Задачи обработки информации с нечетко определенной структурой возникают сегодня практически повсеместно. От того, как будет организована работа с такими данными, зависит эффективность хранения и извлечения информации в электронных библиотеках и корпоративных хранилищах.
Задачи обработки информации, структура которой определена не полностью, возникают сегодня в самых разных областях. Примером могут служить корпоративные каталоги данных, которые составляют основу большинства современных информационных систем, интегрируя различные бизнес-приложения в единое информационное пространство и обеспечивая сохранение и доступность информации для различных групп пользователей.
Еще одним примером могут служить электронные библиотеки и электронные коллекции. Назначение систем такого рода как раз и состоит в том, чтобы хранить разнородные информационные ресурсы. При этом задача описания структуры данных может решаться как на системном уровне, так и на уровне конечного пользователя. Гибкость описания разнородных данных определяет эффективность хранения и извлечения информации в электронной библиотеке. Общим для всех таких систем является наличие каталога данных или каталога объектов. Обычно основными частями каталога являются система поддержки метаданных и система хранения и извлечения данных.
Системы поддержки метаданных обеспечивают адекватное моделирование и описание информации как на уровне описания отдельных сущностей (объектов), так и на уровне описания структуры всего каталога. Метаописания задают специфику занесения, поиска и извлечения данных. Известно множество разнообразных подходов к построению систем управления данными с разной степенью структурированности [3, 6, 8, 11, 18, 19, 20, 21, 22]. Подобные системы реализуются на основе различных технологий. Самой популярной платформой для обработки данных сегодня остаются реляционные СУБД [1, 2]; между тем, реляционная модель не предусматривает встроенных средств работы с разнородными данными.
Постановка задачи
Что мы понимаем под квазиструктурированными (полуструктурированными) данными? Обычно речь идет об информации, в которой можно выделить ту или иную структуру, однако структура эта заранее целиком или частично неизвестна, либо может меняться с течением времени. Возможно несколько вариантов.
- Данные, структура которых даже априорно неизвестна. В этом случае формирование структуры каталога данных и его заполнение происходит одновременно по мере поступления информации. Примером может служить набор, произвольным образом связанных документов в различных форматах с произвольными описаниями каждого документа.
- Структура данных известна частично. Известны основные описания базовых сущностей или классов системы; вместе с тем имеется необходимость хранения и обработки заранее неопределенной дополнительной информации. Так, информация о покупателях или продавцах, может сопровождаться набором примечаний о каждой сделке, контактными телефонами, дополнительным условиями и т.д.
- Структура данных известна и четко определена, но может меняться с течением времени. Простейшим примером может служить набор реквизитов счета-фактуры или реквизитов организации, которые меняются с изменением законодательства.
Подобная достаточно условная классификация построена по принципу «усиления» четкости структуры информации; вместе с тем, она отражает характерные задачи обработки полуструктурированных данных.
Исследования систем обработки слабоструктурированных данных и языков запросов к ним ведутся достаточно давно. В качестве примера можно назвать систему Lore с языком запросов Lorel [6, 7] или систему интеграции данных из гетерогенных источников YAT [9, 10, 11]. Заложенные в Lore идеи нашли продолжение во многих системах обработки разнородных данных. Разработан ряд языков запросов к слабоструктурированным данным: XML-QL [12, 14], XQL [15], Quilt [16, 17], X-Query [13]. Подробные обзоры этих технологий можно найти в [4, 5].
Реляционные системы эффективно обрабатывают данные, описанные в терминах отношений и их связей. При этом метаданные в виде описаний отношений, атрибутов отношений, первичных и вторичных ключей, поддерживаются на системном уровне СУБД. Увы, достоинства слишком часто являются «причиной всех недостатков». В «классическом» варианте реляционной СУБД поддержка слабоструктурированных данных не предусмотрена: в рамках реляционной алгебры описать их невозможно. Для их моделирования необходим прикладной уровень — надстройки над СУБД, которые позволяли бы решить задачи моделирования и обработки разнородной информации; в свою очередь эти надстройки должны использовать только стандартные средства реляционных систем.
