Примером инструмента для построения баз данных и приложений, который призван повысить удобство проектирования и эксплуатации баз данных, может служить qWORD-XML.

В 70-е годы реляционная модель данных возникла как ответ на потребность в простой СУБД, соответствующей уровню развития компьютерной технологии своего времени. Сегодня гораздо важнее удобство проектирования и эксплуатации баз данных, а то, что когда-то казалось простым, математически строгим и логичным, стало восприниматься как неудобное. Инструментарий qWORD-XML разработки компании СП. АРМ служит для построения как оперативных, так и аналитических систем, совмещая в себе средства для построения и применения баз данных.
Семантическое расширение реляционной модели
Большая часть данных, возникающих в ходе деятельности предприятия, представлена в виде электронных и бумажных документов. С точки зрения манипулирования этими данными все аспекты хозяйственной деятельности либо являются документооборотом, либо могут быть формально к нему сведены. Сегодня доминирующее положение занимают реляционные СУБД, которые обеспечивают удобный способ хранения информации в виде таблиц.
Структуру данных большинства реальных документов можно представить как произвольное иерархическое дерево с горизонтальными связями. Документы полностью хранятся в одной ячейке таблицы реляционной базы либо разбиваются на множество таблиц, а некоторые таблицы из разных документов объединяются. Однако в реляционной базе данных мы уже имеем дело с другими документами, поэтому алгоритм обработки реального документа нельзя сделать основой алгоритма программного кода хранимой процедуры. Реальные документы снова появляются лишь на уровне приложения. Здесь, по сути, мы имеем дело не с отображением, а с перепроектированием документов и, соответственно, документооборота.
Как известно, целью реляционного подхода было преодоление ограничений ранних систем — иерархических и сетевых. Реляционная модель достаточна для моделирования предметных областей, но само проектирование базы в терминах отношений часто оказывается очень сложным. Потребность проектировщиков в более удобных и мощных средствах представления предметной области вызвала появление семантического моделирования. Основная цель исследований в этой области состоит в том, чтобы сделать СУБД более «разумными», максимально отражающими особенности прикладной области. Если в основу СУБД будет положена модель данных, более соответствующая семантике предметной области, то и построенные на ее основе базы данных будут больше соответствовать реальным системам, а проектирование баз данных значительно упростится.
qWORD-XML основывается на расширенной реляционной модели данных RM/T [1], семантически более полной, чем базовая реляционная модель. RM/T была предложена Тедом Коддом в 1979 году для расширения семантических аспектов реляционной модели и поддерживает определенную атомарную и молекулярную семантику. Первая представляется n-мерными отношениями (в крайнем случае бинарными), которые являются минимальными смысловыми единицами, а вторая — смысловыми единицами, большими n-мерных отношений. RM/T поддерживает четыре измерения молекулярной семантики: декартову агрегацию, обобщение, агрегацию покрытия и предшествование событий. Характеристическая агрегация и обобщение могут быть описаны древовидной структурой, а ассоциативная агрегация и агрегация покрытия — горизонтальными связями между объектами. Таким образом, в RM/T, по сути, предлагается введение молекулярной структуры (дерева с горизонтальными связями) поверх атомарной структуры (n-мерного отношения).
Логико-математический аппарат иерархической базы данных с горизонтальными связями в общем случае намного сложнее, чем в реляционной базе данных. В RM/T для реализации связей между объектами используются специальные графовые отношения, соответственно предусматривается специальный набор операций манипулирования такими отношениями. Поэтому в операционном плане RM/T ориентирована на программистов, а не на пользователей, но в структурном плане более естественна и интуитивно понятна.
Из-за своей сложности RM/T не получила в свое время широкого распространения, но появление и развитие платформы XML сделало возможным формальное описание иерархической модели с горизонтальными связями. Причиной возврата к иерархической модели данных (в варианте XML) стало более естественное для человека отображение семантики предметной области. В модели данных XML допустимыми структурами являются деревья, узлы которых — элементы, обладающие атрибутами и содержанием. Для адресации в дереве элементов используется язык XPath, в котором предполагается упорядоченность элементов дерева. Горизонтальные связи между элементами могут быть определены с помощью языков XLink и XPointer. Для запросов по дереву элементов служит язык XQuery, а для преобразования структуры дерева элементов — язык XSLT. Объектная модель документа DOM включает в себя набор низкоуровневых операций манипулирования узлами документа.
