
Развитие многоядерных систем – это путь к повсеместному использованию параллельных вычислений. Как известно, наиболее распространенным способом повышения производительности является именно распараллеливание потока команд или потока данных. Распараллеливание данных – это применение одной операции сразу к нескольким элементам массива данных. Параллелизм задач предусматривает разбиение вычислительного процесса на несколько подзадач (процессов, потоков), каждая из которых выполняется на своем ядре (процессоре). Многоядерные системы относят к классу MIMD (Multiple Instruction, Multiple Data). В них несколько программных ветвей выполняются одновременно и независимо, но в определенные моменты они обмениваются данными.
Активное внедрение многоядерных систем подразумевает существенное изменение стиля программирования: разработчики будут вынуждены использовать параллельные потоки, порождение и обработку асинхронных событий и др. Иными словами, новая аппаратная архитектура требует смены программной парадигмы – перехода от последовательного стиля программирования к параллельному.
Закон Амдала
Многоядерный процессор – это многопроцессорная система, реализованная на кристалле, обеспечивающая повышение эффективности работы вычислительной системы в целом. Закон Амдала гласит, что прирост производительности (S) системы зависит от количества процессоров (N) и доли последовательных операций (c) в программе:
Sn=1/(с+(1-с)/N)
Граничные значения c соответствуют полностью параллельным (c=0) и полностью последовательным (c=1) программам. Если лишь 1/10 часть программы выполняется последовательно, то в принципе невозможно ускорение в десять раз – вне зависимости от числа используемых процессоров (ядер). Важное следствие закона Амдала состоит в том, что максимальный рост производительности (в N раз при N процессорах) недостижим. В противном случае последовательно исполняемая часть программы должна быть равна нулю, что невозможно. Еще одно следствие закона таково: чем меньше доля последовательно исполняемой части программы, тем больше прирост производительности (рис. 1).
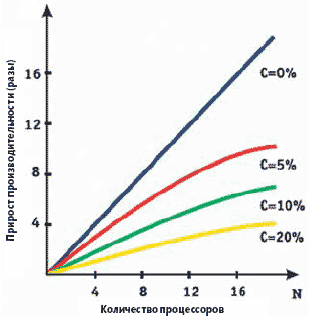 |
| Рис. 1. Следствия закона Амдала |
Сегодня только небольшая часть программного обеспечения может выполняться на многоядерных процессорах, что подтверждают результаты тестов – синтетических и предназначенных для конкретных классов приложений (см., например, www.3dnews.ru/cpu/dualcore-cpu/index03.htm). Реальный рост производительности дают лишь программы, оптимизированные под многопоточность, такие как Adobe Premiere Pro 1.5 и 3DMax. Очень важны разработка и внедрение драйверов устройств, поддерживающих многопоточность.
Особенности перехода к параллельным вычислениям
При переходе с одноядерных процессоров на многоядерные приходится принимать во внимание проблему последовательного выполнения. Что это означает применительно к многоядерной системе? В ней выполнение считается последовательным, если в какой-то момент одно или более ядер не могут выполнять код одновременно с другими ядрами. Такая ситуация может возникнуть по разным причинам [1]: блокировка при доступе к ресурсам, необходимость синхронизации процессов или потоков на ядрах, поддержка когерентности кэш-памяти, неравномерность загрузки.
Блокировки возникают из-за невозможности (например, в момент «сбора мусора») одновременного доступа приложений на разных ядрах к жесткому диску, к устройствам ввода/вывода или данным приложений. Очень часто параллельные процессы, выполняемые на разных ядрах, нужно синхронизировать в определенные моменты. Например, приложение на одном из ядер должно использовать промежуточные данные, которые получает приложение (поток, процесс) на другом ядре. Первое приложение не может продолжить работу до получения этих данных, то есть находится в состоянии ожидания. В такой ситуации неизбежны накладные расходы на синхронизацию приложений (процессов, потоков), выполняемых на разных ядрах. В свою очередь, это обусловливает снижение эффективности параллельной работы, что находит отражение в сетевом законе Амдала. Возникает необходимость в поддержке когерентности (согласованности) кэш-памяти для всех ядер при использовании разделяемой памяти.