Система моделирования
Модель OEM
В рамках проекта Lore использована модель представления данных OEM (Object Exchange Model), разработанная в ходе исследований по проекту Tsimmis [23, 24]. Заложенные в модели OEM идеи с теми или иными модификациями используются практически во всех системах управления слабоструктурированными данными. Информация в OEM-структуре представляется в виде графа с именованными ребрами, а узлы соответствуют объектам. Для определенности будем называть их node-объектами или n-объектами. В простейшем варианте они могут быть атомарными или контейнерами. Атомарные n-объекты имеют только входящие связи и значение определенного типа, но не имеют зависимых объектов. У контейнеров нет значений, но есть зависимые объекты (исходящие связи). Каждый n-объект имеет уникальный идентификатор. На связи между ними, в общем случае, не накладывается никаких ограничений. На рис. 1 приведен фрагмент ОЕМ-базы данных.
Метаданные в ОЕМ-структуре определяются данными и формируются по мере возникновения самих данных. Семантическая информация хранится в самой структуре базы данных. Универсальность подхода позволяет легко моделировать информацию произвольной структуры. Возьмем эту модель в качестве отправной точки и построим на ее основе систему моделирования и хранения полуструктурированных данных.
Проще всего OEM-структуру реализовать в виде двух основных таблиц — таблицы n-объектов и таблицы связей и набора вспомогательных таблиц значений (см. рис. 2a).
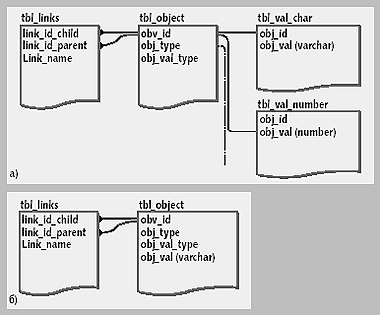
|
| Рис. 2. Схема данных для ОЕМ-структуры: а) значения объектов каждого типа в отдельных таблицах; б) все значения объектов приведены к символьному типу |
Таблица объектов tbl_object содержит список n-объектов — вершин графов OEM-структуры. В простейшем варианте каждый из них имеет уникальный идентификатор и тип, который может принимать два значения: контейнер и атомарный. Таблица связей tbl_links описывает связи между n-объектами — ребра графов. Имя связи и набор идентификаторов родительского и зависимого n-объектов образуют первичный ключ таблицы связей. Значения n-объектов хранятся в таблицах значений, в каждой таблице — значения своего типа. Выбор таблицы, в которой хранится значение, определяется атрибутом obj_val_type таблицы объектов. Часто значения всех n-объектов приводят к строковому типу. Это позволяет хранить их непосредственно в таблице tbl_object, для чего в нее необходимо добавить атрибут obj_val, обычно имеющий тип varchar. Приведение типов в этом случае обеспечивается прикладными задачами и основывается на атрибуте tbl_object.obj_val_type (см. рис. 2б).
С помощью такого подхода можно моделировать данные любой структуры и сложности. Вместе с тем, отсутствие явной метаинформации затрудняет ввод, извлечение и обработку данных, имеющих сходное семантическое описание. То же самое можно сказать и о данных с «размытой» структурой, когда описание одной части информации строго детерминировано, а другой — заранее не определено. Дополнительная метаинформация необходима пользователям и приложениям для представления о структурах данных, которые могут храниться в базе данных. Она необходима для определения набора возможных/обязательных n-объектов, их значений, связей между ними.
В качестве простейшего примера может служить информация о клиентах, где всегда можно выделить общие атрибуты, часть из которых должна быть обязательно обработана. Покупатели, являясь в свою очередь клиентами, также имеют общие (только для покупателей) атрибуты. Для корректного ввода данных о клиентах, покупателях, продавцах необходимо знать набор атрибутов, которые необходимо или желательно заполнить. При извлечении данных также необходима информация о наборе атрибутов. Вместе с тем, эти правила не должны накладывать ограничения на ввод произвольных атрибутов с произвольными значениями, поскольку каждый клиент, в том числе и покупатель, может иметь индивидуальную информацию.