Технология XML возникла из языка описания документов, а потому структура данных реального документа и операции манипулирования документами естественным образом описываются языками платформы XML. При использовании модели данных XML появляется возможность отображения документов и алгоритмов их обработки в базу данных на уровне СУБД, а не на уровне приложения. В этом случае построение информационных систем становится в большей степени описательным, декларативным, а сами системы больше соответствуют семантике предметной области.
Обеспечение динамики систем
Современные подходы к моделированию данных (реляционный и объектный) ориентированы в первую очередь на статическое моделирование прикладной области. В лучшем случае используется практика долгой и тщательной разработки схемы данных, а уже потом ее фиксации и реализации в информационной системе, но не учитывается то, что введенные данные могут изменяться (а не только пополняться). Благодаря реализации модели данных XML появляется возможность учитывать и поддерживать изменчивость и расширяемость схемы базы и изменчивость самих данных, причем без декларирования явным образом общей схемы базы данных. Это позволяет вести непрерывную разработку приложений с учетом развития предметной области.
Для XML-документов могут быть использованы различные языки описания схем, например XDR, XML Schema, Relax NG, Schematron. Некоторые языки поддерживают открытую модель информационного наполнения, что позволяет добавлять в XML-документ элементы и их атрибуты, которые не были предварительно описаны в продекларированной схеме документа. Следовательно, применение модели данных XML позволяет модифицировать схему данных не только в процессе создания базы данных, но и во время ее эксплуатации.
Важно отметить, что в модели данных XML не возникает проблем с отсутствием значений. Если значение некоторого элемента или атрибута элемента не определено, то этот элемент или атрибут просто отсутствует в XML-документе. Следовательно, модель данных XML естественным образом подходит для описания разреженных данных.
Фактически, в qWORD-XML иерархическая модель данных в варианте XML накладывается поверх реляционной, что позволяет, с одной стороны, сохранить строгость реляционной модели, а с другой — привнести в нее дополнительную молекулярную семантику [2]. Таким образом, обеспечивается совмещение достоинств реляционной и дореляционных моделей.
Иерархия моделируется как дерево информационных объектов со специфичным для данного объекта набором понятий («реквизитов»). Объекты соответствуют элементам XML-документа, а понятия — атрибутам элементов. С другой точки зрения объекты соответствуют реляционным отношениям, а понятия — атрибутам отношений (рис. 1).
Взаимосвязь объектов (дерево объектной структуры) строится за счет суррогатных первичных ключей, структурированных специальным образом: между данными реализуются информационные связи. Структурирование ключа делает его значимым и позволяет помимо однозначной идентификации экземпляра объекта получить ряд дополнительных возможностей.
Ключ разбивается на отдельные значимые фрагменты. Для каждого объекта при его описании задается длина кода экземпляра. Фрагмент ключа из N символов кодирует 52N экземпляров. Таким образом, длина ключа однозначно определяет уровень иерархии, на котором находится объект, и максимальное количество экземпляров объекта на этом уровне. Используя метод редукции ключа, можно получить доступ к любому предку данного экземпляра объекта.
Горизонтальные связи объектов можно получать за счет применения одинаковых значений понятий в разных объектах. Возможность описывать виртуальные и ссылочные объекты позволяет создавать отображения иерархии, не соответствующей спроектированному дереву.
Понятия объектов могут быть структурированными (упорядоченное множество слов) и неструктурированными (текст, рисунок, звук, видео). Слова значений структурированных понятий кодируются суррогатными кодами. Для таких слов создаются домены, представляющие собой два словаря: прямой словарь связывает слово значения с суррогатным кодом, а обратный связывает суррогатный код со словом значения. Экземпляр объекта (кортеж отношения) связывает слова значений понятий из разных доменов через их суррогатные коды (рис. 2). Кроме того, прямой словарь используется для индексации значений понятий, что позволяет осуществлять быстрый поиск. Кодирование слов значений также решает проблему избыточности данных, свойственную иерархической организации.
Изменчивость данных во времени учитывается за счет поддержки системой динамических связей между элементами данных (рис. 3). Такие связи могут быть описаны с помощью языков XLink и XPointer. Рассмотрим пример базы данных (рис. 3а). Гражданам выдаются документы, в которых есть ссылки на адреса их регистрации. Если адрес изменяется, то для ранее созданного документа должна сохраняться ссылка на правильный адрес.
