Существующие подходы к анализу текстов можно разбить на два класса. К первому классу относятся простые, быстрые, не зависящие от языка и предметной области, но грубые механизмы анализа; чаще всего это подходы, использующие статистические методы. Второй класс формируют достаточно изощренные, дающие хороший результат, но сравнительно медленные подходы, зависящие от языка и предметной области; обычно они основаны на лингвистических методах. Эффективным можно считать такой подход, который сочетал бы в себе быстроту и независимость от языка алгоритмов первого класса с высоким качеством обработки второго.
Предлагаемый подход к анализу текстовой информации реализован на основе однородной нейросетевой (а потому статистической) обработки информации, обладает достаточным быстродействием и не зависит от языка и предметной области, но при этом, в отличие от большинства алгоритмов обработки текстов, реализованных на основе статистического подхода, дает хорошие результаты. Так, по данным ведомственной экспертизы представленный подход, реализованный в системе TextAnalyst, признан лучшим в реализации одной из важных функций обработки текстов — построения рефератов — в сравнении с подходом, реализованным, например, на основе лингвистических алгоритмов норвежской компании CognIT [1].
Возможности технологии
В существующих системах обработки информации обычно реализуются следующие основные возможности обработки текстовой информации: выделение из текста ключевых слов, построение реферата, формирование гипертекстовой структуры, эффективная навигация по тексту, сравнение (классификация) текстов, таксономия множества текстов на рубрики, эффективное представление информации пользователю [2]. Предлагаемый подход позволяет реализовать все эти функции.
В результате анализа текста из него автоматически извлекается индекс в виде сети основных понятий и их связей с весовыми характеристиками. В качестве смыслового портрета текста рассматривается не просто список ключевых слов, а сеть понятий — множество ключевых слов или устойчивых словосочетаний связанных между собой. Каждое понятие имеет некоторый вес, отражающий значимость этого понятия в тексте. Связь между понятиями тоже имеет вес. Использование связей позволяет более точно взвешивать понятия текста.
Структурный портрет текста (смысловая сеть) может быть построен и для одного текста, и для любого их множества. Общая сеть понятий, построенная на множестве текстов, относящихся к одной предметной области-рубрике, используется для навигации по рубрике, а также для сравнения с сетями входных текстов при их классификации. Минимальный древовидный подграф семантической сети представляет собой тематическое дерево, которое, как и семантическая сеть, описывает содержание текста, а также позволяет осуществлять навигацию по тексту. Тематическое дерево больше похоже на оглавление текста. Исходный текст (множество текстов) вместе с их семантической сетью представляет собой гипертекстовую структуру и является одновременно хранилищем текстов и базой знаний. Семантическая сеть может быть использована для автоматического разбиения множества текстов на подмножества — таксономии. При этом группы текстов формируются с учетом заложенной в текстах тематической структуры.
Сравнение семантической сети входного текста с семантическими сетями рубрик (классификация) позволяет сделать вывод о принадлежности текста к тематике одной или нескольких рубрик. В результате классификации осуществляется связывание входного текста с одной или несколькими рубриками, определяемыми пользователем, или с рубриками, полученными при таксономии.
Семантическая сеть формирует метрическое пространство, в котором текст и любое его предложение являются векторами. Выбирая наиболее существенные векторы в этом пространстве (предложения), можно автоматически построить реферат. Используя только часть сети, описывающую некоторую тему, можно построить реферат и для заданной темы текста (тематический реферат) в виде последовательности наиболее значимых для заданной темы предложений текста. Выбор подсети, связанной с некоторым понятием или группой понятий, позволяет осуществить смысловой подбор текстов (ассоциативный поиск) на заданную тему.
Анализ динамики тематических таксонов (рубрик), сформированных автоматически, позволяет определять появление нового события или темы в потоке информации (тематическую динамику).
Нейросетевая основа
В основе обработки текстовой информации лежит нейросетевая технология [3], единая для обработки информации разных модальностей: текстовой [5], речевой [6], зрительной [7]. При обработке информации разных модальностей меняется только способ выделения первичных признаков, а при обработке текстовой информации дополнительно вводится лишний этап обработки — перенормировка весов слов.
Нейросетевая технология обработки информации базируется на двух фундаментальных посылках.