Можно упомянуть об исследованиях Intel, посвященных динамическому регулированию интенсивности выполнения инструкций (energy per instruction, EPI) в зависимости от степени параллелизма реализации программного обеспечения [2]. Специалисты корпорации опытным путем показали эффективность регулирования тактовой частоты асимметричной многопроцессорной системы в зависимости от активности вычислительных ядер.
Инструментальные средства многоядерных систем
Компиляторы
Чтобы получить максимальную выгоду от использования многоядерной архитектуры требуется поддержка на уровне компилятора. Так, в 2005 году Intel выпустила версию 9.0 компилятора языков C++ и Фортран для платформ Linux и Windows. Этот компилятор позволяет эффективно использовать возможности технологии Hyper-Threading и многоядерных процессоров. Он поддерживает возможность автопараллелизма, то есть автоматического обнаружения в приложениях возможности создания множества параллельных потоков с поддержкой спецификации OpenMP 2.5.
Благодаря поддержке стандарта OpenMP компилятор Microsoft Visual C++ 2005 обеспечивает параллельную многопоточную обработку. Для этого требуется либо указать параметр компилятора «/openmp», либо установить в конфигурации флаг «OpenMP Support». С ноября 2005 года компилятор gcc для языков Cи, C++ и Фортран 95 поддерживает OpenMP с помощью опции «-fopenmp». Следует упомянуть и набор компиляторов EKOPath компании PathScale, предназначенных для 64-разрядных систем на базе Linux (AMD64 и EM64T).
Программные отладчики
Программисты хорошо знают, как трудно отлаживать многопоточные приложения. При аварийном завершении программы зачастую требуется проанализировать стек вызовов функций во всех потоках, но обычный отладчик показывает только стек потока, на котором произошло аварийное завершение программы. Например, стандартные средства gdb плохо приспособлены для отладки многопоточных приложений, поэтому предлагаются специальные версии этого отладчика для конкретных операционных систем: в их ядра включаются дополнительные возможности отладки многопоточных приложений.
Одна из таких реализаций – отладчик компании Etnus TotalView, предназначенный для платформ Linux, Unix и LynxOS. Он поддерживает многопоточность, MPI, OpenMP, языки программирования Cи/C++ и Фортран, а также смешанные коды с использованием разных языков программирования. Полезным средством оптимизации и отладки параллельных программ является пакет Intel Threading Tools. Он обеспечивает диагностику ошибок и анализ производительности многопоточных приложений, использующих модели потоков Win32 и OpenMP. Отладчик позволяет обнаруживать взаимные блокировки (deadlock) и гонки (race condition) между потоками, локализовать проблемы на уровне исходного кода, анализировать эффективность способов повышения производительности OpenMP-программ.
Аппаратные отладчики
Для работы с виртуальными машинами аппаратный отладчик должен поддерживать ряд специальных функций (в частности, определять, к какой виртуальной машине относятся те или иные процессы и нити). Их обеспечивает, например, TRACE32 компании Lauterbach. Благодаря полной поддержке встроенных аппаратных блоков управления памятью можно одновременно отлаживать процессы на нескольких виртуальных машинах и даже два варианта одного процесса на разных виртуальных машинах. В частности, Lauterbach обюявила о выпуске программного инструментария интегрированной поддержки ядра (kernel awareness) для операционной системы LynxOS-178. Чтобы получить доступ ко всем функциями TRACE32, не нужно изменять прикладные программы или ядро (применять заплаты, перехватчики, инструментальные «довески» и др.). Отлаживается именно то приложение, которое будет действовать в конечном продукте, что очень важно для его сертификации.
Среди других аппаратных отладчиков, поддерживающих работу с многоядерными конфигурациями, назовем Green Hills Probe и SuperTrace компании Green Hills, WindPower ICE компании Wind River, RealView ICE от ARM.