При взгляде на базу с точки зрения прикладного значения данных документов объекты должны располагаться так, как показано на рис 3б. Для создания такого отображения объект «Адрес» описывается как ссылочный, и для него устанавливается флаг «Производить динамическую коррекцию». В этом случае при модификации экземпляра «Адрес» система будет автоматически создавать и модифицировать для экземпляра «Документ» значение понятия прямой связи с экземпляром «Адрес».
Например, пусть код экземпляра объекта «Гражданин» равен AAAА. При создании экземпляра «Документ» ему присваивается код AAAА|АА. При создании экземпляра «Адрес» ему присваивается код AAAА|А, а в понятие прямой связи экземпляра «Документ» автоматически записывается значение А (дополнение к коду экземпляра «Гражданин», позволяющее получить код экземпляра «Адрес», на который ссылается данный экземпляр «Документ»). Теперь, предположим, создается новый экземпляр «Документ» AAAА|АB. Если «Адрес» не изменяется, то в понятие прямой связи этого экземпляра «Документ» автоматически записывается значение А (рис. 3в). При модификации «Адреса» автоматически создается его новый экземпляр AAAА|B, в который копируются неизмененные значения понятий из экземпляра AAAА|А. В понятие прямой связи экземпляра «Документ» AAAА|АB записывается значение В, а значение понятия прямой связи экземпляра «Документ» AAAА|АА не изменяется (рис. 3г).
Оперативные и аналитические системы
На практике предприятия используют две отдельные базы данных: с оперативными данными (транзакционные системы, OLTP), предназначенную для поддержки текущей деятельности организации, и с аналитическими данными (системы поддержки принятия решения, DSS), предназначенную для поддержки принятия решений. Эти системы различаются по условиям функционирования и требованиям к ресурсам. OLTP-системы обычно характеризуются жесткими требованиями к производительности, предсказуемым уровнем общей нагрузки и высоким коэффициентом использования. DSS, напротив, обычно варьируются по требованиям к производительности, уровень их нагрузки непрогнозируем и им с непредсказуемой регулярностью приходится обрабатывать большие объемы данных. С помощью qWORD-XML возможна реализация как оперативных, так и аналитических информационных систем.
Для большей гибкости и свободы принятия проектных решений система не может строиться как надстройка над какой-либо SQL- или объектной СУБД. Такие системы не предоставляют непосредственного доступа к физическим структурам хранения, а обеспечивают высокоуровневые объектные или SQL-интерфейсы. Соответственно, возникнут сложности при реализации физического уровня надстраиваемой СУБД. Так как ее физические структуры не являются ни отношениями, ни объектами, неизбежны потери производительности при их представлении отношениями или объектами. Поэтому qWORD-XML реализуется как надстройка над M-системой.
М — процедурный язык программирования без жесткой парадигмы, который стандартизирован ISO, ANSI и FIPS. Главным достоинством М-систем является эффективный механизм управления внешней памятью в виде B*-деревьев, которые на логическом уровне представляются через глобалы — хранимые на диске и рассортированные по строковым индексам массивы произвольной размерности. Память в массиве занимают лишь те элементы, для которых определено значение. Координация доступа к глобальным переменным в многопользовательской среде осуществляется с помощью блокировок; М поддерживает обработку транзакций и сетевое взаимодействие. На этом языке могут быть реализованы все известные модели данных. Вместе с тем M — это прежде всего язык разработки СУБД, а не работы с ними.
В качестве надстройки над М-системой могут использоваться СУБД Cache? компании InterSystems или GT.M компании Sanchez Computer Associates. Эти СУБД имеют все характеристики промышленных систем, такие как высокая производительность, надежность, масштабируемость, открытость и переносимость. Еще один важный фактор — стоимость решения. М-системы могут служить основой для реализации оперативных и аналитических систем, поскольку удовлетворяют основным требованиям к этим системам: высокая производительность и эффективная обработка транзакций для OLTP-систем, эффективное хранение и обработка больших объемов данных, высокий уровень безопасности данных для DSS-решений.
Cache? — коммерческий продукт, а GT.M имеет открытую архитектуру, реализация которой в версии для платформы x86/Linux свободно распространяется вместе с исходными кодами. По своим встроенным инструментальным возможностям GT.M уступает Cache?, но благодаря открытости системы возможна реализация собственных интерфейсов.
