Сколько времени должен посвятить системный администратор защите критически важных данных от наводнения, если офис компании расположен на двадцатом этаже? В 1994 году в Чикаго бригада рабочих, проводивших профилактические работы, пробила дыру в туннеле, проходившем под рекой. Электрические и телекоммуникационные кабели, проложенные по туннелю, оказались залиты водой. В результате несколько высотных зданий в деловой части города оказались без связи и электричества. Нормальное функционирование было восстановлено лишь на четвертый день. Суммарные потери фирм, офисы которых находились в башнях, составили почти 150 млн. долл.

Катастрофоустойчивость — это способность к восстановлению работы приложений и данных за минимально короткий период времени после катастрофы. Под катастрофами понимаются не только пожар, наводнение или землетрясение, но также возможные непредвиденные сбои в работе служб, разрушение данных или повреждение всего центра обработки (например, в результате аварий в ходе ремонтных работ, умышленной диверсии или саботажа). Катастрофоустойчивая архитектура предполагает защиту от незапланированных простоев во время и после катастрофы в географически распределенных узлах кластера, при которой отказ одного узла не приводит к прекращению работы всей системы (рис. 1).
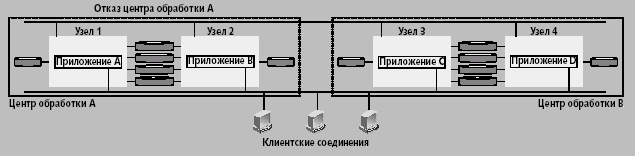
Рис.1. Катастрофоустойчивая архитектура
Поддержка катастрофоустойчивой конфигурации не ограничивается развертыванием только аппаратно-программных решений (организация кластера, установка программных компонентов управления производительностью, ресурсами, инфраструктурой и др.), а должна включать специальные виды услуг, предоставляемые производителем, третьей компанией или выполняемые самим заказчиком (мониторинг работоспособности, резервное копирование и т.д.). Рассматриваемые в статье решения, направленные на обеспечение катастрофоустойчивости, иллюстрируются примерами, основанными на использовании технологий компании Hewlett-Packard.
Типы кластеров
Для защиты от катастроф узлы кластера необходимо разнести на достаточное расстояние. Узлы размещаются в разных помещениях, на разных этажах здания, в разных районах города или даже в разных городах или странах. Расстояние между узлами определяется исходя из конкретной ситуации и в соответствии с используемой технологией репликации данных.
Локальный кластер. В локальном кластере (рис. 2) все узлы расположены в одном центре. Это не обеспечивает катастрофоустойчивости, однако, поскольку большинство кластеров высокой готовности принадлежат именно к этому базовому типу, полезно сравнить его с другими кластерными архитектурами.
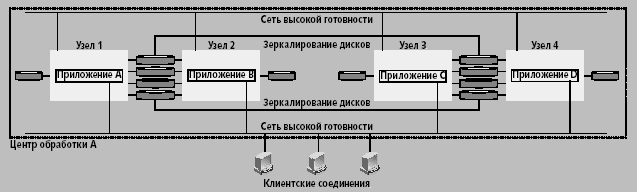
Рис. 2. Локальный кластер
Кампусный кластер. Кампусный кластер (рис. 3) используется как альтернативный способ размещения узлов обработки и хранения данных, которые распределяются по территории предприятия. Сбой в одном здании не приводит к простою всей системы. Расстояния между узлами ограничены использующейся технологией репликации данных; кластеры этого типа обычно используют:
- избыточные диски со средствами репликации данных;
- избыточные сетевые кабели, проложенные по разным маршрутам;
- альтернативные источники питания каждого узла (питание может подаваться от разных подстанций, что защищает кластер от возможных перебоев с подачей электроэнергии).