Стандарты многоядерных систем
При разработке параллельных программ используются специализированные библиотеки и системы параллельного программирования PVM, LAM, CHMP и др. Три основных подхода к реализации этих систем различаются методами взаимодействия параллельных задач. Первый подход базируется на концепции обмена сообщениями, второй – на использовании разделяемой памяти, третий опирается на стандарт POSIX и обюединяет эти два подхода.
Наиболее известным представителем первой группы является спецификация MPI (Message Passing Interface) для языков Cи и Фортран, первый вариант которой появился в 1994 году. MPI обеспечивает примерно 200 функций, охватывает множество компиляторов и операционных систем. Среди наиболее распространенных ее реализаций – библиотека MPICH. Кроме того, предлагаются несколько коммерческих реализаций MPI, например MPI/Pro компании Verari Systems Software. MPI/Pro оптимизирует время работы параллельных приложений и поддерживает их масштабируемость за счет балансировки параметров производительности и использования ресурсов. Verari предлагает версии MPI/Pro для разных операционных систем, в том числе Windows, Linux, Mac OS X, LynxOS, и таких коммуникационных сред, как Gigabit Ethernet, Myrinet и InfiniBand.
Ко второй группе относится спецификация OpenMP (Open specifications for Multi-Processing). Ее первая версия (www.openmp.org), которая была выпущена в 1997 году, предназначалась для языка Фортран. К появлению OpenMP «приложили руку» компании IBM, Intel, Sun Microsystems и Hewlett-Packard. В 1998 году были созданы варианты OpenMP для языков Cи/C++, а последней является версия 2.5. Поддержка спецификации OpenMP обеспечена во всех компиляторах Intel начиная с шестой версии, в Microsoft Cи/C++ начиная с Visual Studio 2005, а также в GCC.
OpenMP – это набор специальных директив компилятору (pragma), библиотечных функций и переменных среды. Наиболее оригинальны директивы компилятору, которые используются для обозначения областей в коде и могут выполняться параллельно. Компилятор, поддерживающий OpenMP, преобразует исходный код и вставляет соответствующие вызовы функций для параллельного выполнения этих областей кода.
В третью группу входит спецификация POSIX (Portable Operating System interface for unIX), первое описание которой было опубликовано в 1986 году (www.pasc.org). Основная спецификация разработана как IEEE 1003.1 и одобрена как международный стандарт ISO/IEC 9945-1:1990. С точки зрения организации параллельных вычислений наибольший интерес представляют три части стандарта – 1003.1a (OS Definition), 1003.1b (Realtime Extensions) и 1003.1c (Threads). В рамках POSIX можно реализовать параллельные вычисления на основе обмена сообщениями (аналогично MPI) или разделяемой памяти (как в OpenMP). Естественно, в POSIX допустима и любая комбинация этих методов. В наибольшей степени стандарту POSIX соответствуют (и соответствующим образом сертифицированы) операционные системы реального времени LynxOS и Integrity.
Поддержка на уровне ОС
Многоядерные процессоры потребуют от операционных систем поддержки разных архитектур многопроцессорной обработки. Компания QNX Software Systems обюявила о выпуске комплекта разработчика QNX Momentics Multi-Core Edition. Этот набор инструментов предназначен для создания программного обеспечения и его миграции на многоядерные аппаратные решения нового поколения, в том числе процессоры BCM12xx и BCM14xx компании Broadcom, процессор MPC8641D компании Freescale и многоядерные процессоры Intel. Будут поддерживаться несколько моделей многопроцессорности для многоядерных архитектур: асимметричная AMP (обеспечение полного управления и отказоустойчивости); симметричная SMP (максимальные параллелизм и масштабируемость); «исключительная» BMP (поддержка миграции кода и снижение сложности разработки).
