
Индустрия программного обеспечения постоянно пытается решить вопрос качества, но насколько значимы ее успехи, на данный момент сказать довольно сложно. В статье идет речь о новом поколении инструментов тестирования, которые призваны повысить качество программ. Однако инструменты, даже автоматические, не в состоянии помочь, если их используют неправильно. Поэтому обсуждение инструментов предваряет изложение общих положений «правильного» тестирования.
Подходы к улучшению качества программ
«Борьба за качество» программ может вестись двумя путями. Первый путь «прост»: собрать команду хороших программистов с опытом участия в аналогичных проектах, дать им хорошо поставленную задачу, хорошие инструменты, создать хорошие условия работы. С большой вероятностью можно ожидать, что удастся разработать программную систему с хорошим качеством.
Второй путь не так прост, но позволяет получать качественные программные продукты и тогда, когда перечисленные условия соблюсти не удается — не хватает хороших программистов, четкости в поставке задачи и т.д. Этот путь предписывает стандартизировать процессы разработки: ввести единообразные требования к этапам работ, документации, организовать регулярные совещания, проводить инспекцию кода и проч. Одним из первых продвижений на этом фронте стало введение понятия жизненного цикла программной системы, четко определявшее необходимость рассмотрения многих задач, без решения которых нельзя рассчитывать на успех программного проекта.
В простейшем варианте набор этапов жизненного цикла таков:
- анализ требований;
- проектирование (предварительное и детальное);
- кодирование и отладка ("программирование");
- тестирование;
- эксплуатация и сопровождение.
Стандартизованная схема жизненного цикла с четкой регламентацией необходимых работ и с перечнем соответствующей документации легла в основу так называемой «водопадной» или каскадной модели. Водопадная модель подразумевает жесткое разбиение процесса разработки программного обеспечения на этапы, причем переход с одного этапа на другой осуществляется только после того, как будут полностью завершены работы на предыдущем этапе. Каждый этап завершается выпуском полного комплекта документации, достаточной для того, чтобы разработка могла быть продолжена другой командой. Водопадная модель стала доминирующей в стандартах процессов разработки Министерства обороны США. Многие волей или неволей, даже отклоняясь от этой модели, в целом соглашались с ее разумностью и полезностью.
Водопадная модель требовала точно и полно сформулировать все требования; изменение требований было возможно только после завершения всех работ. Водопадная модель не давала ответ на вопрос, что делать, когда требования меняются или меняется понимание этих требований непосредственно во время разработки.
В конце 80-х годов была предложена так называемая спиральная модель, был развит и проверен на практике метод итеративной и инкрементальной разработки (Iterative and Incremental Development, IID). В спиральной модели были учтены проблемы водопадной модели. Главный упор в спиральной модели делается на итеративности процесса. Описаны опыты использования IID с длиной итерации всего в полдня. Каждая итерация завершается выдачей новой версии программного обеспечения. На каждой версии уточняются (и, возможно, меняются) требования к целевой системе и принимаются меры к тому, чтобы удовлетворить и новые требования. В целом Rational Unified Process (RUP) также следует этой модели.
Позволило ли это решить проблему качества? Лишь в некоторой степени.
Проблема повышения качества программного обеспечения в целом и повышения качества тестирования привлекает все большее внимание; в университетах вводят специальные дисциплины по тестированию и обеспечению качества, готовят узких специалистов по тестированию и инженеров по обеспечению качества. Однако по-прежнему ошибки обходятся только в США от 20 до 60 млрд. долл. ежегодно. При этом примерно 60% убытков ложится на плечи конечных пользователей. Складывается ситуация, при которой потребители вынуждены покупать заведомо бракованный товар.
Вместе с тем, ситуация не безнадежна. Исследование, проведенное Национальным институтом стандартов и технологии США, показало, что размер убытков, связанных со сбоями в программном обеспечении, можно уменьшить примерно на треть, если вложить дополнительные усилия в инфраструктуру тестирования, в частности, в разработку инструментов тестирования.
Каково же направление главного удара? Что предлагают «наилучшие практики»?
