификатор, и, если таковой есть, значит, в повторной записи нет необходимости. Ключевая роль процесса кэширования в формирования идентификаторов объектов предъявляет высокие требования к алгоритмам кэширования, они должны при любых условиях выработать один и тот же идентификатор для разных объектов, т. е. не допустить так называемой «коллизии кэширования». Выбор используемого алгоритма является специальной задачей, кроме того, используются вспомогательные меры, например, многоуровневое хеширование в пределах одного алгоритма.
Сегодня все компании, уже выпускающие CAS или еще только готовящиеся выйти на этот рынок, используют различные алгоритмы и технологии кэширования, и при имеющейся идеологической близости их системы несовместимы. Поэтому координирующая процессы стандартизации в области сетей хранения организация SNIA готовит новый стандарт XAM (eXtensible Access Method), призванный унифицировать доступ приложений к метаданным. Создание XAM потребует найти общий унифицированный способ для хранения различного рода объектов, в том числе текстов, электронных таблиц и писем, аудиозаписей, изображений совместно с относящимися к ним метаданными. Есть надежда, что создание XAM позволит консолидировать рынок CAS. Известно, что некоторые компании, например, HDS, выражали свое негативное отношение к этой категории систем. Инициатива по созданию XAM стартовала в октябре 2004 года как совместный проект IBM и EMC, а спустя год к ней присоединились HP, HDS и Sun. В перспективе XAM может быть распространен и на неструктурированные данные.
Стандарт XAM важен не только для обеспечения унифицированного доступа к CAS, но и для обеспечения долговременного, на десятилетия, хранения данных. В этом смысле его роль близка к той, которую должен сыграть открытый стандарт на документы ODF (Open Document Format).
Литература
- Mike Mesnier, Gregory Ganger, Erik Riedel, Object-Based Storage. IEEE Communications Magazine, vol. 41, no. 8, August 2003.
- Lustre: A Scalable, High-Performance File System, Cluster File Systems. www.lustre.org/docs/whitepaper.pdf.
«Сторожевой пес» — убийца дисков
Массовое распространение жестких дисков обостряет совершенно неожиданную потребность, потребность в уничтожении их содержимого, причем таким образом, чтобы его нельзя было восстановить. Необходимо производить некое подобие машин для резки бумажных документов, в массовом порядке используемых в офисах. Ученые из Технологического исследовательского института штата Джорджия разработали установку GuardDog («сторожевой пес»), способную мощным магнитным полем делать диски непригодными для дальнейшего использования в течение нескольких секунд. В GuardDog применен постоянный магнит весом около 50 килограммов; он создает поле, сравнимое с тем, которое возникает в магниторезонансных приборах, поэтому в сравнении с известными устройствами для стирания дисков он обладает более высокой производительностью. Диски могут проходить через него на конвейере, сильнейшее магнитное поле приводит все магнитные домены в случайное состояние, и информация уничтожается. Поле настолько сильно, что делает неработоспособными и все механизмы сервоприводов и головки. Таким образом, оставаясь внешне невредимым, диск физически уничтожается. Анализ показывает, что на диске не остается следов записанных на нем данных.
Основным заказчиком на GuardDog являются военные, но в условиях роста объемов накопленных данных, а следовательно, и списываемых дисков, установка найдет себе применение в других сферах, например таких, как кредитно-финансовые организации и им подобные. На пути распространения подобных «дисковых убийц» есть одно препятствие — использование дисков с криптографии, использование криптографического измельчения (crypto shredding) может оказаться не менее эффективной процедурой.
Кто-то теряет, а кто-то находит
Если данные сохраняются, то есть вероятность того, что в каких-то случаях они будут утрачены. В расчете именно на эту вероятность строит свою деятельность компания Ontrack, входящая с 2002 года в состав консалтингового холдинга Kroll, специализирующегося на оценке рисков. Деятельность Ontrack делится на две составляющие — поставка семейства программных продуктов Ontrack EasyRecovery и сервисная служба, лаборатории которой осуществляют восстановление данных на носителях, получивших физические или логические повреждения. В нынешнем году подобная, семнадцатая по счету лаборатория, где главным образом лечат диски, открылась в Москве; это дает основание Ontrack называть себя «Всемирной высокотехнологической клиникой».
Статистика показывает, что в подавляющем большинстве случае данные теряются из-за ошибок пользователей (32%), износа оборудования и ненадлежащей эксплуатации (42%). На вирусы, стихийных бедствия и саботаж, т. е. на причины, о которых говорят гораздо больше, приходится всего лишь несколько процентов. Вероятность восстановления потерянных данных в лабораториях Ontrack превышает 90%, но стоимость услуги достаточно велика. Скажем, стоимость восстановления данных с «убитого» ноутбука примерно равна стоимости этого компьютера, поэтому огромное значение имеет профилактика. По отзывам клиентов, основным злом являются персональные компьютеры на рабочих местах, именно на них приходится подавляющая часть потерянных данных. Очевидно, радикальным средством для излечения от этой заразы могут быть тонкие клиенты, но в реальных условиях на рабочих местах стоят и еще долго будут стоять ПК, помочь им могут средства для разумного администрирования.
В бывшем СССР имя компании Ontrack стало особенно популярно, когда была в ходу так называемая «московская конфигурация» PC AT (Intel 80286/80287, 12 МГц, «косые флопы», память 1 Мбайт, диск 40 Мбайт). Хотя сам компьютер поддерживал 14 различных типов дисков емкостью от 10 до 112 Мбайт, операционная система DOS до версии 4.0 не могла работать с разделами более 32 Мбайт (16-разрядный адрес ограничивал число секторов числом 65536). Проблему можно было решать, вводя «диски» D:, E: и т.д. или используя специализированные менеджеры дисков; среди них самым популярным был ontrack disk manager. Его называли именно так, забывая о том, кто создал это средство. Между тем у него были авторы — Майкл Роджерс, Джон Пенс и Гари Стивенс, основавшие в 1985 году компанию Ontrack. В 1998 году Ontrack приобрела компанию EasyRecovery, продукт которой можно использовать самостоятельно или дистанционно в лаборатории компании посредством Ontrack Remote Data Recovery.