Поддержку многоядерных систем на базе процессоров AMD64, Sun UltraSPARC T1 и Intel обеспечивает ОС Solaris 10. Например, встроенная система виртуализации и защиты информации Solaris Containers позволяет системному администратору организовывать в рамках единой операционной системы несколько виртуальных системных разделов – «зон». Каждой зоне допустимо назначить свой контейнер – набор локализованных системных ресурсов. Контейнеры могут служить основой для управления ресурсами на уровне ядер. Реализованные в Solaris 10 функции так называемого «прогнозируемого самовосстановления» (Predictive Self-Healing) обеспечивают автоматическое определение сбоев в работе ядер и их перевод в пассивный режим без влияния на работу остальных ядер процессора. Поддержка многоядерных систем реализована в некоторых дистрибутивах ОС Linux, например Red Hat Enterprise Linux 4.
Многоуровневая виртуализация
Появление многоядерных процессоров даст мощный дополнительный толчок массовому внедрению технологий виртуализации. Назовем некоторые из известных подходов.
ARINC-653 (Avionics Application Software Standard Interface). Стандартный интерфейс, разработанный компанией ARINC в 1997 году, вводит концепцию изолированных разделов на основе универсального программного интерфейса APEX (Application/Executive) между операционной системой и прикладным программным обеспечением. Требования интерфейса определены так, чтобы разрешить приложениям контролировать диспетчеризацию, связь и состояние внутренних обрабатываемых элементов.
В 2003 году принята новая редакция ARINC-653, в которой введена концепция изолированных виртуальных машин (разделов, рис. 2). Ее особенностью является жесткое и заранее определенное квантование времени между виртуальными машинами, а целью – обеспечение гарантий того, что не возникнут общие отказы системы. Стандарт ARINC-653 реализован для операционных систем реального времени LynxOS-178, VxWorks, Integrity, CsLeos и др.

Рис. 2. Концепция изолированных виртуальных машин
User-Mode Linux. UML – ОС Linux в пользовательском режиме самый универсальный эмулятор, позволяющий создавать виртуальное оборудование, которого может и не быть на физическом компьютере. Это весьма удобно для тестирования конфигураций аппаратного обеспечения. UML состоит из набора заплат к ядру Linux, которые позволяют запускать другие операционные системы в консольных окнах, и каждый пользователь может независимо загружать сколько угодно операционных и оконных систем, вплоть до X11. User-Mode Linux допускается применять для устройств с архитектурой IA-32 и PowerPC G5.
Программные среды виртуальных машин. Наиболее популярными из них являются Microsoft Virtual PC и группа программных продуктов VMware. Система виртуальных машин позволяет запускать на компьютере сразу несколько разных операционных систем и переключаться с одной на другую без перезапуска компьютера. На компьютере, работающем под управлением основной (базовой) операционной системы, создаются один или несколько виртуальных компьютеров, на каждом из которых можно запустить «гостевую» ОС.
VMWare Workstation позволяет запустить несколько экземпляров Windows, Linux и NetWare. Реализованы полноценная поддержка сети, переносимость окружений и гибкий подход к работе с окружением. Проект Virtual PC изначально разрабатывала компания Connectix, но в начале 2003 года его купила корпорация Microsoft. К сожалению, после этого Virtual PC лишился поддержки «гостевых» Unix-подобных систем (в том числе, Linux) и был полностью ориентирован на установку Windows-cистем на других платформах.
Технология виртуализации Intel. VT, компонент многоядерной технологии поддержки виртуализации на аппаратном уровне [3], обеспечивает поддержку виртуальных машин на уровне процессора с помощью нового режима VMX (Virtual Machine Extensions) и десяти команд – vmptrld, vmptrst, vmclear, vmread, vmwrite, vmcall, vmlauch, vmresume, vmxoff и vmxon. При этом повышаются как надежность и производительность работы приложений, так и уровень общей безопасности.
Архитектура VT поддерживает два класса ПО: монитор виртуальной машины VMM и «гостевое» программное обеспечение. Используются два режима работы – root operation и non-root operation. Как правило, VMM работает в первом режиме, а «гостевые» программы – во втором. Поддержку технологии виртуализации Intel намерены организовать такие производители операционных систем, как RedHat, SuSe и MontaVista. Она будет обеспечена и в других программных средствах виртуализации, например в VMware.
