Алгоритмы анализа гиперссылок позволяют механизмам поиска создавать адекватные результаты в ответ на запросы пользователей. В статье рассматриваются алгоритмы ранжирования, используемые при извлечении информации из Web.
Извлечение информации (information retrieval) — это область компьютерных технологий, которая ставит своей целью поиск всех документов из данного множества, отвечающих условиям запроса пользователя. В этом случае извлечение информации, на самом деле, следует назвать извлечением документов. До появления Web системы извлечения информации, как правило, устанавливались в библиотеках, где они обычно использовались библиографами-консультантами. Алгоритм извлечения в этих системах, в основном, базировался на анализе слов в документе.
Всемирная паутина все изменила. Теперь каждый пользователь Web может обращаться к разнообразным механизмам поиска, алгоритмы извлечения в которых часто анализируют не только слова в документах, но и такую информацию, как структура гиперссылок Web или теги языка разметки.
Зачем нужны гиперссылки? Сама по себе гиперссылка (т. е. гиперссылка на Web-страницу B, содержащаяся в Web-странице A) для извлечения информации прямой пользы не дает. Однако способ применения гиперссылок, который авторы Web-страницы используют, позволяет получить адекватное информационное наполнение. Как правило, авторы оформляют гиперссылки, которые, по их мнению, могут быть полезны читателям. Некоторые из гиперссылок оказывают помощь в навигации, например, позволяют вернуться на домашнюю страницу сайта; другие обеспечивают доступ к документам, дополняющим информацию, размещенную на текущей странице. Последние, как правило, указывают на очень важные страницы, посвященные той же теме, что и страница, содержащая гиперссылку. Системы извлечения информации в Web могут использовать эти данные для улучшения качества поиска необходимых документов.
Анализ гиперссылок значительно увеличивает релевантность результатов поиска, причем настолько, что все ведущие механизмы поиска в Web в той или иной степени используют анализ гиперссылок. Однако компании, реализующие механизмы поиска, не сообщают подробности о том, какой вид анализа гиперссылок они выполняют. Это делается главным образом для того, чтобы предотвратить разного рода манипуляции с результатами поиска, к которым прибегают компании, занимающиеся позиционированием в Web.
Анализ гиперссылок в Web
В основу алгоритмов анализа гиперссылок положено одно либо оба из следующих допущений.
- Допущение 1. Гиперссылка со страницы A на страницу B — это своего рода рекомендация автора страницы A.
- Допущение 2. Если страница A и страница B связаны гиперссылкой, они могут быть посвящены одной и той же теме.
Анализ гиперссылок при извлечении информации в Web применяется, в основном, в двух случаях — для «ползания» (crawling) и для «ранжирования» (ranking). Кроме того, анализ гиперссылок используется для вычисления географических границ Web-страницы, поиска зеркалированных хостов и вычисления статистических данных страниц Web и механизмов поиска. Эти возможности описаны во врезке «Использование анализа гиперссылок для извлечения информации из Web».
Сбор Web-страниц
Ползание — это процесс сбора Web-страниц. Извлечение информации из Web отличается от классического извлечения информации тем, что первоначального множества страниц не существует и механизм поиска в Web «найти» документы, которые войдут в это множество. Процесс «ползания» (crawling) обычно начинается с некоторого множества исходных Web-страниц. Ползун (Web crawler) перемещается по гиперссылкам исходных страниц в поисках дополнительных Web-страниц. Разработчики механизмов поиска используют метафору «ползанья» паука применительно к созданию гиперссылок в Web. Этот процесс повторяется с каждым новым набором страниц и продолжается до тех пор, пока не перестанут появляться новые страницы, либо пока не будет собрано предопределенное количество страниц. Ползун должен решить, в каком порядке собирать страницы с гиперссылками, которые еще не были проверены. Ползуны различных механизмов поиска принимают разные решения и, таким образом, создают различные наборы Web-документов. Например, ползун может попытаться сначала обойти только Web-страницы «высокого качества». Для этого он помещает все обнаруженные, но не просмотренные страницы в приоритетную очередь, упорядочивая их по качеству.