Поэтому предложенную схему необходимо модифицировать с целью введения дополнительного метаописания данных, не теряя при этом гибкости моделирования неструктурированной информации.
Каталог объектов
Применительно к ОЕМ-структуре дополнительная метаинформация должна описывать предопределенные семантические связи между n-объектами. Вариантов организации таких связей достаточно много. Рассмотрим один из них, связанный с преобразованием ОЕМ-базы данных в своеобразный каталог слабоструктурированных объектов. Несложно видеть, что в терминах «объектного» моделирования n-объекты — контейнеры соответствуют экземплярам какого-либо класса, а атомарные n-объекты соответствуют атрибутам экземпляров класса. Добавим в схему данных возможности формального определения классов; фактически речь идет о создании каталога классов.
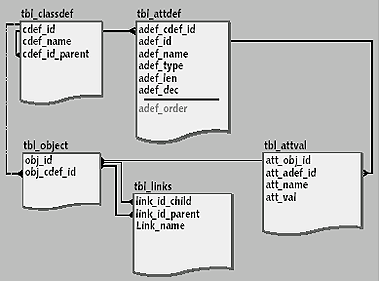
|
| Рис.3. Расширенная реляционная схема для обработки квазиструктурированых данных |
Создадим в схеме данных две таблицы описаний классов и их атрибутов соответственно (рис. 3). Таблица описаний классов tbl_classdef состоит всего из трех атрибутов и определяет иерархию классов, необходимую для моделирования данных. Атрибут tbl_classdef.cdef_id является идентификатором класса. Tbl_classdef.cdef_id_parent определяет отношения наследования в иерархии классов. Таблица tbl_attdef определяет атрибуты классов.
Возможно два варианта заполнения таблицы tbl_attdef. Предположим, что класс Cn является родительским для класса Cn1. В первом случае для определения класса Cn1 таблица tbl_attdef содержит только определения атрибутов, отличающие его от определения родительского класса Cn. Чтобы получить полный список атрибутов класса Cn1 необходимо получить список всех атрибутов для всех классов вверх по иерархии, начиная с определения Cn1. Таким образом, все изменения в определениях родительских классов автоматически становятся доступны для классов наследников. Идентификатор атрибута adef_id будет одинаковым для всех классов в иерархии. Каждому атрибуту соответствует одна запись в таблице tbl_attdef.

|
| Рис. 4. Первый вариант описания атрибутов класса |
Класс A является родительским для класса C, от которого в свою очередь произведен класс D (рис. 4). Соответственно классу A принадлежат атрибуты с идентификаторами 01, 02; классу C — 01, 02, 05; классу D — 01, 02, 05, 06, 07.
Второй вариант предусматривает, что таблица tbl_attdef содержит полное описание атрибутов для каждого класса. Необходимость такого подхода может возникнуть при наличии у атрибутов классов индивидуальных признаков, которые могут отличаться у родительских и порожденных классов. В качестве примера можно привести порядок следования атрибутов в определении класса, что важно, например, при описании XML-документов. Такая необходимость может также возникнуть при переопределении атрибутов, увеличении длины строковых атрибутов для порожденных классов и т.д. Целостность иерархии классов в этом случае необходимо поддерживать искусственно, посредством написания соответствующих триггеров для таблицы tbl_attdef. Описание атрибутов, определенных для Cn, должно повторяться для Cn1. Вместе с тем, являющийся первичным ключом идентификатор adef_id должен изменяться для одного и того же атрибута при перемещении по иерархии классов (для Cn и Cn1 он должен быть разным). Таким образом, необходимо также обеспечить идентификацию для наследуемых атрибутов вдоль иерархии классов. Это можно сделать, добавив в таблицу tbl_attdef дополнительный атрибут adef_id_parent, значение которого заполняется при первом определении атрибута (в этом случае adef_id_parent = adef_id) и остается неизменным для соответствующих атрибутов классов наследников (рис. 5). Таблица tbl_attdef содержит описание всех атрибутов для каждого класса.