- Информация представляется в виде одномерной последовательности символов. Предпринимаются специальные усилия для приведения ее к такому представлению. Например, для зрительной информации осуществляется выделение точек изображения, несущих наибольшие сведения, затем производится сканирование их последовательности в определенном порядке, что приводит к формированию некоторой информационной последовательности. Для речи подобные преобразования проще, поскольку она изначально одномерна; то же и с текстами.
- Далее эта одномерная информационная последовательность отображается в многомерное сигнальное пространство с помощью окна длиной в n символов таким образом, что каждые n символов являются координатами точки в этом пространстве. А всей последовательности соответствует траектория - последовательность точек в этом пространстве. Такое отображение позволяет восстанавливать внутреннюю структуру входной информации, если такая там имеется. Дело в том, что это отображение ассоциативно по своей природе. Как только окно заполнено, оно сразу адресует нас к соответствующей точке пространства. Допустим, входная последовательность имеет повторяющиеся фрагменты, например, слова. Тогда, при появлении в последовательности слова, которое уже ранее встречалось, траектория циклически проходит по своему фрагменту, соответствующему этому слову. Если имеется механизм памяти, фиксирующий число прохождений траекторией через заданную точку пространства, а также пороговое преобразование (т.е. преобразование вида: а = 1, если b > h, и а = 0, если b < h, где h - порог), мы в состоянии устранить из рассмотрения точки траектории, которые встречаются нечасто и сохранить точки, встречающиеся часто. После такого отсева в сигнальном пространстве остается лишь информация, касающаяся повторяющихся фрагментов последовательности - слов словаря заданного уровня.
После формирования такого словаря его можно использовать для фильтрации старой информации в потоке сообщений. Такой фильтр пропускает на выход только новую информацию, которая формирует новую последовательность. Она похожа на старую, с той разницей, что места в ней, которые соответствовали старой информации, заменяются нулями. Эта последовательность связей слов подвергается обработке на следующем уровне, и формирует словарь уже этого уровня. И так далее. При этом связи слов словаря нижнего уровня учитываются в словах словаря следующего уровня.
В случае обработки текстов алгоритм несколько упрощается; остается только два уровня анализа. При этом сохраняется основная цель — сформировать словарь слов и выявить связи между ними, поэтому на первом шаге формируется словарь слов. Но на втором шаге, вместо формирования последовательности аббревиатур путем фильтрации слов словаря, сформированного на первом уровне, анализируется попарная встречаемость слов в предложениях. Таким образом, выявляются связи между словами. Полученная информация представляет собой частотный портрет текста, который может быть визуализирован в виде сети слов словаря и их связей. Причем, и слова словаря, и их связи получают в результате анализа некоторые частотные характеристики.
Для обработки текстов, в отличие от речи и видео, вводится еще одна операция — перенормировка числовых характеристик слов. Для этого используется итеративный алгоритм работы нейронных сетей Хопфилда [4]. На каждой итерации слово сети увеличивает свой вес, если оно оказывается связанным со многими другими словами с большим весом, а другие слова его равномерно теряют. Так, если слово встретилось дважды — в заглавии и в аннотации, оно является ключевым понятием и может приобрести очень большой вес.
Пример обработки текста
Рассмотрим функциональность технологии на примере обработки текста сказки «Репка».
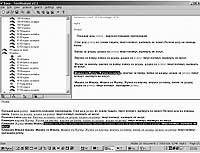 |
 |
| Рис. 1. Смысловая сеть текста | Рис. 2. Тематическая структура текста |
|
|
 |
| Рис. 4. Реферат | Рис. 3. Тематическая структура текста с мышкой |
|
|
 |
| Рис. 5. Тематический реферат на тему «мышка» | Рис. 6. Пример разбиения сети на подтемы |
На рис. 1 представлена семантическая сеть текста и предложения текста, содержащие понятие «репка», а также отсылка к одному из этих предложений в исходном тексте (нижнее окно). Еще очевиднее тематическая структура (рис. 2).
Отсутствие «мышки» восполняется введением этого слова в словарь предпочтений пользователя. После повторного анализа мышка занимает свое место в иерархии (рис. 3). И, наконец, составляется реферат (рис. 4). Тематический реферат на тему «мышка» приведен на рис. 5. Тематическое дерево может быть разбито на поддеревья увеличением порога по визуализируемым связям (рис. 6).