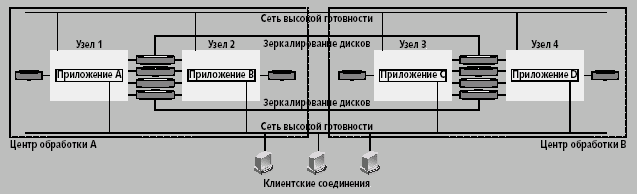
Рис. 3. Кампусный кластер
Метрокластер. У метрокластера (рис. 4), т.е. кластера класса города или района, имеются дублирующие узлы, расположенные в разных частях города или в пригородах. Разнесение узлов на большие расстояния уменьшает вероятность выхода из строя дублирующего узла в результате катастрофы. Архитектура метрокластера очень напоминает кампусный, с той разницей, что расстояния между узлами значительно больше. Для организации такого кластера требуется разрешение местных властей на прокладку сетевых кабелей и кабелей для репликации данных, что может усложнить его развертывание.
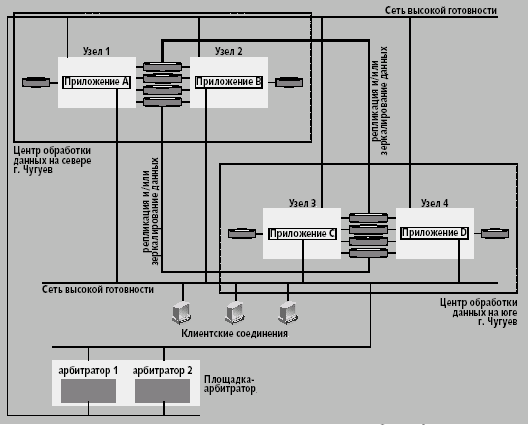
Рис. 4. Метрокластер
Метрокластер предполагает наличие средств синхронизации. Обычно для решения этой задачи используется площадка-арбитратор, содержащая дополнительный узел, который состоит из выделенного сервера и выполняет связующую и синхронизирующую роль для всех остальных узлов. Арбитраторы — полнофункциональные системы, являющиеся составными частями кластера, но не подсоединенные к дисковым массивам. В метрокластере поддерживаются конфигурации с одним или двумя арбитраторами, однако конфигурации с двумя арбитраторами более предпочтительны, так как они обеспечивают больший уровень готовности.
Основное различие между кампусным и метрокластером в технологии репликации данных. Кампусный кластер, как правило, использует для репликации соединение Fibre Channel и средства операционной системы (скажем, MirrorDisk/UX), что накладывает ограничение на расстояние между центрами обработки. Метрокластер использует репликацию, основанную на возможностях дисковых массивов (например, HP SureStore XP или EMC Symmetrix), которые допускают их разнесение на большие расстояния.
В остальном метрокластер организован так же, как и кампусный. Архитектура метрокластера реализована в двух продуктах HP: MetroCluster with Continuous Access XP и MetroCluster with EMC SRDF.
Континентальный кластер. Континентальный кластер (рис. 5) представляет собой совокупность дублированных кластеров, разнесенных на значительные расстояния, причем таким образом, чтобы между ними не использовались технологии локальных сетей. В архитектуре континентального кластера каждый входящий в него кластер является полностью правомочным, поэтому арбитратор не используется. Для соединения кластеров используются глобальные сети на базе TCP/IP, однако для репликации могут понадобиться и высокоскоростные выделенные или коммутируемые линии (например, T1/E1 или T3/E3).
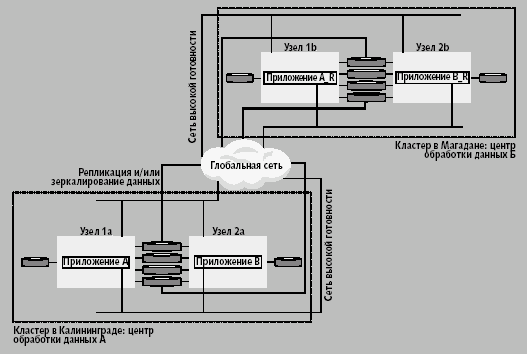
Рис. 5. Континентальный кластер
Катастрофоустойчивый кластер
Все больше предприятий предъявляет повышенные требования к своей информационной инфраструктуре. Растет число организаций, для которых «непрерывность бизнеса» становится уже не просто красивым словосочетанием. Есть они и в нашей стране.