Проблемы лицензирования
Появление многоядерных процессоров вызвало опасения, что пользователям придется платить гораздо больше (пропорционально числу ядер) за лицензии на программное обеспечение. В частности, до недавнего времени такую позицию занимала корпорация Oracle. Недавно произошли позитивные изменения: стоимость лицензий на продукты Oracle для многоядерных процессоров AMD и Intel начали рассчитывать путем умножения числа ядер на коэффициент 0,5, для микропроцессоров UltraSPARC T1 – на 0,25, а для многоядерных процессоров других производителей (в том числе, IBM) – на 0,75. При лицензировании своих программных продуктов IBM считает двухюядерные процессоры AMD и Intel одним процессором, но продолжает рассматривать каждое ядро процессоров POWER как отдельный процессор.
Ассоциация Multicore
Понимая сложность задач массового перехода на многоядерные решения, основные поставщики аппаратных и программных средств организовали ассоциацию Multicore (www.multicore-association.org). Ее цель – создание промышленных стандартов для многоядерных систем. Сейчас Multicore работает над четырьмя самостоятельными, но взаимосвязанными стандартами – Resource Management (RAPI), Communication API (CAPI), Debug API и Transparent interprocess communication (TIPC). В рабочих встречах принимают участие представители компаний Xilinx, Express Logic, Wind River, Freescale, ARC, MIPS Technologies, Synopsys и PolyCore Software.
Несомненно, распространение многоядерных процессоров будет зависеть от реализации соответствующего программного обеспечения. Если она окажется эффективной, существенно вырастет инсталляционная база многоядерных систем.
- Todd Brian, Putting multicore processing in context: Part one. Embedded.com, February 2006.
- Murali Annavaram, Ed Grochowski, John Shen, Mitigating Amdahl's Law Through EPI Throttling, SCA-32. June 2005, www.princeton.edu/~jdonald/research/cmp/ annavaram_mitigating.pdf.
- Narendar Sahgal, Dion Rodgers, Understanding Intel Virtualization Technology. download.microsoft.com/download/9/8/f/ 98f3fe47-dfc3-4e74-92a3-088782200fe7/TWAR05015_WinHEC05.ppt.
Сергей Золотарев (zolotarev@rtsoft.ru), Алексей Рыбаков (pr@rtsoft.ru)– сотрудники компании «РТСофт» (Москва).
Согласованное программирование
Совпадение по форме русского слова «конкуренция» и английского concurrency сегодня оказалось крайне неудобным обстоятельством. В момент, когда технологическое направление concurrent programming стало одним из приоритетных, его нечем адекватно назвать. В отличие от «конкуренции», в английском языке основные значения concurrency& – «согласованность», «совпадение во мнении» или даже «соглашение» – не предполагают никакого конфликта, а, совсем наоборот, означают кооперированное взаимодействие. В компьютерной науке под concurrency понимают такое свойство системы, которое позволяет ей распределить общие ресурсы между отдельными вычисленными процессами, накладывающимися друг на друга во времени. Исходя из этого в данном контексте для перевода concurrent programming целесообразно использовать термины «согласование» и «согласованное программирование». Согласованное программирование включает в себя языки и алгоритмы, необходимые для реализации согласованных систем. Более известное параллельное программирование для высокопроизводительных вычислений является частным случаем согласованного программирования.
На академическом уровне проблемами согласованного программирования серьезные исследователи стали заниматься давно и серьезно, еще в конце 60-х годов, наиболее примечательные и фундаментальные работы великого голландца Эдсгера Дейкстры (1930-2002) датируются 1968-м и 1971 годами. Примерно в то же время Карл Петри создал свою теорию сетей, названную его именем.