|
| Рис. 1. Множество Web-страниц и соответствующий граф ссылок. Если Web-страница A имеет ссылку на Web-страницу B, то в графе есть направленное ребро (A, B) |
Анализ гиперссылок дает средства оценки качества страниц. Например, согласно первому допущению алгоритмов анализа гиперссылок, страницы, на которые есть ссылки с многих страниц, имеют более высокое качество, чем страницы, на которые указывает меньшее число страниц. Это значит, что число гиперссылок на данную страницу может использоваться для измерения качества. С другой стороны, в качестве такой меры может использоваться PageRank [1], описанный далее.
|
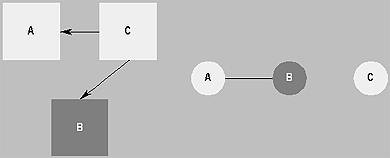
| Рис. 2. Множество Web-страниц и соответствующий граф коцитирования. Если Web-страница C ссылается на страницу A и страницу B, тогда A и B связаны в графе ненаправленным ребром, и говорят, что они коцитируются на C |
Ранжирование выбранных документов
Когда пользователь посылает запрос механизму поиска, то последний возвращает URL-адреса документов, в которых имеются все или хотя бы один из терминов, в зависимости от оператора запроса и алгоритма, применяемого механизмом поиска. Ранжирование — это процесс размещения полученных документов в порядке снижения их релевантности, т. е. таким образом, что самые «лучшие» ответы находятся в начале списка.
Классическое извлечение информации, как правило, использует алгоритмы ранжирования исключительно в зависимости от слов, имеющихся в документах. Одним из таких алгоритмов является модель векторного пространства, представленная Салтоном и другими [2]. Рассматривается многомерное векторное пространство, где каждому термину соответствует свое измерение. Каждый документ или запрос представлен вектором термина в этом векторном пространстве. Вхождения терминов, встречающихся в документе положительны, а вхождение терминов, не встречающихся в документе, равно нулю. А именно, вхождение термина обычно представляет собой функцию, которая растет в зависимости от частоты употребления термина в документе и убывает в зависимости от числа документов в наборе, содержащем этот термин. Идея состоит в том, что чем больше документов, в которых присутствует данный термин, тем в меньшей степени термин характеризует данный документ, и чем чаще термин встречается в документе, тем в большей степени он характеризует документ. Вектора терминов документов могут быть нормализованы с учетом различной длины документов. Адекватность документа запросу (релевантность) обычно вычисляется как скалярное произведение их векторов терминов. Для данного запроса каждому из документов присваивается неотрицательный показатель. Чтобы получить ответ на запрос, документы с положительными значениями возвращаются в порядке убывания их показателей.
Почему классические методы извлечения информации не оправдывают себя в Web? Многие авторы Web-страниц заинтересованы в том, чтобы их страницы в ответах на определенные запросы имели высокий рейтинг. Таким образом, чтобы увеличить рейтинг, авторы будут различным образом «подкручивать» свои страницы. Эти попытки манипулирования алгоритмом ранжирования иногда доходят вплоть до того, что добавляются фрагменты текста, набранные невидимым шрифтом. Например, если для ранжирования используется модель векторного пространства, добавление на страницу 1000 слов «машина» увеличит рейтинг данной страницы при поиске по запросу «машина». Существуют даже агентства Web-маркетинга, которые зарабатывают деньги, давая советы своим клиентам, каким образом можно «улучшить» результаты ранжирования механизмов поиска.
Любой алгоритм, базирующийся исключительно на содержимом страницы, восприимчив к такого рода манипуляциям. Действенность анализа гиперссылок проявляется в том, что он использует для определения рейтинга текущей страницы информационное наполнение других страниц. Если предположить, что эти страницы были созданы авторами независимо от автора исходной страницы, то объективность упорядочивания при таком подходе растет.