В 80-е и 90-е годы ответ на этот вопрос звучал примерно так. Наиболее дорогие ошибки совершаются на первых фазах жизненного цикла — это ошибки в определении требований, выборе архитектуры, высокоуровневом проектировании. Поэтому надо концентрироваться на поиске ошибок на всех фазах, включая самые ранние, не дожидаясь, пока они обнаружатся при тестировании уже готовой реализации. В целом тезис звучал так: «Сократить время между моментом ?внесения? ошибки и моментом ее обнаружения». Тезис в целом хорош, однако не очень конструктивен, поскольку не дает прямых рекомендаций, как сокращать это время.
В последние годы в связи с появлением методов, которые принято обозначать эпитетом agile («шустрый», «проворный») предлагаются и внедряются новые конструктивные методы раннего обнаружения ошибок. Скажем, современные модели, такие как Microsoft Solutions Framework (MSF) и eXtreme Programming (XP), выделяют следующие рекомендации к разработке тестов:
- все необходимые тесты должны быть готовы к моменту реализации той или иной части программы; при этом обычно один тест соответствует одному требованию;
- совокупность ранее созданных тестов должна (при неизменных требованиях) выполняться на любой версии программы;
- если же в требования вносятся изменения, то тесты должны меняться максимально оперативно.
Иными словами, ошибка — будь она в требованиях, в проекте или в реализации — не живет дольше момента запуска теста, проверяющего реализацию данного требования. Значит, хотя астрономическое время между «внесением» ошибки и ее обнаружением может оказаться и большим, но впустую усилий потрачено не очень много, реализация не успела уйти далеко.
Не будем останавливаться на справедливости этих положений и их эффективности. Как часто бывает, побочный эффект новшества оказался более значимым, чем собственно реализация этой идеи. В данном случае дискуссии вокруг «шустрых» методов привели к новому пониманию места тестирования в процессе разработки программного обеспечения. Оказалось, тестирование в широком понимании этого слова, т.е. разработка, пропуск тестов и анализ результатов, решают не только задачу поиска уже допущенных в программном коде ошибок. Серьезное отношение к тестированию позволяет предупреждать ошибки: стоит перед тем, как писать код, подумать о том, какие ошибки в нем можно было бы сделать, и написать тест, нацеленный на эти ошибки, как качество кода улучшается.
В новых моделях жизненного цикла тестирование как бы растворяется в других фазах разработки. Так, MSF не содержит фазы тестирования — тесты пишутся и используются всегда!
Итак, различные работы в процессе производства программ должны быть хорошо интегрированы с работами по тестированию. Соответственно, инструменты тестирования должны быть хорошо интегрированы со многими другими инструментами разработки. Из крупных производителей инструментов разработки программ, первыми это поняли компании Telelogic (набор инструментов для проектирования, моделирования, реализации и тестирования телекоммуникационного ПО, базирующийся на нотациях SDL/MSC/TTCN) и Rational Software (аналогичный набор, преимущественно базирующийся на нотации UML). Следующий шаг сделала компания IBM, начав интеграцию возможностей инструментов от Rational в среду разработки программ Eclipse.
Тезис XP — «Пиши тест перед реализацией» — хорош как лозунг, но в реальности столь же неконструктивен. Для крупных программных комплексов приходится разрабатывать тесты различного назначения: тесты модулей, интеграционные или компонентные тесты, системные тесты.
Три составляющие тестирования — экскурс в теорию
Модульному тестированию подвергаются небольшие модули (процедуры, классы и т.п.). При тестировании относительного небольшого модуля размером 100-1000 строк есть возможность проверить, если не все, то, по крайней мере, многие логические ветви в реализации, разные пути в графе зависимости данных, граничные значения параметров. В соответствии с этим строятся критерии тестового покрытия (покрыты все операторы, все логические ветви, все граничные точки и т.п.).
Проверка корректности всех модулей, к сожалению, не гарантирует корректности функционирования системы модулей. В литературе иногда рассматривается «классическая» модель неправильной организации тестирования системы модулей, часто называемая методом «большого скачка». Суть метода состоит в том, чтобы сначала оттестировать каждый модуль в отдельности, потом объединить их в систему и протестировать систему целиком. Для крупных систем это нереально. При таком подходе будет потрачено очень много времени на локализацию ошибок, а качество тестирования останется невысоким. Альтернатива «большому скачку» — интеграционное тестирование, когда система строится поэтапно, группы модулей добавляются постепенно.