Далее рассмотрим схему хранения данных (рис. 3). Вынесем значения атрибутов в отдельную таблицу, разгрузив тем самым таблицу объектов. Каждая запись tbl_object теперь соответствует объекту каталога и контейнеру в первоначальной OEM-схеме. Далее для определенности объекты каталога будем назвать k-объектами. В таблице объектов содержится ссылка на определение класса, экземпляр которого описывает запись (атрибут obj_cdef_id). Таблица связей описывает только отношения между k-объектами, поскольку связи между k-объектами и атрибутами описаны теперь в таблицах определения классов. Значения атрибутов содержатся в таблице tbl_attval, причем ее записи соответствуют только тем атрибутам k-объектов, для которых определены значения.
Каким же образом достигается гибкость описания разнородных данных в, казалось бы, жестко определенной структуре, с явными описаниями определений классов? Для этого достаточно разрешить определять k-объекты без указания класса, т.е. не определяя значение tbl_obect.obj_cdef_id. Аналогично можно поступить и с атрибутами, разрешив добавлять произвольные записи в таблицу tbl_attval с неопределенным значением атрибута tbl_attval.att_adef_Id, указывающего на соответствующую запись в таблице атрибутов классов. На рис. 3 эти связи показаны пунктиром.
Таким образом, можно создавать k-объекты неопределенной структуры с произвольным набором атрибутов или добавлять произвольные атрибуты к k-объектам заранее определенных классов. Разумным также представляется привести значение всех атрибутов k-объектов к строковому типу. С одной стороны, это не запрещает производить операцию приведения типа согласно определениям в tbl_attdef, с другой — придает универсальность и дополнительные возможности при описании нестандартных данных. Предложенную схему можно еще более расширить, добавив дополнительную типизацию связей объектов или установив дополнительные правила на порядок следования значений атрибутов в k-объекте, в зависимости от конкретных требований к гибкости описания данных.
Каталог объектов, интегрированный с реляционной схемой
Реляционные системы эффективно обрабатывают отношения с установленными связями. В рамках реляционной модели можно описать информацию любой заранее известной структуры. Логично было бы использовать в каталоге объектов все преимущества реляционной модели для структурированной части информации, не теряя возможностей системы по обработке неструктурированных данных. Это позволило бы интегрировать и повторно использовать уже имеющиеся в реляционной среде данные различных информационных систем и при этом оптимизировать доступ к информации.
Фактически речь идет о том, чтобы описать в объектном виде реляционную схему. Для решения этой задачи необходимо установить семантические связи между атрибутами реляционных таблиц и атрибутами классов, описанных в каталоге объектов. Это можно сделать, представив набор атрибутов класса в виде идентифицируемого набора кортежей из разных отношений [8]. Несложно видеть, что при определенной и заранее известной структуре данных, в таком виде можно представить определение любого класса. Так, k-объект «заказ» можно представить в виде набора кортежей из отношений «накладные», «список товаров», «клиенты», «параметры заказа», «менеджеры» и т.д. В каждом отношении каждому k-объекту будут соответствовать один или несколько кортежей, причем одно отношение может содержать кортежи, относящиеся к разным k-объектам разных классов; k-объекты «покупатель» и «продавец» могут ссылаться на кортежи одного и того же отношения «клиенты».