Все более или менее серьезное оборудование подразумевает некоторую степень избыточности. Серверы и дисковые массивы оснащаются резервными источниками питания, вентиляторами, дублирующими контроллерами, процессорами, зеркалированной кэш-памятью, многими другими избыточными устройствами. Все эти усилия направлены на устранение единой точки отказа оборудования. Для построения отказоустойчивой системы это необходимо, для катастрофоустойчивой — недостаточно. Если отказоустойчивая система способна сохранять работоспособность в случае выхода из строя отдельных компонентов, то катастрофоустойчивая — в случае одновременного множественного выхода из строя составных частей или узлов в результате событий непредвиденного характера.
Работоспособность отказоустойчивой системы обеспечивают входящие в нее компоненты: данные со сбойного диска восстанавливаются по четности, микросхема памяти может локально отключаться, питание осуществляется с резервного источника и т.д. Функционирование катастрофоустойчивой системы достигается за счет разнесения ее компонентов на значительные расстояния. Это позволяет подключать систему к разным подстанциям или электростанциям, исключая единую точку отказа по сбою в подаче питания, и обеспечивая непрерывность бизнеса при выходе из строя не только узла кластера, но и всей площадки. Однако одновременно растет роль каналов связи между узлами кластера; если риск повредить проводку внутри здания невелик, и можно применять дешевые решения (изначально полагая, что проводка надежнее компонентов), то в метрокластере канал связи становится важным элементом архитектуры. При построении катастрофоустойчивого кластера необходимо предусмотреть прокладку основного и резервного каналов связи по разным маршрутам.
Для выбора правильной архитектуры чрезвычайно важно определить, насколько уязвим бизнес и каково максимальное время простоя ИТ-инфраструктуры, при котором бизнесу не будет нанесен непоправимый ущерб. Для некоторых предприятий или подразделений это может быть день или два; для других даже минутный простой несет ощутимые потери. Одни приложения нуждаются лишь в защите от сбоя узла, а другие требуют еще и защиты от выхода из строя всей площадки.
Далее, важно определить, какую роль играет каждый конкретный сервер. Так, серверы, отвечающие за обслуживание сборочной линии, требуется восстановить быстрее. Однако если они расположены неподалеку от сборочной линии, то в случае землетрясения серверы выйдут из строя вместе с линией; поэтому запускать приложения, управляющие сборкой на удаленной площадке, не имеет смысла. С другой стороны, систему управления поставками можно запустить на другой площадке, обеспечив работу отдела продаж и непрерывность поставок продукции. Итак, катастрофоустойчивость системы в аппаратной части обеспечивают:
- географическое разнесение узлов;
- репликация данных;
- несколько независимых источников питания;
- высоконадежная сетевая инфраструктура.
MetroCluster/CA
MetroCluster with Continuous Access XP (MetroCluster/CA) представляет собой набор сценариев и файл окружения для работы в программном пакете управления кластерами MC/ServiceGuard. В случае отказа MetroCluster/СА обеспечивает автоматический переход на дублирующий узел. Инструментарий устанавливается на всех узлах кластера, где запущен пакет MC/ServiceGuard; данные приложений расположены на дисковых массивах SureStore XP, подключенных к разным узлам. Репликация на другой массив осуществляется программным обеспечением HP SureStore Continuous Access XP.
MetroCluster/CA создает один управляемый кластер высокой готовности, содержащий до 16 корпоративных серверов HP 9000, размещенных не более чем в 50 километрах друг от друга. Все узлы должны быть членами одного кластера MC/ServiceGuard. Конфигурирование MetroCluster/CA выполняется на всех узлах кластера, как это сделано для всех узлов, использующих MC/ServiceGuard. Кроме этого, на каждом сервере HP 9000, на котором предполагается запускать приложения, требуется установить RAID Manager XP, серверную программу для управления и контроля состояния массива SureStore XP.