Распространение компонентных технологий породило термин «компонентное тестирование» как частный случай интеграционного тестирования.
Полностью реализованный программный продукт подвергается системному тестированию. На данном этапе тестировщика интересует не корректность реализации отдельных процедур и методов, а вся программа в целом, как ее видит конечный пользователь. Основой для тестов служат общие требования к программе, включая не только корректность реализации функций, но и производительность, время отклика, устойчивость к сбоям, атакам, ошибкам пользователя и т.д. Для системного и компонентного тестирования используются специфические виды критериев тестового покрытия (например, покрыты ли все типовые сценарии работы, все сценарии с нештатными ситуациями, попарные композиции сценариев и проч.).
Инструменты тестирования — реальная практика
Закончив экскурс в методику, вернемся к вопросу, какие инструменты тестирования используются в настоящее время и насколько они соответствуют новым представлениям о месте тестирования в процессе разработки программ.
На данный момент в наибольшей мере автоматизированы следующие этапы работ: исполнение тестов, сбор полученных данных, анализ тестового покрытия (для модульного тестирования обычно собирают информацию о покрытых операторах и о покрытых логических ветвях), отслеживание статуса обработки запросов на исправление ошибок.
Обзор инструментов тестирования будем вести в обратном порядке — от системного тестирования к модульному.
Широко распространены инструменты тестирования приложений с графическим пользовательским интерфейсом. Их часто называют инструментами функционального тестирования. Если уровень ответственности приложения не велик, то таким тестированием можно ограничиться; подобное тестирование наиболее дешево.
В данном виде тестирования широко применяются инструменты записи-воспроизведения (record/playback); из наиболее известных продуктов можно назвать Rational Robot (компания IBM/Rational), WinRunner (Mercury Interactive), QARun (Compuware). Наряду с этим существуют инструменты для текстовых терминальных интерфейсов, например, QAHiperstation компании Compuware.
Для системного нагрузочного тестирования Web-приложений и других распределенных систем широко используется инструментарий LoadRunner от Mercury Interactive; он не нацелен на генерацию изощренных сценариев тестирования, зато дает богатый материал для анализа производительности, поиска узких мест, сказывающихся на производительности распределенной системы.
Примерная общая схема использования инструментов записи-воспроизведения такова:
- придумать сценарий (желательно, на основе систематического анализа требований);
- провести сеанс работы в соответствии с данным сценарием; инструмент запишет всю входную информацию, исходившую от пользователя (нажатия клавиш на клавиатуре, движения мыши и проч.), и сгенерирует соответствующий скрипт.
Полученный скрипт можно многократно запускать, внося в него при необходимости небольшие изменения.
При записи скрипта можно делать остановки для того, чтобы указывать, какие ответы системы в конкретной ситуации надо рассматривать как правильные, какие вариации входных данных пользователя возможны и т.д. При наличии таких вариаций при очередном воспроизведении теста инструмент самостоятельно будет выбирать одну из определенных альтернатив. При несовпадении ответа системы с ожидаемым ответом будет фиксироваться ошибка.
Впрочем, возможности данного вида тестирования ограничены:
- запись скриптов возможна только при наличии прототипа будущего графического интерфейса;
- поддержка скриптов очень трудоемка; часто скрипт легче записать заново, чем отредактировать;
- как следствие, проводить работы по созданию тестов параллельно с разработкой самой системы не эффективно, а до создания прототипа вообще невозможно.
Следующий класс инструментов — инструменты тестирования компонентов. Примером является Test Architect (IBM/Rational). Такие инструменты помогают организовать тестирование приложений, построенных по одной из компонентных технологий (например, EJB). Предусматривается набор шаблонов для создания различных компонентов тестовой программы, в частности, тестов для модулей, сценариев, заглушек.
Отвечает ли этот инструмент требованию опережающей разработки тестов? В целом, да: для создания теста достаточно описания интерфейсов компонентов. Но есть и слабые места, которые, впрочем, присущи и большинству других инструментов. Так, сценарий тестирования приходится писать вручную. Кроме того, нет единой системы задания критериев тестового покрытия и связи этих критериев с функциональными требованиями к системе.
