Компания Ifostoria предложила очень интересные программные продукты: они нацелены скорее на работу с информацией, чем с данными.
Программные решения Infostoria Content Integrator и Infostoria Workgroups, созданные начинающей компанией Infostoria, стали, безусловно, новым словом в области средств интеграции контента предприятия (Enterprise Content Integration, ECI). Не будет преувеличением отнести их к следующему поколению инструментальных средств интеграции. Основываясь на предложенной Биллом Инмоном, «отцом» хранилищ данных, формуле «информация = данные + метаданные», подчеркнем: в отличие от конкурирующих продуктов, продукты Infostoria способны работать именно с информацией, а не с данными.
Несомненно, и сама компания Ifostoria заслуживает внимания. Создал ее наш соотечественник Дмитрий Черевик, который несколько лет назад занимал должность директора по Web-сервисам в корпорации Computer Associates и инициировал в ней внедрение программных решений на основе сервисных подходов. Об эффективности интеграционных решений Infostoria судить рано, ведь компания была организована менее двух лет назад и сейчас лишь пробивается на рынок. Однако, если верить доступным публикациям, производственная программа Infostoria весьма логична, а в ее разработках прослеживается стержневая идея, придающая «необщее выражение» лицу компании. По маркетинговым или каким-то иным причинам эта самобытная идея нигде не прописана в явной форме, но ее суть находится буквально на поверхности.
Особенность подхода Ifostoria к интеграции состоит в акценте на метаданных. Средства Infostoria Content Integrator автоматически или с участием человека извлекают метаданные из «сырых» данных и размещают их в соответствующих каталогах. В последующем эти метаданные служат для интеграции контента. При работе с контентом Infostoria Content Integrator можно использовать совместно с продуктами компаний Microsoft, IBM, Oracle, EMC/Documentum, Interwoven, Hummingbird и других производителей.
|
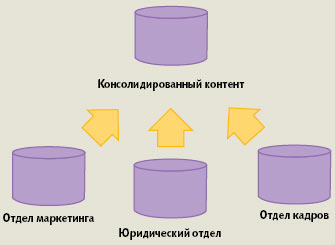
| Рис. 1. Консолидация контента |
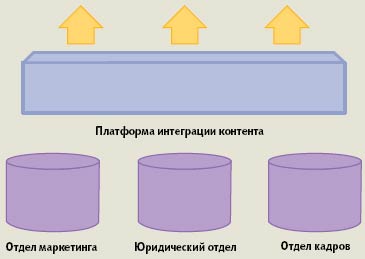
Решения Infostoria реализуют два альтернативных способа интеграции контента предприятия: простая консолидация и виртуальная интеграция. В первом случае весь контент собирается в одном хранилище, репозитории (рис. 1), а во втором — виртуализируется, оставаясь «на своем месте» (рис. 2).
Консолидация, под которой подразумевается создание общего репозитория для всех видов корпоративных данных, дает преимущества, свойственные любому централизованному решению. В данном случае организуется единая система хранения с унифицированными правилами управления, обслуживания и обеспечения безопасности. Но у любого централизованного подхода есть и «слабое место»: он хорошо соответствует однородным средам и гораздо хуже — разнородным. Поэтому при интеграции контента предприятия следует учитывать, что он разнороден, состоит из всевозможных текстовых документов, графики и мультимедийных файлов. И «упаковка в одну корзину» разнородных данных, к тому же принадлежащих подразделениям с разной функциональностью, может оказаться не слишком удачной затеей.
|
| Рис. 2. Интеграция контента |
В ряде случаев лучше сохранить разделение данных по физическим хранилищам, но объединить их на логическом уровне. Такое решение называют виртуальной интеграцией. Средства виртуализации позволяют представить все множество репозиториев в виде единого образа. Подходы на основе консолидации и виртуализации не являются альтернативными: в реальной жизни может возникнуть потребность в объединяющем их компромиссном решении.
Для поддержки консолидационных, виртуализационных и смешанных решений, предназначенных для интеграции контента предприятия, компания Infostoria и создала платформу Infostoria Integration Platform. Она позволяет, работая в режиме реального времени, синхронизировать разрозненные репозитории или объединять в одном хранилище структурированные неструктурированные данные. На внешнем уровне эту платформу можно представить как совокупность каталога контента и интеграционных агентов (рис. 3).
Агенты устанавливаются на системах, хранящих репозитории, а их задача заключается в сканировании репозиториев и передаче сведений о данных в каталог контента. Они обслуживают и централизованный, и распределенные репозитории. Агенты состоят из ряда компонентов.
- Средства для работы в реальном времени. Обеспечивают обработку событий, управление конфигурацией, резервирование ресурсов и используются всеми остальными компонентами агентов.
- Коннекторы — программные модули, поддерживающие доступ к репозиториями. Предоставляют информацию и обеспечивают те типы действий, которые допустимы для данного информационного ресурса.
- Механизмы отображения данных — части агентов, управление которыми осуществляется с помощью заданного набора правил. Служат для отображения в централизованных репозиториях форматов и схем данных, используемых в индивидуальных ресурсах.
- Механизм синхронизации — обеспечивает согласование данных в каталоге контента и в репозиторие, контролируемом конкретным агентом. Обеспечиваются механизмы синхронизации двух типов: общий (bulk) используется при первоначальной загрузке, а инкрементальный (incremental) — в течение жизни информационного ресурса. В отличие традиционных процессов выборки, преобразования и загрузки (extact, transfer, load, ETL), реализуемых в хранилищах данных, механизм синхронизации действует в соответствии с событиями, возникающими при создании, модификации и удалении ресурса.