Процедурная часть qWORD-XML реализуется на M, как и набор низкоуровневых операций, соответствующих интерфейсам DOM и предназначенных для работы с древовидной структурой. Пользовательские хранимые процедуры и триггеры также создаются в виде программ на M, в которых можно задействовать эти низкоуровневые операции.
Универсальная инструментальная среда
Современные промышленные СУБД имеют набор интерфейсов к внешним инструментам проектирования и разработки приложений или снабжаются собственными инструментальными средствами. qWORD-XML совмещает инструменты для построения и применения баз данных в рамках единого универсального визуального инструмента. Это облегчает работу пользователей, ускоряет разработку информационных систем и упрощает их сопровождение.
Инструментальная среда qWORD-XML представляет собой универсальный браузер, реализованный на Delphi как клиентское приложение к M-серверу. В универсальном браузере взаимодействие с базой данных осуществляется через экранные формы, описывающие либо все дерево объектов, либо его часть в виде, удобном для конкретного рабочего места. Отображение состоит в общем случае из дерева объектов, дерева экземпляров объектов и панелей инструментов (рис. 4). База данных проектируется визуально как набор взаимоувязанных объектов.
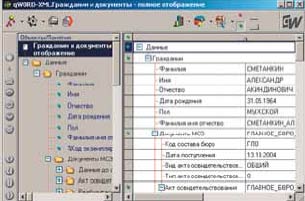
|
| Рис. 4. Пример отображения |
Экземпляры объектов в отображении показываются в виде дерева-таблицы. Каждый экземпляр объекта может занимать несколько строк и колонок дерева-таблицы для вывода значений его понятий. Объекты нижнего уровня могут «встраиваться» в произвольные строки объектов верхнего уровня. Понятия одного объекта выводятся в ячейках дерева-таблицы. Помимо значений понятий, в ячейках могут выводиться константы (заголовки), служащие для наглядности представления информации. В описании отображений допускается указать множество параметров, меняющих внешний вид окна, что позволяет получать традиционные виды экранных форм.
Экранное представление может быть создано с доступом ко всей информации или, за счет параметризации экранных форм, в виде последовательных вызовов экранов, содержащих часть информации в форме бланков или таблиц. Первый вариант удобен для аналитических задач, а второй позволяет построить традиционное оперативное приложение. Отображение также может интерпретироваться как выходная печатная форма, благодаря чему удается использовать отображения в качестве конструкторов печатных форм. Различных экранных представлений (отображений) базы данных допускается создавать сколько угодно.
Универсальный браузер обеспечивает всю работу пользователя с базой данных. Это проектирование структуры и построение приложений, просмотр, ввод и коррекция информации, поиск данных по произвольным запросам, аналитическая обработка информации и ее графическая интерпретация, формирование выходных печатных форм.
Рассмотрим, например, аналитическую обработку, смысл которой заключается в группировке и обобщении данных. Группировка обычно выполняется в соответствии со многими критериями. Аналитическая обработка возможна внутри одного отображения (рис. 5). Перед выполнением аналитической обработки можно организовать предварительный поиск данных по объектам и значениям их понятий. Для задания поисковых условий используется колонка «Условие». Результаты выводятся в виде различных графических изображений, перекрестной таблицы или экранной формы.
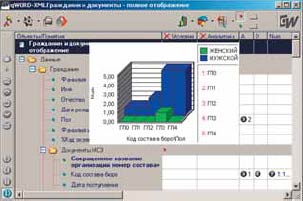
|
| Рис. 5. Отображение в режиме «Аналитик» |
Рассмотрим запрос, нацеленный на распределение документов по организациям (составам бюро), в которых выданы документы, и по полу граждан, которым выданы документы. Задание аналитического запроса устанавливается специальными маркерами A, D, Y в строках, соответствующих анализируемым признакам. Колонка A предназначена для пометки понятий, значения которых будут использованы в качестве индексов аналитического среза. Возможно задание сразу нескольких аналитических срезов (A1, A2 и т.д.). В данном случае мы задали срез A1 по кодам организаций, а A2 — по полам.