Последний из рассматриваемых здесь классов инструментов — инструменты тестирования модулей. Примером может служить Test RealTime (IBM/Rational), предназначенный для тестирования модулей на C++. Важной составляющей этого инструмента является механизм проверочных «утверждений» (assertion). При помощи утверждений можно сформулировать требования к входным и выходным данным функций/методов классов в форме логических условий, в аналогичной форме можно задавать инвариантные требования к данным объектов. Это существенный шаг вперед по сравнению с Test Architect. Аппарат утверждений позволяет систематическим образом представлять функциональные требования и на базе этих требований строить критерии тестового покрытия (правда, Test RealTime автоматизированной поддержки анализа покрытия не предоставляет).
В принципе, этим инструментом можно пользоваться при опережающей разработке тестов, но остается нереализованной все та же функция генерации собственно тестовых воздействий — эта работа должна выполняться вручную. Нет никакой технической и методической поддержки повторного использования тестов и утверждений.
Решение перечисленных проблем предлагает новое поколение инструментов, которые следуют подходу тестирования на основе модели (model based testing) или на основе спецификаций (specification based testing).
Чем могут помочь модели
В голове разработчика и тестировщика всегда присутствует та или иная «модель» устройства программы, а также «модель» ее желаемого поведения, исходя из которой, в частности, составляются списки проверяемых свойств и создаются соответствующие тестовые примеры. (Заметим, что это разные модели; первые часто называют архитектурными, а вторые — функциональными или поведенческими.) Они зачастую составляются на основе документов или обсуждений в неформальном виде.
Разработка моделей и спецификаций связана с «математизацией» программирования. Попытки использовать различные математические подходы для конструирования и даже генерации программ предпринимались с первых лет возникновения компьютеров. Относительный успех был достигнут в теории компиляторов, реляционных баз данных и в нескольких узкоспециальных областях; серьезных результатов в большинстве практических областей достичь не удалось. Многие стали относиться к формальным методам в программировании скептически.
Новый всплеск интереса к формальным методам произошел в первой половине 90-х. Его вызвали первые результаты, полученные при использовании формальных моделей и формальных спецификаций в тестировании.
Преимущества тестирования на основе моделей виделись в том, что:
- тесты на основе спецификации функциональных требований более эффективны, так как они в большей степени нацелены на проверку функциональности, чем тесты, построенные только на знании реализации;
- на основе формальных спецификаций можно создавать самопроверяющие (self-checking) тесты, так как из формальных спецификаций часто можно извлечь критерии проверки результатов целевой системы.
Однако не было ясности в отношении качества подобных тестов. Модели обычно проще реализации, поэтому можно было предположить, что тесты, хорошо «покрывающие» модель, слишком бедны для покрытия реальных систем. Требовались широкие эксперименты в реальных проектах.
Модель — некоторое отражение структуры и поведения системы. Модель может описываться в терминах состояния системы, входных воздействий на нее, конечных состояний, потоков данных и потоков управления, возвращаемых системой результатов и т.д. Для отражения разных аспектов системы применяются и различные наборы терминов. Формальная спецификация представляет собой законченное описание модели системы и требований к ее поведению в терминах того или иного формального метода. Для описания характеристик системы можно воспользоваться несколькими моделями в рамках нескольких формализмов. Обычно, чем более общей является нотация моделирования, тем больше трудностей возникает при автоматизации тестирования программы на основе модели/спецификации, описанной в этой нотации. Одни нотации и языки больше ориентированы на доступность и прозрачность описания, другие — на последующий анализ и трансляцию, в частности, трансляцию спецификации в тест. Предпринимались попытки разработки языка формальных спецификаций, удовлетворяющего требованиям промышленного использования (например, методология RAISE), однако широкого применения они не нашли.
Имеется несколько ставших уже классическими нотаций формальных спецификаций: VDM, Z, B, CCS, LOTOS и др. Некоторые из них, например, VDM, используются преимущественно для быстрого прототипирования. Язык B удобен для анализа, в частности для аналитической верификации моделей. Все эти языки активно используются в рамках университетских программ. В реальной практике для описания архитектурных моделей используется UML, а для построения поведенческих моделей — языки SDL/MSC, исполнимые диаграммы UML и близкие к ним нотации.
Перечисленные языки и нотации для поведенческих моделей, к сожалению, не обладают достаточной общностью. Они хорошо себя зарекомендовали в телекоммуникационных приложениях и практически бесполезны для описания функциональности программных систем «общего вида»: операционных систем, компиляторов, СУБД и т.д.