Известная трудность возникает при установке ссылок атрибутов k-объектов на атрибуты таблиц. Предположим, что каждый k-объект типа «заказ» имеет атрибут «покупатель», который хранится в реляционной таблице tbl_cust. Логично предположить, что каждой записи в tbl_cust будет соответствовать только один экземпляр класса «заказ», так как в этом случае данные экземпляров класса будут независимы друг от друга. При необходимости сослаться на одного клиента из разных объектов можно создать в каталоге объектов класс «клиент» и ссылаться на один и тот же экземпляр этого класса из разных k-объектов типа «заказ». При этом по прежнему одна запись tbl_cust соответствует одному объекту класса «клиент». Такой подход является «правильным», но часто неприменимым на практике. В реляционных таблицах он приводит к дублированию записей, что неприменимо при использовании данных из реальных баз данных, на основе которых уже функционируют приложения.
Эти трудности можно устранить, разрешив ссылки различных k-объектов на один и тот же кортеж таблицы. Минусом такого решения является то, что значения атрибутов различных объектов становятся зависимыми друг от друга. Так, при изменении данных какого-либо менеджера фактически изменятся атрибуты всех объектов класса «заказ», которые ссылаются на эту запись. Вместе с тем, появляется возможность интеграции любых реляционных таблиц в каталог объектов. Таким образом, необходимо описать реляционную схему в каталоге объектов и установить реляционные связи типа «много ко многим» между списком объектов tbl_object и таблицами данных. Заметим, что ссылка «одна запись — один объект» является частным случаем этого отношения.
Для установления связей необходимо наличие первичных ключей во всех таблицах данных и формирование дополнительных таблиц ссылок объектов на кортежи таблиц данных. В качестве примера на рис. 6 приведена часть реляционной схемы, описывающей заказы и часть таблиц каталога объектов. Таблицы связи score_link, pay_link, cust_link формируют взаимные ссылки k-объектов и соответствующих записей таблиц данных.
Для описания в каталоге объектов ссылок на таблицы данных необходимо модифицировать структуру таблицы tbl_attdef. Добавим в нее атрибут adef_tblname. Запись в tbl_attdef теперь может описывать и атрибут некоторого отношения, имя которого и определяется adef_tblname. Если adef_tblname не определено, следовательно, значение атрибута хранится в tbl_attval. Таким образом, объединение кортежей разных отношений в дополнительную логическую структуру объекта требует существования в каждой таблице данных первичного ключа, и, следовательно, не нарушает исходную реляционную схему.
Извлечение данных
Есть несколько типичных задач, связанных с обработкой данных и запросами к ним. 1. Получить список объектов (и их атрибутов) по пути доступа. 2. Получить список объектов заданного класса. 3. Получить набор пар «атрибут-значение» для некоторого объекта. 4. Получить таблицу значений атрибутов для объектов заданного класса.
Все остальные задачи обычно являются комбинацией перечисленных. Что касается задач 2 и 3, то они решаются стандартными средствами любой реляционной базы данных с помощью несложных SQL-запросов. Например:
select * from tbl_object where obj_cdef_id=<ид. класса> select att_name, att_val from tbl_attval where obj_id=<ид. объекта>
При этом доступен весь спектр возможностей оптимизации таких запросов в реляционных СУБД.
В задаче 4 речь идет о формировании результирующего отношения, атрибуты которого соответствуют атрибутам класса, описанного в таблице tbl_classdef каталога объектов. Соответственно каждому k-объекту из каталога соответствует кортеж этого отношения, значения атрибутов должны соответствовать значениям из таблицы tbl_attval. На практике такое представление данных часто очень наглядно и удобно для обработки. Для реляционных СУБД формирование результатов запроса в виде некоторого представления таблиц — элементарная операция. К сожалению, решение этой задачи требует значительных усилий при формировании результирующей таблицы из предложенных схем данных. Так, для каталога объектов вначале необходимо получить необходимый набор объектов. Предположим, он существует в виде временной таблицы tmp_obj_list. Затем необходимо сформировать и выполнить запрос такого типа:
SELECT b.att_val as acode1, c.att_val as acode 2, d.att_val as acode3... FROM tmp_obj_list a LEFT OUTER JOIN tbl_attval b ON a.obj_id=b.obj_id tmp_obj_list a LEFT OUTER JOIN tbl_attval c ON a.obj_id=c.obj_id tmp_obj_list a LEFT OUTER JOIN tbl_attval d ON a.obj_id=d.obj_id ...