- Драйверы контента — программные модули, которые динамически загружаются агентом для работы с неструктурированными данными определенного типа. Служат для выделения из данных метаданных (например, имена авторов или ключевые слова) и создания текстовых индексов документов. Метаданные и индекс пересылаются в каталог контента, после чего они поддерживают доступ к данным.
- Система поддержки Web-сервисов. Включает облегченный Web-сервер и машину для работы SOAP/XML, которые обеспечивают доступ к данным и операциям, контролируемым данным агентом.
- Механизм защиты. Позволяет проводить аутентификацию пользователей и приложений в распределенной среде Infostoria Integration Platform.
Обычно агент разрабатывается на языке, близком к той программной платформе, на которой он будет работать. Infostoria предлагает решения для платформы .Net и Java-агенты для операционных систем Linux и Solaris.
Каталог контента Infostoria Content Directory содержит консолидированные сведения баз данных предприятия, порталов и систем управления контентом. Помимо обычных записей в СУБД объектами хранения могут быть документы и все, что попадает под определение rich media content (то есть изображения, аудио- и видеофайлы и т.п.). Каталог состоит из следующих компонентов.
- Репозиторий контента представляет собой область внешней памяти, в которой хранится консолидированный неструктурированный контент (в том числе данные, расположенные в дисковых массивах, на подключаемых к сети устройствах хранения и в сетях хранения). Объемы данных могут измеряться терабайтами.
- Репозиторий метаданных строится на основании реляционной СУБД и хранит структурированные данные и метаданные, описывающие централизованный или децентрализованный контент. Его содержимое синхронизируется с содержимым исходных репозиториев.
- Менеджер событий отвечает за передачу сведений от агентов в каталог контента. Он действует и в качестве брокера, позволяющего подписываться на получение сведений о событиях.
- Механизм контроля над безопасностью доступа обеспечивает подключение Infostoria Integration Platform к корпоративной информационной системе, реализует политики безопасности на уровне метаданных.
- Механизм корпоративного поиска представляет собой обычную поисковую машину.
- Механизм обработки событий обеспечивает соответствие индекса содержимому репозиториев.
- Библиотека сервисов содержит все инструменты, необходимые для работы с данными и метаданными.
- Медийные сервисы обеспечивают работу с медийными файлами.
- Интерфейсы каталога контента объединяют в себе набор интерфейсов на основе Web-технологий и Java, используемых для доступа в каталог контента.
Infostoria Content Integrator работает следующим образом. Если агент Infostoria обнаруживает новый документ, он пытается его разобрать и выделить содержательные метаданные. В данном случае термин «разобрать» (parse) обозначает нечто схожее с процедурами лексического и синтаксического разбора в процессе компиляции программы. В текстовом документе могут быть обнаружены имя автора, название документа, ключевые слова, резюме и другие атрибуты, которые используются как метаданные. Для мультимедийного документа создается «заменитель» (например, характеризуемый низким разрешение или имеющий меньший объем), который тоже становится элементом метаданных. Достаточно просто создаются пиктограммы для статических изображений, видеоряд сокращается до нескольких ключевых кадров, а сложнее всего дело обстоит с аудиофайлами.
Итак, агент извлекает метаданные и «замени?тели», которые размещаются в каталоге контента. На этом заканчивается первая, автоматическая часть процесса, обеспечивающего введение документа в интегрированный контент. В принципе, этого достаточно для организации доступа на основе контента, но процесс публикации можно продолжить «вручную» — для уточнения метаданных и совершенствования «заменителей».
Infostoria предлагает и программный продукт Infostoria Workgroups, созданный на основе Infostoria Content Integrator и Web-технологий и предназначенный для организации групповой работы. Отличие Infostoria Workgroups от известных аналогов состоит в том, что необходимость в загрузке всех данных на один центральный сервер исключена: благодаря использованию механизма виртуализации их допустимо оставлять на компьютерах членов группы. В результате пользователи могут взаимодействовать в стиле «каждый с каждым» (peer-to-peer), получать все преимущества групповой работы и более эффективно задействовать локальные вычислительные ресурсы на рабочих местах. Обычно групповая работа подразумевает, что пользователи публикуют свои документы в общем репозитории. Infostoria Workgroups тоже предоставляет такую возможность; ее реализация вполне разумна, если только документы не слишком велики по объему и часто используются при совместной работе. Если же данные остаются на персональных компьютерах (по терминологии Infostoria — во внешних репозиториях), то публикацию и доступность информации обеспечивают агенты, размещенные на тех же ПК.
Агент сканирует внешний репозиторий, выделяет в нем метаданные и посылает их в групповое хранилище. Там вступает в действие другой агент, ответственный за синхронизацию с контентом внешних репозиториев. Если документ создается, модифицируется или удаляется из внешнего репозитория, эта пара агентов обеспечивает адекватные изменения в групповом репозитории. После того как метаданные переданы группе, они индексируются, аннотируются и подвергаются другим дополнительным операциям, причем не имеет значения физическое расположение данных. В результате поддерживается прозрачность доступа к информации вне зависимости от ее местонахождения: если запрошенный документ находится во внешнем репозитории, пользователь получает его точно так же, как если бы он хранился в центральном репозитории.
Механизм использования внешних репозиториев, реализованный в Infostoria Workgroups с помощью средств SOA, очень похож на подход, применяемый в одноранговых сетях (peer-to-peer, P2P). В них пользователи абсолютно равноправны, поэтому их и называют peer («равный»). Как следствие, центральный сервер группы перестает быть критически важным узлом, а агенты играют роль «уравнителей» членов группы. Документы могут храниться где угодно — на настольных компьютерах, ноутбуках, серверах подразделений и т.п. Кроме того, этот способ организации групповой работы близок к таким современным формам обмена информацией, как блоги и wiki.