Ранжирование на основе связей
Схемы ранжирования на основе связей можно разделить на два класса:
- схемы, не зависящие от запросов, которые присваивают показатель странице независимо от данного запроса;
- схемы, зависящие от запросов, в которых показатель присваивается странице в контексте данного запроса.
Схемы ранжирования, зависящие от запросов, присваивают показатель документу один раз, а затем используют этот показатель для обработки всех последующих запросов. Схемы ранжирования, зависящие от запросов, требуют выполнения анализа гиперссылок для каждого запроса, но при этом сам анализ гиперссылок адаптируется специально для каждого запроса.
Чтобы упростить описание представленных здесь алгоритмов, сначала следует смоделировать набор Web-страниц в виде графа. Это можно сделать различными способами. Методы ранжирования на основе связей обычно предполагают самое очевидное представление: каждая Web-страница в наборе моделируется узлом графа. Если страница A содержит гиперссылку на страницу B, то в графе есть направленное ребро (A, B). Если A не имеет гиперссылки на B, направленного ребра (A, B) не существует. Этот направленный граф называется графом ссылок G.
Некоторые алгоритмы используют ненаправленный граф коцитирования (co-citation graph). В ненаправленном графе цитирования узлы A и B связаны ненаправленным ребром тогда и только тогда, когда существует третья страница C, которая имеет гиперссылки на A и на B. Говорят, что A и B коцитируются посредством C.
Граф связей используется для ранжирования, поиска связанных страниц и решения других задач извлечения документов. Граф коцитирования используется для классификации и поиска связанных страниц.
Ранжирование, не зависящее от запроса
Ранжирование, не зависящее от запроса, служит для определения «истинного» качества страниц. В этом случае показатель присваивается каждой странице независимо от конкретного запроса пользователя. Во время обработки запроса этот показатель используется (с учетом или без учета критерия ранжирования, зависящего от запроса) для ранжирования всех документов, соответствующих условиям запроса.
Первое допущение методов на основе связей порождает простой критерий: чем больше гиперссылок указывает на страницу, тем лучше эта страница. Основной недостаток такого подхода состоит в том, что он не делает различий между качеством страницы, на которую указывает несколько страниц низкого качества и качеством страницы, на которую указывает то же число страниц высокого качества. Очевидно, что рейтинг страницы можно увеличить, просто создав множество других страниц, ссылающихся на данную.
Брин и Пейдж разработали алгоритм PageRank, позволяющий решить эту проблему [3, 4]. Они вычисляют коэффициент PageRank каждой страницы, присваивая каждой ссылке на страницу весовой коэффициент пропорциональный качеству страницы, содержащей гиперссылку. Чтобы определить качество ссылающейся страницы, они используют ее коэффициенты PageRank рекурсивно, причем первоначальные значения PageRank задаются произвольно. Точнее, R(A) — коэффициент PageRank страницы A можно определить как

Эта формула показывает, что коэффициент PageRank страницы A зависит от PageRank страницы B, указывающей на A. Поскольку определение PageRank порождает такое линейное уравнение для каждой страницы, чтобы вычислить PageRank для всех страниц, необходимо решить огромное количество линейных уравнений.
PageRank позволяет эффективно отличить высококачественные страницы Web от низкокачественных, и данный параметр используется в механизме поиска Google.
Ранжирование, зависящее от запроса
При ранжировании, зависящем от запроса, алгоритм присваивает показатель, который изменяет качество и адекватность выбранного множества страниц для данного запроса пользователя. Основная идея состоит в том, чтобы создать граф для каждого конкретного запроса, называемый графом соседей и выполнить по этому графу анализ гиперссылок. В идеале этот граф будет содержать только страницы по теме, указанной в запросе пользователя.
Кэриэр и Кацман предлагают следующий подход к созданию графа соседей [5].
- Начальное множество документов, соответствующих запросу, формируется механизмом поиска.