При достаточно большом количестве объектов в результирующей таблице tmp_obj_list или большом количестве атрибутов в выходном наборе такой запрос, несомненно, будет трудоемкой операцией для сервера баз данных. Повысить производительность выполнения запросов можно, применив, когда это допустимо, комбинированную схему каталога объектов. В этом случае запрос для примера на рис. 6 можно модифицировать:
SELECT b.*, c.att_val as acode 2, d.att_val as acode3... FROM tmp_obj_list a LEFT OUTER JOIN cust_link b INNER JOIN tbl_cust e ON e.cust_id=b.cust_id ON a.obj_id=b.obj_id tmp_obj_list a LEFT OUTER JOIN tbl_attval c ON a.obj_id=c.obj_id tmp_obj_list a LEFT OUTER JOIN tbl_attval d ON a.obj_id=d.obj_id ...
Здесь вместе с атрибутами объектов извлекается вся информация о клиентах.
Извлечение списка объектов по пути доступа для модели ОЕМ
Получение списка объектов по пути доступа, вообще говоря, нетривиально. Путь, как правило, представляет последовательный набор связей между n-объектами (ребер графа ОЕМ-модели), который начинается с некоторого n-объекта, объявленного точкой доступа (... .... .). Стандартным также является требование обработки путей доступа с шаблонами, как это сделано в большинстве языков запроса к слабоструктурированным данным [5, 7, 14, 15]. К сожалению, стандартными средствами реляционной модели эта задача не решается. Алгоритм извлечения данных необходимо реализовывать либо на уровне приложения, либо на сервере баз данных при помощи хранимых процедур. Вместе с тем, хотелось бы максимально использовать преимущества реляционной технологии для ее решения.
Одним из основных методов оптимизации запросов в системах обработки квазиструктурированных данных является построение путеводителей по данным, таких как DataGuides [23] в Lore. Путеводитель по данным представляет собой граф, построенный на основе OEM-схемы, обобщающий исходную базу данных. В DataGuides суммирована информация о связях между n-объектами. Каждый возможный путь в исходной базе данных существует в DataGuides, и, напротив, любому пути в DataGuides соответствует хотя бы один путь в исходной базе. Поэтому этот путеводитель может рассматриваться как индекс по всем возможным маршрутам в OEM-схеме (path index). На рис. 7 приведен фрагмент DataGuides. Размеры путеводителя по данным обычно значительно меньше размеров основной базы данных. Путеводитель сам представляет собой ОЕМ-структуру; это позволяет Lore хранить его как OEM-базу данных и обрабатывать стандартными средствами системы.
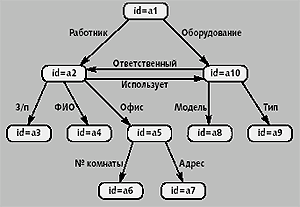
|
| Рис. 7. DataGuides для ОЕМ-базы из примера на рис. 1 |
После формирования DataGuides для каждого его объекта создают наборы идентификаторов n-объектов в исходной базе данных (target set), доступные по соответствующему пути в путеводителе. Так для объекта «a10» на рис. 7 набор идентификаторов будет равен «09, 10», для объекта «a4» — «03, 06, 07» и т.д. Далее формируют две таблицы ссылок: targetHash (таблица сформированных наборов идентификаторов); objectHash (таблица ссылок объектов исходной базы данных на объекты DataGuides, в наборах идентификаторов которых он содержится).
Алгоритм выполнения запроса с использованием DataGuides выглядит так.
- Определить наличие соответствующего пути в DataGuides.
- Если путь найден, найти соответствующую ссылку в таблице targetHash.
- Получить набор идентификаторов n-объектов.
- Получить набор значений n-объектов из набора идентификаторов, если это необходимо.