Поддерживаются две следующие конфигурации:
- единый центр обработки данных без площадки-арбитратора;
- три центра обработки данных с площадкой-арбитратором, содержащей одну или две системы-арбитратора.
Катастрофоустойчивая система должна удовлетворять ряду требований.
- Каждый центр обработки данных - самодостаточная структура, способная к самостоятельной работе. В составе узла кластера отсутствует единая точка отказа.
- Сеть между центрами обработки данных избыточна; существует несколько маршрутов передачи данных между центрами, что обеспечивает непрерывную связь между ними в случае выхода из строя одного из маршрутов.
- MetroCluster/CA предполагает, что каждая принадлежащая кластеру группа физических дисков, расположенных на дисковом массиве SureStore XP, в любой момент времени может быть активизирована только одним из узлов кластера.
Единый центр обработки данных
MetroCluster/CA поддерживает архитектуру единого центра обработки данных, которая предусматривает создание локального кластера, но сама по себе еще не обеспечивает катастрофоустойчивости. Если центр выйдет из строя, то вся площадка перестанет работать. Такая архитектура защищает данные посредством репликации, предохраняет от множественных отказов в узле и является наиболее распространенной.
Три центра с площадкой-арбитратором
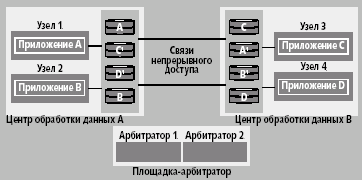
Именно эта архитектура рекомендуется и поддерживается как катастрофоустойчивая. Она состоит из двух центров обработки данных с равным количеством узлов и третьим центром, содержащим один или несколько узлов-арбитраторов (рис. 6).
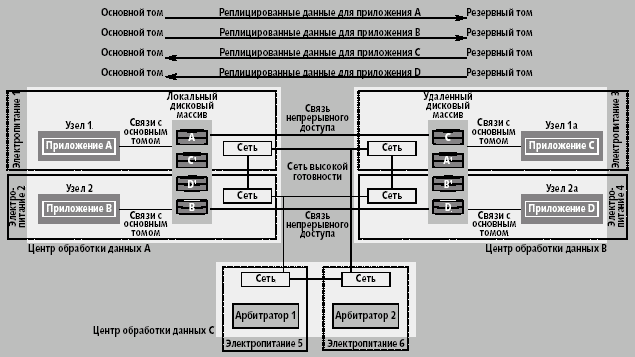
Рис. 6. Три центра с площадкой-арбитратором
Локальный дисковый массив SureStore XP называется основным (Main Control Unit) для всех узлов в центре обработки данных, а удаленный, на котором осуществляется репликация данных, — резервным (Remote Control Unit). Разделение на основной и резервный относительно: дисковый массив может быть основным для одного приложения и резервным для другого. На рис. 6 основной дисковый массив в центре обработки A является основным для приложений A и B, и резервным для приложений C и D в центре обработки B. Для приложений A и B данные записываются на основные тома в дисковом массиве центра обработки A и реплицируются на резервные тома массива в центре B. Соответственно, резервный дисковый массив в центре обработки данных B является основным для приложений C и D, и резервным для приложений A и B. Для приложений C и D данные записываются на основные тома резервного дискового массива центра B и реплицируются на резервные тома основного дискового массива центра A.
Арбитратор обеспечивает ту же функциональность, что и так называемый диск захватов кластера (cluster lock disk), т.е. специальный диск, посредством которого обеспечивается недоступность дисковых ресурсов для остальных узлов, когда их использует один из узлов. Арбитратор вычисляет новый кластер-кворум в случае отказа одного или нескольких узлов. Диск захватов кластера в территориально распределенной конфигурации не используется, поскольку не может управляться посредством постоянного соединения.