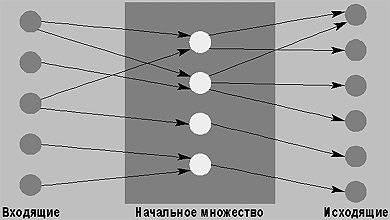
- Начальное множество расширяется за счет своих «соседей», к которым относятся либо документы, на которые есть ссылки со страниц, входящих в начальное множество, либо документы, ссылающиеся на элементы начального множества (см. рисунок 3). Поскольку количество входящих узлов (indegree), т. е. число документов, имеющих ссылки на хотя бы один документ из начального множества, может быть очень большим, на практике включается лишь ограниченное число этих документов, скажем, 50.
- Каждый документ в начальном множестве и множестве соседей моделируется узлом. Ребро их узла A в узел B существует тогда и только тогда, когда документ A имеет гиперссылку на документ B. Гиперссылки между страницами одного и того же Web-хоста иногда пропускаются, поскольку авторы могут оказаться коллегами и такая гиперссылка может не удовлетворять указанному выше первому допущению.
|
| Рис. 3. Начальное множество и соседние страницы. При подходе, использующем «входящие ссылки» начальное множество страниц расширяется за счет соседей, которые представляют собой набор документов, связанных гиперссылками с документами в начальном множестве |
В графе соседей могут применяться различные схемы ранжирования. Как и в случае со схемами ранжирования, не зависящими от запросов, подход на основе входящих узлов [5] упорядочивает узлы в графе соседей в зависимости от числа документов, имеющих на них гиперссылки. И опять-таки, при таком подходе все гиперссылки считаются равнозначными.
Графы соседей, как правило, состоят из нескольких тысяч узлов (т. е., относительно невелики). Вычисление PageRank на графе соседей порождает ранжирование аналогичное тому, которое выполняется при ранжирование по «входящим» узлам [6].
Другой подход к ранжированию страниц в графе соседей предполагает, что информация по теме может распределиться примерно поровну между страницами с хорошим информационным наполнением по теме, называемым «авторитетами», и страницами, напоминающими каталоги, со множеством ссылок на другие страницы, посвященные данной теме, называемые «концентраторами» [7].
Алгоритм Кляйнберга поиска документов по заданной теме на базе гиперссылок (hyperlink-induced topic search — HITS) пытается выявить хорошие концентраторы и авторитеты [7]. С учетом пользовательского запроса алгоритм итеративно вычисляет показатель концентрации и авторитетности для каждого узла графа соседей, а затем упорядочивает узлы в соответствии с этими показателями. Узлы, имеющие высокие показатели авторитетности, должны быть хорошими авторитетами, а узлы с высокими показателями концентрации должны быть хорошими концентраторами. Алгоритм исходит из того, что документ, ссылающийся на большое число других документов — хороший концентратор, а документ, на который указывает множество других документов — хороший авторитет. Рекурсивно, документ, который указывает на большое число хороших авторитетов — еще лучший концентратор, а документ, на который ссылается множество хороших концентраторов — еще лучший авторитет. Это дает следующий рекурсивный алгоритм.

Элементарные вычисления показывают, что векторы Hub и Aut в конечном итоге будут сходиться, но ограничение на число итераций не известно. На практике, векторы сходятся очень быстро.
Заметим, что алгоритм не утверждает, что будут найдены все высококачественные страницы, удовлетворяющие условиям запроса, поскольку некоторые из таких страниц могут не принадлежать графу соседей или входить в его состав, но не иметь ссылок со многих страниц.
В связи с алгоритмом HITS возникает две проблемы.
- Поскольку рассматривается относительно небольшая часть графа Web, добавление ребер к нескольким узлам может серьезно изменить показатели концентраторов и авторитетов [8]. В силу чего манипулировать этими показателями достаточно просто. Как уже отмечалось, манипуляция ранжированием механизма поиска — серьезная проблема для Web.
- Если большая часть страниц в графе соседей относится к теме, которая отличается от темы запроса, авторитеты и концентраторы, получившие высокий рейтинг, могут относиться к другой теме. Эта проблема называется «смещением темы». Добавление весов к ребрам с учетом текста документов или их тезисов значительно смягчает негативный эффект этой проблемы [9-11].