На практике важен частный случай ОЕМ-схемы, в которой все n-объекты объединены в иерархическую структуру: каждый n-объект имеет только одну входящую связь от n-объекта более высокого уровня и сколько угодно исходящих к n-объектам более низкого уровня. В этом случае можно объединить DataGuides и targetHash в одну таблицу, так как одной записи в targetHash соответствует только одни путь в DataGuides. Результирующая таблица (tbl_path) содержит все возможные пути от n-объекта — точки доступа ко всем объектам DataGuides и соответствующие им наборы идентификаторов.
С использованием tbl_path извлечение данных происходит в два этапа. Сначала на основе запроса из таблицы tbl_path формируется список n-объектов. При этом возможно использование шаблонов. Если на результирующий список необходимо наложить фильтр или требуется извлечь дополнительно все или некоторые атрибуты объектов, то это происходит по списку n-объектов, полученному на первом этапе. К недостаткам этого подхода следует отнести трудности использования tbl_path при больших уровнях вложенности n-объектов; это приводит к увеличению длины путей и, несомненно, сказывается на производительности. Достоинством же является простота поиска и эффективность извлечения данных по произвольному пути.
В целях оптимизации производительности можно искусственно выделить в исходной ОЕМ-структуре некую иерархию объектов, создав для нее tbl_path. Можно также создать несколько таблиц путей, каждую для связей между n-объектами только определенного типа (типов). Это увеличивает накладные расходы на поддержание нескольких таблиц, но может дать значительный выигрыш при поиске и извлечении данных.
Извлечение списка объектов по пути доступа для каталога объектов
Сказанное применимо и для каталога объектов (рис. 3); следует учитывать только, что в качестве узлов графа выступают объекты каталога (k-объекты). Вместе с тем наличие дополнительной метаинформации позволяет в этом случае применить дополнительные способы построения DataGuides. Рассмотрим один из возможных вариантов. Представим объект каталога в виде части ОЕМ-схемы (рис. 8). k-объект — экземпляр класса «персона» в ОЕМ-схеме представлен в виде графа с ребром «персона» и двух n-объектов (на рисунке они помечены как (a) и (b)). n-Объекты соединены единственной связью, соответствующей классу исходного к-объекта — «персона». Входящие связи n-объекта (а) соответствуют входящим связям исходного к-объекта. Идентификатор n-объекта (a) не определен. Идентификатор n-объекта (b) равен идентификатору исходного k-объекта. Из n-объекта (b) выходят связи исходного k-объекта, а также связи с именами атрибутов исходного k-объекта к атомарным объектам (их идентификаторы также не определены), которые имеют значения атрибутов исходного k-объекта «персона». Несложно видеть, что такое эквивалентное представление позволяет учесть класс исходного k-объекта непосредственно в ОЕМ-структуре. Он описывается связью между n-объектами (а) и (b).
Построим на основе этого эквивалентного ОЕМ-представления объектов каталога DataGuides. Поставим в соответствие каждому k-объекту граф, состоящий из:
- n-объекта (a) с неопределенным идентификатором, входящими связями исходного k-объекта и одной выходящей связью;
- n-объекта (b) с одной входящей связью, с исходящими связями исходного k-объекта и идентификатором, равным идентификатору исходного k-объекта;
- связи между n-объектами (a) и (b), соответствующей классу k-объекта.
Так как идентификатор n-объекта (a) не определен, не будем учитывать его при построении таблиц targetHash, objectHash. Это накладывает ограничения на пути, которые можно использовать для извлечения списка k-объектов. Каждый путь должен заканчиваться ребром, соответствующим классу k-объекта и все пары <входящая связь>.<тип объекта> («работник.персона» для рис. 8), указанные в пути, должны быть полными. Таким образом, DataGuides формируется с учетом метаинформации каталога объектов.