В метрокластере в обоих центрах обработки должно быть предусмотрено одинаковое количество систем, подключенных к дисковому массиву и один или два арбитратора в центре С.
Благодаря наличию двух арбитраторов обеспечивается:
- защита от сбоев для приложений работающих на арбитраторе;
- защита от множественных точек отказа;
- планирование времени простоя одного из узлов кластера.
Если используется конфигурация с одним арбитратором, то для обеспечения работоспособности кластера необходимо проведение специальных процедур. Системы должны останавливаться парами, по одной в каждом центре. При остановке самого арбитратора восстановление после сбоя может сильно затрудниться, если одна из других систем тоже выйдет из строя. Система-арбитратор может использоваться для выполнения следующих задач:
- размещения критических приложений, не защищенных программным обеспечением восстановления после сбоя;
- исполнения таких средств управления, как IT/Operations или Network Node Manager;
- исполнения средств резервного копирования (например, OmniBack или Veritas NetBackup);
- работы в качестве сервера приложений.
Дисковый массив SureStore XP
Каждый дисковый массив SureStore XP должен быть сконфигурирован с использованием избыточных связей непрерывного доступа (continuous access), причем каждую из них следует установить с разными локальными и удаленными платами. Для предотвращения образования единой точки отказа в каждом дисковом массиве должно быть не менее двух физических плат для связей непрерывного доступа. Каждая плата обычно имеет несколько портов. Тем не менее, избыточные связи непрерывного доступа должны быть установлены к портам на других физических платах, отличных от той, на которую установлена основная связь. Иными словами, у каждого массива должно быть не менее двух физических плат для поддержания логических связей непрерывного доступа, причем основная и избыточные связи должны устанавливаться на различные платы. При использовании двунаправленных конфигураций, когда центр A является резервным для центра B, а B — резервным для A, должно быть установлено не менее четырех связей непрерывного доступа, по две на каждое направление. Четыре связи надо использовать и в случае однонаправленной конфигурации, если требуется обеспечить восстановление системы после отказа, так как для избыточности необходимо наличие не менее двух связей непрерывного доступа.
На пути к катастрофоустойчивости
Рассмотрим теперь несколько сценариев работы кластера, отвечающих разным уровням надежности и устойчивости к катастрофам.
Архитектура с одним арбитратором
Допустим, имеется два центра обработки данных и одна площадка-арбитратор (рис. 7). На этом пространстве работает кластер из четырех узлов и арбитратора (всего пять). Каждый центр обработки данных содержит два узла кластера и один массив SureStore XP. На каждом узле есть приложение, работающее с дисковым массивом. Между дисковыми массивами установлены связи непрерывного доступа, так что данные приложения А, расположенные на дисках А массива центра А, реплицируются на диски А1 массива, расположенного в центре В. То же самое делается для приложений B, C и D, соответственно. Площадка-арбитратор содержит сервер-арбитратор.
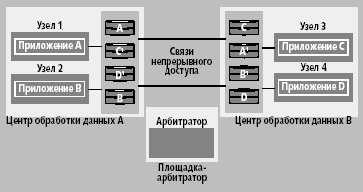 |
| Рис. 7. Архитектура с одним арбитратором |
В таблице 1 собраны сценарии, иллюстрирующие возможные последствия выхода из строя одного или нескольких узлов, а также центра обработки данных в конфигурации с одним арбитратором.