Насколько известно, алгоритм HITS сейчас в коммерческих поисковых системах не используется.
Заключение
Изучение структуры гиперссылок Web только начинается, и в будущем появится еще больше великолепных приложений (подобно тем, которые описаны во врезке). Когда механизмы поиска в Web начали применять анализ гиперссылок, компании, занимающиеся Web-позиционированием, стали манипулировать гиперссылками, создавая гиперссылки, позволяющие увеличить рейтинг страниц их клиентов, тем самым препятствуя механизмам поиска в Web возвращать высококачественные результаты. Чтобы компенсировать такое искажение, компаниям, поддерживающим механизмы поиска в Web, приходится создавать более совершенные методы и хранить их в тайне, поскольку любая новая информация стимулирует новые попытки манипулирования.
Литература
[1] J. Cho, H. Garcia-Molina, and L. Page, «Efficient Crawling through URL Ordering», Proc. Seventh Int?l World Wide Web Conf., Elsevier Science, New York, 1998
[2] G. Salton et al., «The SMART System-Experiments in Automatic Document Processing», Prentice-Hall, Englewood Cliffs, N.J., 1971
[3] S. Brin and L. Page, «The Anatomy of a Large-Scale Hypertextual Web Search Engine», Proc. Seventh Int?l World Wide Web Conf., Elsevier Science, New York, 1998
[4] L. Page et al., «The PageRank Citation Ranking: Bringing Order to the Web», Stanford Digital Library Technologies, Working Paper 1999-0120, Stanford Univ., Palo Alto, Calif., 1998
[5] J. Carriere and R. Kazman, «Webquery: Searching and Visualizing the Web through Connectivity», Proc. Sixth Int?l World Wide Web Conf., Elsevier Science, New York, 1997
[6] B. Amento, L. Terveen, and W. Hill, «Does Authority Mean Quality? Predicting Expert Quality Ratings of Web Documents», Proc. 23rd Int?l ACM SIGIR Conf. Research and Development in Information Retrieval (SIGIR 00), ACM Press, New York, 2000
[7] J. Kleinberg, «Authoritative Sources in a Hyperlinked Environment», Proc. Ninth Ann. ACM-SIAM Symp. Discrete Algorithms, ACM Press, New York, 1998
[8] R. Lempel and S. Moran, «The Stochastic Approach for Link-Structure Analysis (SALSA) and the TKC Effect», Proc. Ninth Int?l World Wide Web Conf., Elsevier Science, New York, 2000
[9] S. Chakrabarti et al., «Experiments in Topic Distillation», Proc. ACM SIGIR Conf. Research and Development in Information Retrieval (SIGIR 98), Post-Conference Workshop on Hypertext Information Retrieval for the Web
[10] S. Chakrabarti et al., «Automatic Resource Compilation by Analyzing Hyperlink Structure and Associated Text», Proc. Seventh Int?l World Wide Web Conf., Elsevier Science, New York, 1998
[11] K. Bharat and M. Henzinger, «Improved Algorithms for Topic Distillation in Hyperlinked Environments», Proc. 21st Int?l ACM SIGIR Conf. Research and Development in Information Retrieval (SIGIR 98), ACM Press, New York, 1998
Моника Хензингер (monika@google.com) — директор по исследованиям компании Google, предлагающей механизмы поиска в Web следующего поколения. К области ее научных интересов относятся вопросы извлечения информации, Web-анализ и алгоритмика.
Monika R. Henzinger, Hyperlink Analysis for the Web. IEEE Internet Computing, January/February 2001. IEEE CS, 2001. All rights reserved. Reprinted with permission.
Использование анализа гиперссылок для извлечения информации из Web
Структура гиперссылок в Web может использоваться не только для анализа качества Web-страницы. Она также полезна для поиска Web-страниц, аналогичных данной Web-странице или Web-страниц, интересных для данного географического региона. Ниже описаны эти и другие возможности применения анализа гиперссылок для извлечения информации.