На роль инструментов разработки тестов для подобных систем претендует новое поколение средств описания моделей/спецификаций и средства генерации тестов на проверку согласованности поведения реализации заданной модели.
Инструменты тестирования на основе моделей
Test Real Time — один из первых представителей этой группы. Более широкие возможности предоставляет Jtest компании Parasoft. Интересен инструментарий компании Comformiq. Семейство инструментов разработки тестов на основе моделей предлагает Институт системного программирования РАН в кооперации с компанией ATS. Поскольку семейство UniTesK авторам знакомо существенно ближе, мы изложим общую схему подхода тестирования на основе моделей на примерах из UniTesK.
 |
| Рис. 1. Фазы процесса разработки спецификаций и тестов |
Общая схема процесса разработки спецификаций и тестов состоит из четырех фаз (рис. 1).
Первая фаза относительно коротка, но в реальных проектах она важна. Именно здесь закладывается уровень абстрактности модели. Модель должна быть максимально простой: это позволит требовать исчерпывающего набора тестов. В то же время, модель должна быть содержательной, раскрывать специфику тестируемой реализации. Таким образом, задача первой фазы — найти компромисс между абстрактностью и детальностью.
Задача второй фазы — описание требований к поведению системы. Многие подходы (например, SDL) предлагают описывать исполнимые модели, которые можно рассматривать как прототипы будущей реализации. Задание требований в таком случае определяется формулой «реализация должна вести себя так же, как модель». Подход понятен, но, к сожалению, во многих реальных ситуациях он не работает. Допустим, в заголовке некоего сообщения, построенного моделью, указано одно время, а в аналогичном заголовке от реализации — несколько другое. Это ошибка или нет? Еще один пример. Модель системы управления памятью сгенерировала указатель на свободный участок памяти, а реальная система выдала другой указатель: модель и система работают в разных адресных пространствах. Ошибка ли это?
UniTesK — унифицированное решение
UniTesK предлагает использовать так называемые неявные спецификации или спецификации ограничений. Они задаются в виде пред- и постусловий процедур и инвариантных ограничений на типы данных. Этот механизм не позволяет описывать в модели алгоритмы вычисления ожидаемых значений функций, а только их свойства. Скажем, в случае системы управления памятью модель будет задана булевским выражением в постусловии типа «значение указателя принадлежит области свободной памяти». Простой пример постусловия для функции «корень квадратный» приведен на риc. 2; одна и та же спецификация представлена в трех разных нотациях: в стиле языков Cи, Java и C#. Использование спецификационных расширений обычных языков программирования вместо классических языков формальных спецификаций — шаг, на который идут почти все разработчики подобных инструментов. Их различает только выразительная мощность нотаций и возможности анализа и трансляции спецификаций.
Третья фаза — разработка тестового сценария. В простейшем случае сценарий можно написать вручную, но в данной группе инструментов — это плохой тон. Тест, т.е. последовательность вызовов операций целевой системы с соответствующими параметрами, можно сгенерировать, отталкиваясь от некоторого описания программы или структуры данных. Будем называть такое описание сценарием. Компания Conformiq предлагает описать конечный автомат. Различные состояния автомата соответствуют различным значениям переменных целевой системы, переходы — вызовам операций этой системы. Определить автомат — это значит для каждого состояния описать, в какое состояние мы перейдем из данного, если обратимся к любой наперед заданной операции с любыми наперед заданными параметрами. Если такое описание получить легко, больше ничего делать не понадобится: инструмент сгенерирует тест автоматически и представит результаты тестирования, например, в виде MSC-диаграмм. Но легко ли это, скажем, для программы с одной целочисленной переменной и двумя-тремя операциями? Скорее всего, да. Однако в общем случае сделать попросту невозможно.