На практике часто все объекты каталога имеют имена, что облегчает для пользователей идентификацию объектов и навигацию по каталогу. В этом случае можно построить DataGuides, для которого связь между объектами (a) и (b) принимает значение имени k-объекта.
Важным является случай, в котором каталог объектов представляет собой иерархическую структуру с именованными объектами и неименованными связями. Для этого варианта каталога объектов DataGuides содержит только имена k-объектов, что значительно упрощает его структуру. Также для иерархических каталогов объектов возможно построение индекса путей (таблицы tbl_path), как это было описано для OEM-модели.
Литература
[1] Д. Мейер. Теория реляционных баз данных. М.: Мир, 1984
[2] Крис Дейт. Введение в базы данных. Изд. 6-е. Киев, «Диалектика», 1998
[3] Гради Буч. Объектно-ориентированное проектирование с примерами применений. М.: ИВК и Киев, «Диалектика», 1992
[4] М. Гринев. Системы управления полуструктурированными данными. // Открытые системы, 1999, №5-6
[5] А. Суслов. Языки запросов для XML-данных. // Открытые системы, 2001, № 2
[6] J. McHugh, S. Abteboul, R. Goldman, D. Quass, J. Widom. Lore: A Database Management System for Semistructured Data. www.ds.standford.edu/lore
[7] S. Abteboul, D. Quass, J. McHugh, J. Widom J.L. Wiener. The Lorel Query Language for Semistructured Data. www.ds.standford.edu/lore
[8] Е. Григорьев. Представления идентифицируемых сложных объектов в реляционной базе данных. // Открытые системы, 2000, № 1-2
[9] S. Cluet, S. Jacqmin, J. Simeon. The New YATL: Design and Specifications. Working draft
[10] S. Cluet, C. Delobel, J. Simeon, K. Smaga. Your Mediators Need Data Conversion! Proceedings of ACM-SIGMOD International Conference on Management of Data, 1998
[11] S. Cluet, J. Simeon. Data integration based on data conversion and restructuring, Technical report. Verso database group — INRIA, Oct. 1997
[12] A. Deutsch, M. Fernandez, D. Florescu, A. Levy, D. Suciu. A query language for XML. In International World Wide Web Conference, 1999
[13] J. Harbart. X-Query: A universal query interface for XML. Software AG
[14] XML-QL: A Query Language for XML
[15] J. Robie, J. Lapp, D. Schash D. XML Query Language (XQL). The W3C Query Languages Workshop. December 3-4, 1998. Boston, Massachusets
[16] J. Robie, D. Chamberlin, D. Florescu. Quilt: an XML query language
[17] D. Chamberlin, J. Robie, D. Florescu. Quilt: an XML query language for Heterogeneous Data Sources
[18] Системы баз данных третьего поколения: Манифест. // СУБД, 1995, № 2
[19] Дж. Мартин. Организация баз данных в вычислительных системах. Изд. 2-е. М.: Мир, 1980
[20] М.Р. Когаловский. Абстракции и модели в системах баз данных. // СУБД, 1998, № 4-5
[21] Джим Грей. Управление данными. Прошлое настоящее и будущее. // СУБД, 1998, № 3
[22] М. Аткинсон, Ф. Бансилон, Д. ДеВитт, К. Диттрих, Д. Майер, С. Здоник. Манифест систем объектно-ориентированных баз данных. // СУБД, 1995, № 4
[23] R. Goldman, J. Widom. DataGuides: Enabling Query Formulation and Optimization in Semistructured Databases. Proceedings of the Twenty-Third International Conference on Very Large Data Bases, Athens, Greece, August 1997
[24] R. Agrawal, N. Gehani, J. Srinivasan. OdeView: The Y. Papakonstantinou, H. Garcia-Molina, and J. Widom. Object Exchange Across Heterogeneous Information Sources. Proceedings of the Eleventh International Conference on Data Engineering, pp. 251-260, Taipei, Taiwan, 1995
Дмитрий Палей (paley@yars.free.net) — сотрудник технического центра Ярославского государственного университета.