Поиск по образцу
Подход к извлечению информации в Web, называемый поиском по образцу, предусматривает выбор страниц, похожих на данную страницу. Например, по данной www.nytimes.com, найти www.washington-post.com и www.wsj.com. В этом случае хорошо работают и алгоритм HITS, и простой алгоритм поиска по графу цитирования [1, 2]. Последний алгоритм основан на том, что частота цитирования показывает схожесть, особенно в тех случаях, когда ссылки на странице размещены близко друг к другу. Таким образом, страницы с множественным цитированием, при котором ссылки на странице с цитатой располагаются близко друг к другу, как правило, схожи.
Зеркалированные хосты
Маршрутное имя Web-страницы — это часть URL, следующая за адресом хоста, т. е. после третьего символа /. Например, если URL страницы http://www.google.com/about.html, то адрес www.google.com — это адрес хоста, а /about.html — маршрутное имя. Два хоста, H1 и H2, являются зеркалами тогда и только тогда, когда для каждого документа на H1 существует очень похожий документ на H2 с одним и тем же путем, и наоборот.
Зеркала имеют очень похожую структуру гиперссылок внутри хоста и между зеркалированным хостом и другими хостами. Зеркалированные Web-хосты занимают место в индексной структуре данных и могут привести к дублированию результатов. Сочетание анализа гиперссылок с анализом IP-адресов и анализом шаблонов URL позволяет выявить множество практически зеркальных хостов [3].
Классификация Web-страниц
Анализ гиперссылок может использоваться для вычисления в группах Web-страниц статистических данных, таких как средняя длина, доля информации на французском языке и тому подобных показателей. Случайное блуждание, аналогичное алгоритму PageRank, может быть выполнено на Web для отбора образцов Web-страниц при почти нормальном распределении [4]. Эти почти случайные выборки могут затем использоваться для определения различных свойств Web-страниц, а также для того, чтобы сравнить число страниц в индексах различных коммерческих механизмах поиска. Например, в ноябре 1999 года с помощью этой методики было выяснено, что почти 47% всех Web-страниц принадлежат домену .com.
Географическая область
Будет ли данная Web-страница интересна только людям, проживающим в данном регионе, в конкретной стране или по всему миру — важная задача анализа гиперссылок. Например, страница с прогнозом погоды интересна только людям, проживающим в регионе, данные о котором на этой странице размещаются, в то время как Web-страница Службы внутренних доходов (американское налоговое ведомство — Прим. ред.) может быть интересная американским налогоплательщикам по всему миру. Структура гиперссылок страницы также отражает диапазон этого интереса [5, 6]. Локальные страницы в основном имеют гиперссылки на страницы из одного и того же региона, в то время как гиперссылки на страницы, представляющие национальный интерес, примерно равномерно распределены по всей стране. Эта информация позволяет механизмам поиска настраивать результаты, генерируемые в ответ на запрос, с учетом того региона, где находится пользователь.
Литература
[1] J. Kleinberg, «Authoritative Sources in a Hyperlinked Environment», Proc. Ninth Ann. ACM-SIAM Symp. Discrete Algorithms, ACM Press, New York, Jan. 1998
[2] J. Dean and M.R. Henzinger, «Finding Related Web Pages in the World Wide Web», Proc. Eighth Int?l World Wide Web Conf., Elsevier Science, New York, 1999
[3] K. Bharat et al., «A Comparison of Techniques to Find Mirrored Hosts on the World Wide Web», J. American Soc. for Information Science, Vol. 51, No.12, Nov. 2000
[4] M.R. Henzinger et al., «On Near-Uniform URL Sampling», Proc. Ninth Int?l World Wide Web Conf., Elsevier Science, Amsterdam, 2000
[5] O. Buyukkokten et al., «Exploiting Geographical Location Information of Web Pages», Proc. ACM SIG-MOD Workshop on the Web and Databases (WebDB 99), INRIA, Philadelphia, 1999
[6] J. Ding, L. Gravano, and N. Shivakumar, «Computing Geographical Scopes of Web Resources», Proc. 26th Int?l Conf.Very Large Databases (VLDB 00), Morgan Kaufmann, San Francisco, 2000