В UniTesK для генерации тестовых последовательностей конечный автомат не описывается, а генерируется по мере исполнения теста. Все, что требуется от разработчика теста, — это задание способа вычисления состояния модели на основании состояния целевой системы и способа перебора применяемых в текущем состоянии тестовых воздействий. Эти вычисления записываются в тестовых сценариях. Очередное тестовое воздействие выбирается на основании спецификации сценария в зависимости от результатов предыдущих воздействий. Такой подход обладает двумя важными преимуществами. Во-первых, это позволяет строить сложные тестовые последовательности в чрезвычайно компактной и легкой для написания и понимания форме. Во-вторых, тесты приобретают высокую гибкость: они легко могут быть параметризованы в зависимости от текущих потребностей тестирования и даже могут автоматически подстраиваться под незначительные изменения модели. На рис. 3 приведен пример сценарного метода.
 |
| Рис. 3. Пример сценарного метода, тестирующего вставку элемента в очередь с приоритетами |
В целом тестовый сценарий описывает итераторы для всех методов данного класса, однако каждый раз разработчик теста решает только локальную проблему — как перебрать входные параметры одного-единственного метода. Общую задачу — как организовать последовательность вызов; как нужное число раз вернуться в одно и то же состояние, чтобы провести испытание еще для одного метода, еще для одного значения параметра; когда остановиться, чтобы не делать лишней работы — все это берет на себя инструмент.
В UniTesK используется единая архитектура тестов, подходящая для тестирования систем различной сложности, относящихся к разным предметным областям, и обеспечивающая масштабируемость тестов. Компоненты тестов, требующие написания человеком, отделены от библиотечных и генерируемых автоматически (рис. 4).
В реальных системах количество различимых состояний и количество допустимых в каждом из них тестовых воздействий очень велико, что приводит к комбинаторному «взрыву состояний». Для борьбы с этим эффектом разработан механизм факторизации модели: те состояния целевой системы, различие между которыми несущественно с точки зрения задач данного теста, объединяются в одно обобщенное состояние модели; аналогичным образом объединяются в группы и тестовые воздействия. Процесс факторизации предоставляет разработчику свободу творчества, но, вместе с тем, он поддержан строгими исследованиями, определяющими достаточные условия, при соблюдении которых гарантированы корректность результатов и существенное сокращение времени тестирования при сохранении достигаемого тестового покрытия.
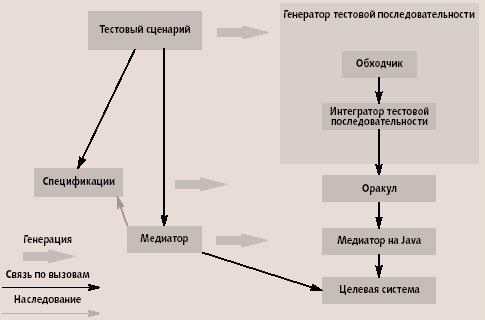
Рис. 4. Архитектура тестовой программ
 |
| Рис. 5. Использование UniTesK в среде разработки Forte 4.0 |
Создатели UniTesK, полагая, что не должно быть отдельной среды для разработки тестов, не только наделили его возможностью мимикрии под различные языки программирования, но обеспечили интеграцию составляющих его инструментов в популярные средства разработки программ. На рис. 5 представлен сеанс использования UniTesK в среде разработки Forte 4.0 компании Sun Microsystems.
Новое качество, которое обещают новые инструменты
Как отмечалось выше, создатели инструментов тестирования обычно сталкиваются со следующими проблемами:
- отсутствие или нечеткость определения критериев тестового покрытия, отсутствие прямой связи с функциональными требованиями;
- отсутствие поддержки повторного использования тестов;
- отсутствие автоматической генерации собственно теста (это касается как входных воздействий, так и эталонных результатов или автоматических анализаторов корректности реализации).
Имеются ли у инструментов тестирования, которые для генерации теста используют модель или формальную спецификацию целевой системы, принципиальные преимущества перед традиционными средствами? Чтобы ответить на этот вопрос, укажем, как отмеченные проблемы решаются для инструментов, использующих модели.
Критерии тестового покрытия. Основной критерий — проверка всех утверждений, в частности, утверждений, определяющих постусловия процедур или методов. Он легко проверяется и легко связывается с функциональными требованиями к целевой системе. Так, инструменты UniTesK, инструменты для платформ Java и C# предоставляют четыре уровня вложенных критериев.
Повторное использование тестов. Уровень повторного использования существенно выше, чем у традиционных инструментов. Разработчик тестов пишет не тестовый скрипт, а критерии проверки утверждения и тестовый сценарий. И то, и другое лишено многих реализационных деталей, и поэтому их проще переиспользовать для новой версии целевой системы или для адаптации спецификаций и тестов для сходного проекта. Например, статистика UniTesK показывает, что уровень переиспользования для тестирования ядер разных операционных систем превышает 50%.