Выделяются три подтемы — «мышка» (поскольку это понятие было введено в словарь предпочтений пользователя), «бабка», и «дед с репкой».
Приведенный анализ позволяет прокомментировать возможности программы TextAnalyst, разработанной научно-поизводственным инновационным центром «Микросистемы». Самое первое наблюдение показывает, что малый объем анализируемой информации не способствует проведению качественного анализа. Однако хорошая структура текста позволяет выявить основные связи. Внесение априорной информации способно улучшить качество анализа. Программа позволяет достаточно корректно извлечь минимально необходимую для представления ситуации информацию, как в виде семантической сети, так и в виде последовательности предложений текста, несущих основную смысловую нагрузку. Такую же информацию можно извлекать для отдельно выбранной темы. Смысловая сеть может быть разбита на подсети, соответствующие отдельным подтемам.
Возможные приложения
Решения для поиска информации в Web. Данная технология позволяет при помощи поисковых агентов автоматически подобрать информацию по заданной теме и создать базу знаний. Web используется как глобальное хранилище знаний. Технология поисковых агентов позволяет осуществить тематически направленный сбор информации в Internet и формирование базы знаний. Построение базы знаний начинается с темы, которая может быть задана одним-двумя словами. При поиске она обрастает смысловыми дополнениями (они получаются за счет расширения ассоциациями на ассоциативной сети), по которым агенты тоже собирают информацию.
Персонификация процесса сбора и анализа информации. Сформированная персональная база знаний пользователя становится своеобразным фильтром, позволяющим повысить точность выполнения таких операций как поиск в Internet и мониторинг новой информации. При этом определяются и учитываются предпочтения пользователя. Во время поиска информации в Internet специальный агент просматривает содержимое страниц, на которые заходит пользователь, считывает с них информацию и помещает в персональную базу знаний пользователя, в которой на верхних уровнях восстанавливаются его основные интересы и предпочтения. Используя персональную базу знаний, агенты могут автоматически собирать новую информацию, отвечающую интересам пользователя. Персонифицированная фильтрация позволяет автоматически выбрать только ту информацию, которая может оказаться интересной.
Полнотекстовые библиотеки. Ассоциативная сеть может быть использована, наряду со стандартными рубриками, для навигации по базе текстов.
Фильтрация текстов. Такая система может использоваться с целью «не выпускать» или «не впускать» сообщения, например для недопущения утечки конфиденциальной информации. Она же может использоваться для классификации текстов по рубрикам (адресатам).
Оболочка для электронных книг. Гипертекстовое представление удобно для создания электронных книг [8].
Заключение
Программа TextAnalyst позволяет автоматически сформировать смысловой портрет текста в виде ассоциативной сети основных понятий с их связями, помеченными их числовыми характеристиками. Семантическая сеть совместно с исходным текстом представляют собой гипертекстовую структуру, на которой семантическая сеть играет роль эффективного средства навигации. Разбиение сети множества текстов на подсети производит автоматическую таксономию множества текстов по рубрикам. Сравнение семантических сетей текстов позволяет выявить степень корреляции между текстами, а сравнение семантических сетей входного текста и рубрик — отнести текст к одной из рубрик. Элементарно строится реферат текста. Так же просто строится тематический реферат и осуществляется смысловой поиск на множестве текстов. Поскольку нейросетевая технология реализует специфический статистический анализ, обработка текста не зависит от предметной области и от языка, выполняется быстро и не требует дискового пространства. В настоящее время TextAnalyst поддерживает семь языков, включая китайский.