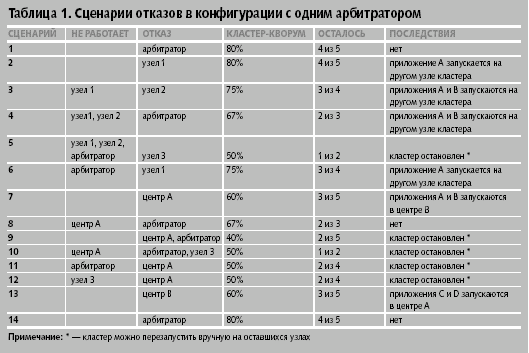
Таким образом, кластер будет остановлен только в случае выхода из строя третьего узла при уже недоступных двух узлах и арбитраторе. Во всех остальных случаях кластер будет способен произвести реконфигурацию. Понятно, что в обычном режиме приложение А работает на узле 1, присутствуя в «спящем» виде на других узлах кластера и будучи сконфигурировано так, что при остановке оно запускается на другом узле. Сценарии 7-14 иллюстрируют возможные последствия выхода из строя центра обработки данных в конфигурации с одним арбитратором.
В конфигурации с одним арбитратором кластер подвергается опасности всякий раз, когда узел останавливается по причине сбоя или при проведении регламентных работ.
Архитектура с двумя арбитраторами
Наличие двух арбитраторов обеспечивает повышенную защиту при остановке узлов и позволяет осуществлять планирование обслуживания арбитраторов без риска остановки кластера при обнаружении сбоя (Рис. 8).
 |
| Рис. 8. Архитектура с двумя арбитраторами |
Сценарии в таблице 2 иллюстрируют возможные последствия остановки центра обработки данных и одного или нескольких узлов в конфигурации с двумя арбитраторами. Некоторые сценарии, приводящие к остановке кластера с одним арбитратором, позволяют работать кластеру с двумя арбитраторами.

Минимальный ущерб, при котором кластер становится недоступен, — это одновременный выход из строя одного из центров обработки данных и одного арбитратора. Если одновременный ущерб больше, то кластер будет остановлен. Во всех остальных случаях будет произведена реконфигурация и система продолжит работу на оставшихся узлах. Введение второго арбитратора существенно повышает уровень готовности системы. Как видно из таблиц, сценарий 10 и 11 в конфигурации с одним арбитратором приведут к остановке системы, в то время как аналогичные сценарии (4 и 5) в конфигурации с двумя арбитраторами приведут лишь к реконфигурации кластера.
Защита репликацией
При катастрофах наиболее опасна потеря доступа к данным и уничтожение самих данных. Однако существует способ минимизировать ущерб, организовав репликацию данных, гарантирующую:
- устойчивость данных (репликация происходит упорядоченно, поэтому копия может быть доступна немедленно; впрочем, устойчивые данные не всегда актуальны);
- актуальность данных (процесс репликации на удаленную площадку протекает достаточно быстро, поэтому реплицированные данные содержат все изменения, внесенные в основную базу);
- возможность восстановления данных (существует множество способов восстановить данные, например, с локальной или удаленной копии, с внешних носителей - оптических дисков или магнитных лент);
- минимальную потерю данных.
Существует два основных способа репликации: оперативный (online) и автономный (offline). Выбор того или иного способа зависит от конкретных условий; возможно их сочетание.
Автономная репликация, используемая наиболее часто, подразумевает в себе два или несколько центров обработки данных, которые сохраняют свои данные на магнитных лентах. Затем происходит обмен лентами или сохранение их в безопасном месте. В случае выхода из строя данных на основной площадке информация на резервной копии используется для синхронизации или восстановления данных на удаленной площадке. Поскольку данные реплицируются в автономном режиме, устойчивость данных не всегда будет высока; существует вероятность потерять данные вследствие человеческих просчетов или ошибок резервного копирования/восстановления. Кроме того, актуальность данных нарушится на такую глубину, насколько велико время доставки ленты на другую площадку. Автономная репликация — отличное решение для организаций, для которых время восстановления работоспособности (от суток до недели) не является критически важным. Репликация таких данных может происходить еженедельно или ежедневно.
При оперативной репликации время восстановления работоспособности удается снизить от нескольких часов до нескольких минут. В оперативном режиме данные могут быть реплицированы синхронно и асинхронно.