Автоматическая генерация тестов. Это главное достоинство новых инструментов; здесь они существенно опережают традиционные средства, поскольку используют не произвольные виды нотаций и методов моделирования и спецификации, а именно те, которые дают преимущества при автоматической генерации тестов. Так, утверждения позволяют сгенерировать тестовые «оракулы» — программы для автоматического анализа корректности результата; различные виды конечных автоматов или их аналоги позволяют сгенерировать тестовые последовательности. К тому же, поскольку модели обычно проще, чем реализации, для них удается провести более тщательный анализ, поэтому набор тестов становится более систематическим.
Рассмотренные инструменты опробованы на реальных, масштабных проектах. Конечно, каждый проект несет в себе некоторую специфику, возможно, препятствующую исчерпывающему тестированию. Однако опыт использования данных инструментов показывает, что обычно удается достичь хороших результатов, лучших, чем результаты, полученные в аналогичных проектах при помощи ручного тестирования. Пользователи UniTesK, обычно, за приемлемый уровень качества принимают 70-80% покрытия кода целевой системы; при этом должен быть удовлетворен, как минимум, критерий покрытия всех логических ветвей в постусловиях. Для некоторых сложных программ (в том числе, для блока оптимизации компилятора GCC) был достигнут уровень покрытия 90-95%.
Есть ли принципиальные ограничения в применимости данного подхода? Его практически невозможно применять в случае, когда по той или иной причине никто в цепочке заказчик — разработчик — тестировщик не смог или не захотел четко сформулировать требования к целевой системе. Впрочем, это не только ограничение, но и дополнительный стимул для улучшения процессов разработки, еще один повод объяснить заказчику, что вложения в фазу проектирования с лихвой окупаются сокращением общих сроков разработки и стоимости проекта.
- Уокер Ройс. Управление проектами по созданию программного обеспечения. М.: Лори, 2002.
- Г. Майерс. Надежность программного обеспечения. М.: Мир, 1980.
- Элфрид Дастин, Джефф Рэшка, Джон Пол. Автоматизированное тестирование программного обеспечения. Внедрение, управление и эксплуатация. М.: Лори, 2003.
- Everette R. Keith. Agile Software Development Processes: A Different Approach to Software Design.
Александр Петренко, Елена Бритвина, Сергей Грошев, Александр Монахов, Ольга Петренко ({petrenko, lena, sgroshev, monakhov, olga}@ispras.ru) — сотрудники Института системного программирования РАН (Москва).
Рис. 2. Спецификационные расширения языков программирования на примере спецификации требований к методу sqrt, вычисляющему квадратный корень из своего аргумента
Обозначения элементов общей структуры спецификации метода:
S — Сигнатура операции
A — Спецификация доступа
< — Предусловие
B — Определение ветвей функциональности
> — Постусловие
Java:
Class SqrtSpecification {
S Specification static double sqrt(double x)
A reads x, epsilon
{
< pre { return x >= 0; }
post {
> if(x == 0) {
B branch «Zero argument»;
> return sqrt == 0;
> } else {
B branch «Positive argument»;
> return sqrt >= 0 &&
> Math.abs((sqrt*sqrt-x)/x) }
}
}
}
Си:
S specification double SQRT(double x)
A reads (double)x, epsilon
{
< pre { return x >= 0.; }
coverage ZP {
if(x == 0) {
B return(ZERO, «Zero argument»);
} else {
B return(POS, «Positive argument»);
}
}
post {
> if(coverage(ZP, ZERO)) {
> return SQRT == 0.;
> } else {
> return SQRT >= 0. &&
> abs((SQRT*SQRT — x)/x) < epsilon;
> }
}
}
C#:
namespace Examples {
specification class SqrtSpecification {
S specification static double Sqrt(double x)
A reads x, epsilon
{
< pre { return x >= 0; }
post {
> if(x == 0) {
B branch ZERO («Zero argument»);
> return $this.Result == 0;
> } else {
B branch POS («Positive argument»);
> return $this.Result >= 0 &&
> Math.Abs( ($this.Result *
$this.Result — x)/x) < epsilon;
> }
> }
> }
}
}