Но с тех пор ничего более серьезного в области согласованного программирования сделано не было, и это далеко не случайно. Как ни парадоксально, но за прошедшие три-четыре десятилетия практическое программирование достигло больших высот, однако и потеряло немало. В какой-то степени можно даже говорить о частичной деградации: утеряна общая гуманитарная культура, сопутствовавшая программированию в первые десятилетия становления отрасли. Трудно поверить, но в 60-е годы обычных программистов интересовали, например, вопросы структурной лингвистики, они читали работы Ноама Хомского. Если сравнить книги, что тиражами в десятки тысяч экземпляров издавались (необходимо также учесть общее количество компьютеров) и мгновенно раскупались в те годы, с тем, что стоит на полках магазинов сегодня, нетрудно «почувствовать разницу». Причина интеллектуальной стагнации заключается в том, что экспоненциальный рост производительности процессоров сделал ненужными программистские изыски.
Но жизнь устроена так, что за все приходится платить – в том числе за экстенсивное развитие технологии без должного научного, равно как и философско-мировоззренческого обеспечения. Подтверждая это, ведущий эксперт корпорации Microsoft Херб Саттер опубликовал статью «Бесплатный ланч закончился. Фундаментальный поворот по направлению к согласованному программному обеспечению» (Dr. Dobb's Journal, March 2005). На русский язык общий рефрен статьи можно перевести просто: «Конец халяве». Таким образом, даже представитель корпорации, получившей наибольшую выгоду от парадигмы Wintel, существовавшей с 80-х под лозунгом: «Энди (Гроув, Intel) дает, а Билл (Гейтс, Microsift) забирает», признал, что парадигма эта приказала долго жить. Ресурсы трех слонов, на которых стояла вся индустрия, оказались исчерпанными. Тактовая частота не растет; оптимизация исполнения в пределах одного ядра достигла предела, за которым рост сложности становится неоправдан; у дальнейшего наращивания размеров кэш-памяти процессоров остался лишь небольшой зазор для развития. Как следствие, старый добрый мир остался в прошлом; единственным перспективным направлением для дальнейшего развития оказались многоядерные и многопотоковые процессоры.
Метаморфозы в компьютерной отрасли начали происходить на удивление быстро. Ничто не предвещало их еще в начале 2005 года, но уже к его концу многоядерные процессоры стали главными элементами производственных программ ведущих компанийб-разработчиков микропроцессоров.
А что же программирование? Как создавать программы в новом, еще не познанном мире многоядерных процессоров? Сейчас на кристалле их более дюжины, но компания Intel обещает увеличить это число до ста, старая парадигма программирования в этом мире не работает. Тот же Саттер, но уже в статье «Программное обеспечение и революция согласования» (ACM QUEUE, September 2005) называет происходящее революцией по масштабам существенно более мощной, чем распространение обюектно-ориентированного программирования в начале 90-е годов. Тогда причиной перемен стало усложнение программных систем, нынешняя же революционная ситуация вызвана необходимостью выполнять программы на многоядерных и многопотоковых процессорах.
«Послереволюционное» программное обеспечение должно обладать следующими характерными свойствами.
- Для того чтобы использовать ресурсы многопотоковых и многоядерных процессоров, программное обеспечение должно быть по своей природе способным к «согласованию». Понятно, что есть нераспараллеливаемые процессы (их существование обычно характеризуют как «проблему человеческого эмбриона»: девять женщин не могут выносить ребенка за месяц). Однако в современных условиях центров обработки данных задача не состоит в том, чтобы заставить выполнить работу раньше срока, а в том, чтобы в заданный срок сделать как можно больше; в проекции на проблематику воспроизводства населения это означает необходимость максимального увеличения рождаемости.
- Задачи должны стать более адаптированными к использованию ресурсов процессорного ядра, то есть использовать больше времени на полезную работу и меньше на прерывания (это свойство принято обозначать термином CPU-bound, от boundary – «граница», «поверхность соприкосновения»).
- Нужны новые языки программирования, приспособленные к проблемам согласования.
Леонид Черняк