Синхронная репликация требует окончания записи блока данных на первый диск и его репликации на удаленный диск до исполнения следующей процедуры записи. Другими словами, первый диск не может произвести следующую операцию записи, не убедившись, что предыдущая порция данных записана на удаленный диск. Этот увеличивает шанс сохранить устойчивость и актуальность данных во время репликации, однако существенно снижает производительность из-за необходимости ждать подтверждения записи предыдущего блока от удаленной системы.
Асинхронная репликация не требует ожидания окончания записи на резервный носитель до начала исполнения следующей команды записи. Приложение, которое работает с множеством транзакций, может записать на диск огромное количество изменений, которые могут оказаться нереплицированными. Поэтому при выходе из строя основной площадки данные на удаленной площадке могут оказаться неактуальными.
HP MetroСluster/CA поддерживает оба способа оперативной репликации данных и обеспечивает для вычислительных сред под управлением операционной системы HP-UX катастрофоустойчивость благодаря автоматическому переключению узлов и их восстановлению в случае сбоя, отказа оборудования или аварии. Для обеспечения катастрофоустойчивости в разнородных средах — с серверами под управлением Sun Solaris, IBM AIX и Windows 2000 — необходимо использовать программный продукт SureStore Cluster Extension XP. В среде Solaris этот продукт интегрируется с пакетом Veritas Cluster Server, в AIX — с HACMP. В Windows 2000 Advanced Server и Windows 2000 Datacenter Server требуется интеграция с Microsoft Cluster Services.
«Катастрофоустойчивый» персонал
Катастрофоустойчивое решение способно защитить информацию и сам бизнес от сбоев. Однако ни одна, даже самая передовая, технология не способна защитить от халатности персонала или преднамеренного разрушения информации. Поэтому вопрос подбора кадров для обслуживания систем такого уровня сложности стоит остро во всем мире. Неквалифицированное администрирование, неумелая настройка оборудования, ошибки конфигурирования, неправильная стратегия резервного копирования или хакерские атаки способны свести на нет все приложенные усилия. Поэтому при построении катастрофоустойчивой системы необходимо самым тщательным образом разработать конфигурацию оборудования и провести ее тонкую настройку, определить стратегию резервного копирования и провести испытания, а для ее поддержки привлекать специалистов самой высокой квалификации.
Вячеслав Елагин (yelagin@i-teco.ru) — руководитель направления компании i-Teco (Москва).
Продажа авиабилетов в режиме 24х7
Несколько лет назад один из крупнейших немецких авиаперевозчиков проводил реорганизацию своей ИТ-инфраструктуры. Эта авиакомпания ежегодно продает более 45 млн. билетов по всему миру. Было решено предоставить пассажирам гибкую систему скидок на авиабилеты в зависимости от частоты пользования услугами авиакомпании. Требовалось использовать имеющуюся информацию для вычисления суммы предоставляемой скидки.
Для достижения этой цели было критически важно, чтобы данные о клиентах хранились централизованно и были доступны всем офисам авиакомпании, расположенным по всему миру. Такое решение предполагало обработку информации круглосуточно, независимо от часового пояса, в котором находится региональный офис.
В компании был развернут метрокластер на базе серверов HP. В его состав вошли два дисковых массива SureStore XP512, благодаря наличию связей постоянного доступа способные поддерживать создание удаленных копий и содержащих 2,5 Тбайт данных. В кластере было установлено программное обеспечение MetroCluster/CA. Две зеркалированные системы гарантировали доступность данных в режиме 24х7. Это было важно также для обмена информацией с другими приложениями, использующимися внутри организации. Компания также использовала два дисковых массива SureStore XP 256 с 10 серверами HP 9000: четыре были соединены через мосты FC-SCSI, а шесть — посредством сети хранения. Имелось также три кластера MC/ServiceGuard для создания архивной инфраструктуры: один для архива, один для базы данных Oracle и один для приложений SAP/Oracle. Администраторы получили возможность постоянного наблюдения за производительностью дисковых массивов SureStore XP512, что позволяло избегать возможных отказов до их реального возникновения.