Колонка D предназначена для пометки понятий, значения которых будут применяться как вычисляемые агрегированные значения аналитического среза. В данном случае маркером D также помечено понятие «код организации», поскольку нам нужно просто получить количество документов. В колонках Num, Sum, Min, Max, Mid с помощью маркера Y выбираются необходимые агрегирующие функции: количество значений, их сумма, минимальное/максимальное значения, их среднее арифметическое. Колонка «Аналитика» предназначена для описания выражений преобразования значений из Аi и D до их агрегирования.
Что имеем
Поддерживаемая qWORD-XML иерархическая модель более естественно для человека отражает семантику предметной области. Схема базы данных не декларируется явным образом и может изменяться в процессе развития и эксплуатации информационной системы. qWORD-XML может служить для реализации как оперативных, так и аналитических систем, совмещая в рамках универсального браузера инструменты для построения и использования баз данных.
Литература
- Кодд Э.Ф. Расширение реляционной модели для лучшего отражения семантики. // СУБД, 1996, № 5.
- Веселов В., Долженков А. Опыт построения XML-СУБД // Открытые системы, 2002, № 6.
Анатолий Долженков (dol@sparm.com) — директор по науке компании «СП. АРМ», Дмитрий Тимофеев (tdv@sparm.com) — аспирант Института информатики и автоматизации РАН (Санкт-Петербург).
Достоинства и недостатки систем баз данных
Дореляционные системы (иерархические и сетевые)
Достоинства
- Структуры данных в дореляционных системах являются наилучшими абстракциями для описания объектов и отношений в реальном мире, наиболее полно отражая семантику предметной области.
- Доступны развитые низкоуровневые средства управления данными во внешней памяти.
- Возможно построение вручную эффективных прикладных систем.
Недостатки
- Доступ к базе данных производится на уровне записей, между которыми поддерживаются явные связи. Следствиями этого являются низкоуровневый навигационный стиль программирования и сложность использования таких систем непрограммистами.
- Отсутствует физическая и логическая независимость данных, необходимы знания об их физической организации. Пользователю приходится выполнять оптимизацию доступа к базе данных без поддержки системы.
- Отсутствует теоретическая основа. Понятие модели данных фактически вошло в обиход специалистов только вместе с реляционным подходом, а абстрактные представления ранних СУБД появились позже.
Реляционные системы
Достоинства
- Создан простой и мощный математический аппарат, опирающийся на теорию множеств и математическую логику и обеспечивающий теоретический базис к организации баз данных.
- Обеспечена физическая и логическая независимость данных, а потому нет необходимости знать конкретную физическую организацию базы данных во внешней памяти.
- Единственной конструкцией данных в реляционной модели является отношение. Между данными реализуются виртуальные связи (на основании значений данных), а не физические (на основании указателей), как в ранних системах. Следствием этого является ненавигационный доступ к данным (отношения трактуются как операнды и результаты операции, а не обрабатываются поэлементно). Простота структуры данных и манипулятивных операций облегчает работу пользователей (как программистов, так и непрограммистов).
Недостатки
- Примитивность типов данных становится причиной ограничений применимости реляционной модели в нетрадиционных областях (например, САПР), в которых требуются сложные структуры.
- Возможности описания семантики предметной области минимальны. Реляционная база данных представляет собой совокупность взаимосвязанных отношений, для которых должны поддерживаться ограничения целостности данных.
Примеры использования qWORD-XML
Автоматизированная информационно-справочная и аналитическая система по проблемам инвалидности. Решение задач информационной поддержки специалистов, связанных с проблемами инвалидности (служба реабилитации, региональные органы управления).
Информационно-аналитическая система органов социальной защиты населения субъекта федерации. Задачи системы связаны с реализацией перевода всех специалистов органов социальной защиты на новый уровень информационной поддержки с формированием ведомственной «информационной вертикали» и поэтапным созданием единого информационного пространства социальной сферы субъекта федерации.
Автоматизированная информационно-справочная и аналитическая система «Реабилитационный восстановительный центр». Типовой комплекс для поддержки информационных потоков и баз данных, используемых в реабилитационных учреждениях.
Автоматизированная информационная система «Станция переливания крови». Система разработана для комплексной информатизации процесса заготовки, обследования, хранения и распределения крови и ее компонентов на станциях переливания, в отделениях переливания крови и банках крови. Система предлагает полный пакет администрирования доноров, возможности ведения их единой картотеки, взаимодействия с источниками и потребителями данных в смежных областях.