Литература
- Landau D., Feldman R., Aumann Y., Fresko M., Lindell Y., Lipshtat O., Zamir O. TextVis: An Integrated Visual Environment for Text Mining. In Proc. of the 2nd European Symp. on Principles of Data Mining and Knowledge Discovery (PKDD '98), Lecture Notes in Artif. Intell. 1510, pp. 5664. Springer-Verlag, 1998
- Dan Sullivan. Document Warehousing and Textmining. NY; Wiley publishing house, 2001
- Харламов А.А. Ассоциативный процессор на основе нейроподобных элементов для структурной обработки информации. // Информационные технологии, 1997, № 8, - с. 40-44
- Hopfield J.J. Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. 79, 1982. - p. 2554-2558
- Харламов А.А., Ермаков А.Е., Кузнецов Д.М. Технология обработки текстовой информации с опорой на семантические представления на основе иерархических структур из динамических нейронных сетей, управляемых механизмом внимания. // Информационные технологии, 1998, № 2, - с. 26-32
- Харламов А.А. Динамические рекуррентные нейронные сети для представления речевой информации. // Информационные технологии, 1997, № 10, - с. 16-22
- Харламов А.А., Жаркой Р.М., Волков В.И., Мацаков Г.Н. Система распознавания изолированных рукописных символов на основе иерархической структуры из динамических ассоциативных запоминающих устройств. // Информационные технологии, 1998, № 5. - с. 27-31
- Харламов А.А., Ермаков А.Е., Кузнецов Д.М. Технология обработки текстовой информации с опорой на семантические представления на основе иерархических структур из динамических нейронных сетей, управляемых механизмом внимания. // Информационные технологии, 1998, № 2, - с. 26-32
Александр Харламов (kharlamov@analyst.ru) — сотрудник Института высшей нервной деятельности и нейрофизиологии РАН (Москва).
Средства анализа текстов
IBM Intelligent Miner for Text. Эта файлово-ориентированная система использует статистический и эвристический подходы к анализу текстов. Включает пять программ, запускаемых независимо друг от друга [2]: идентификатор языка; экстрактор характеристик; аннотатор; категоризатор; кластеризатор. Идентификатор языка использует для анализа характерные для языка части слов. Экстрактор характеристик извлекает из текста термины, имена, отношения, многословные термины, даты и выражения, обозначающие время. Для их извлечения используются специальные языковые эвристики. С целью увеличения корректности обработки пользователь может создавать персональный словарь. Аннотатор работает с помощью ранжирования слов и использует для этого слова, содержащиеся в названиях документа и заголовках, а также, статистику появления слов в сочетании со статистикой этих слов в персональном словаре пользователя. В отличие от других программ, категоризатор должен быть обучен перед использованием. Для этого предварительно статистически обрабатывается выборка текстов на заданную тему, а с целью более корректной оценки тематики выборки применяется морфологический анализ. Сформированная тематическая схема далее используется при анализе текстов для их категоризации. Кластеризатор не требует обучения и поддерживает два типа кластеризации: иерархическую и бинарных отношений (попарных связей). Первая формирует древовидную структуру, листья которой соответствуют отдельным документам, а ветви объединяют документы в более крупные множества, иерархически вложенные друг в друга. В бинарной кластеризации каждый документ может содержаться только в одном кластере, а кластеры могут связываться между собой на основе общности характеристик, выделенных экстрактором.
Oracle interMedia Text. В отличие от IBM Intelligent Text Miner, Oracle interMedia Text использует для анализа тексты, хранящиеся в базе данных, а потому, расширяет стандартный инструментарий Oracle и интегрирован в него. Это позволяет использовать метаданные из базы для обработки текстов. Основной упор в interMedia Text сделан на предобработке текстов и поиск, зато отсутствует кластеризация. Основные операции с текстами: загрузка; индексация; поиск. Загрузка выполняется стандартным для реляционных баз данных способом и поддерживает все основные форматы. Индексация реализуется как полнотекстовая, так и тематическая. Для выполнения индексации документы конвертируются в формат HTML. Тематическая индексация осуществляется на основе таксономии концептов и использует предварительно подготовленную базу знаний по нескольким областям: наука и техника, бизнес и экономика, правительство и армия, социальные структуры, география, а также абстрактные идеи и концепты. База знаний содержит семантические представления для широкого круга терминов, использует стандартные связи тезауруса, в том числе расширяющие термины, сужающие термины и присоединяющие термины. База знаний может быть расширена предметно-зависимыми тезаурусами. Далее, как и в Intelligent Miner for Text, для категоризации текста используется статистический подход. Качество разметки усиливается за счет использования связей между терминами в семантических представлениях. Функция поиска интегрирована в базу данных и реализует две опции: собственно поиск и ранжирование. Поиск может быть простым, по нескольким терминам, по расширяющим, сужающим и предпочтительным терминам. Кроме того, можно включить: нечеткий поиск, игнорирующий ошибки при написании; поиск, учитывающий морфологию; поиск, ищущий по аналогии звучания; многоязычный поиск; поиск по положению (около, внутри группы слов).
