Модель данных
Приложения используют различные виды данных о потребителях. Многие приложения разделяют данные на два основных типа: фактические данные (кто такой потребитель) и данные о транзакциях (что потребитель делает).
К примеру, в маркетинговом приложении, базирующемся на данных о покупках потребителя, фактические данные включают в себя демографическую информацию, такую как имя, пол, дату рождения, адрес, зарплата и номер социального страхования. Данные о транзакциях содержат записи о покупках потребителя, сделанных за определенный период. Запись о покупке может включать в себя дату покупки, приобретенный продукт, стоимость, использовался ли купон, цена купона и полученная скидка. На рис. 2 приведены примеры фактических данных и данных о транзакциях.
Модель профиля
Полный профиль потребителя состоит из двух частей: фактической и поведенческой. Фактическая часть содержит такую информацию, как имя, пол, дата рождения, которую система персонификации получает из фактических данных потребителя. Фактический профиль также может содержать информацию, извлекаемую из данных о транзакциях, например, «X предпочитает пиво «Хайникен» или «в прошлом месяце стоимость самой крупной покупки Y составила 237 долл.».
Поведенческий профиль моделирует действия потребителя; как правило, он строится на основе данных о транзакциях. Примеры элементов поведенческого профиля: «при покупке овсянки Джон Доу покупает молоко» и «по выходным Джон Доу обычно тратит на бакалейные товары более 100 долл.».
Выявление правил
Поведение конкретного потребителя описывается с помощью правил различных типов, в том числе правил связывания [8] и классификации [9].
Применение правил для описания поведения потребителя имеет ряд преимуществ. Помимо того, что этот способ представления поведения интуитивен и нагляден, правило связывания — весьма удобная концепция, активно применяемая при добыче данных, в экспертных системах, логическом программировании и во многих других областях. В научной литературе предлагается множество алгоритмов выявления правил, особенно правил связывания и классификации.
Методы выявления правил мы применяем по отдельности к данным каждого потребителя. Чтобы выявить правила, описывающие поведения конкретных потребителей, мы используем различные алгоритмы добычи данных, такие как Apriori [8] для правил связывания и CART (Classification and Regression Trees — «деревья классификации и регрессии») [9] для правил классификации. Наш подход к профилированию не ограничивается каким-то конкретным представлением правил добычи данных или метода выявления.
Поскольку методы добычи данных позволяют получать правила для каждого потребителя по отдельности, эти методы прекрасно работают в случае приложений, содержащих большое число транзакций для каждого потребителя, таких как приложения обработки кредитных карт, покупки бакалейных товаров, интерактивного просмотра информации и торговли ценными бумагами. В таких же приложениях, как покупка автомобилей и планирование туристических путешествий, «персональные» правила обычно менее статистически надежны, поскольку генерируются на основе относительно небольшого числа транзакций.
Проверка правил
Методы добычи данных часто порождают огромное количество правил, многие из которых, хотя и приемлемы с точки зрения статистики, тривиальны, ложны или не актуальны для рассматриваемого приложения [10, 11]. В силу этого, требование проверки выявленных правил крайне важно. Например, предположим, что метод добычи данных выявил правило, утверждающее, что Джон Доу, будучи в служебной командировке в Лос-Анджелесе, останавливается в дорогих отелях. Предположим, что Джон приезжал в Лос-Анджелес семь раз за последние два года и в пяти из этих приездов останавливался в дорогих отелях. Необходимо проверить это правило, т. е. убедиться, что оно отражает поведение Джона, а не является ложным связыванием, и что оно действительно актуально для данного приложения.
Один из способов проверить выявленные правила — предоставить эксперту по соответствующей предметной области возможность проанализировать их и решить, насколько хорошо они представляют реальное поведение потребителей. Эксперт одобряет одни правила и отвергает другие; принятые правила формируют поведенческие профили.
Важным моментом при решении задачи проверки правил является масштабируемость. В приложениях персонификации число потребителей может оказаться крайне велико. К примеру, в приложении обработки кредитных карт число потребителей измеряется миллионами. Если для каждого в среднем было выявлено 100 правил, то общее число правил в данном приложении составит сотни миллионов. Ни один эксперт просто не в состоянии проверить поочередно все эти правила.
Для решения данной задачи в нашей системе используются операторы проверки, которые позволяют эксперту проанализировать огромные массивы правил за относительно небольшое время. Как показано на рис. 4, проверка правил — процесс итерационный, позволяющий эксперту последовательно применять различные операторы, используя каждый из них для групповой проверки правил.
Процесс построения профиля состоит из двух этапов. На первом этапе (добыча данных) генерируются правила для каждого потребителя на основе данных о его транзакциях. Второй этап представляет собой процесс проверки правил, выполняемый экспертом-человеком.
Проверка правил, в отличие от их выявления, выполняется не для каждого потребителя в отдельности, а для всех вместе. Как результат, эксперт обычно анализирует множество похожих или даже идентичных правил, установленных для различных потребителей. Например, правило «при покупке овсянки Джон Доу покупает и молоко» может оказаться общим для многих потребителей. Точно также правило «в выходные Джон Доу обычно тратит на бакалейные товары более 100 долларов» может оказаться общим для потребителей, у которых большая семья. Групповая проверка правил позволяет эксперту анализировать общие правила лишь единожды. С другой стороны, раздельная проверка правил для каждого потребителя заставила бы эксперта снова и снова анализировать массу идентичных или схожих правил. Поэтому в начале Этапа 2 система объединяет правила всех потребителей в один набор и помечает каждое правило идентификатором того потребителя, к которому оно относится. После проверки система помещает принятые правила в профиль соответствующего потребителя.
Рис. 5 демонстрирует процесс проверки правил. Все правила, выявленные на Этапе 1 (помеченные на рисунке Rall), считаются непроверенными. Эксперт выбирает различные операторы проверки и применяет их последовательно к множеству непроверенных правил. Поле применения каждого оператора проверки определенные правила принимаются (множество Oacc), а другие отвергаются (Orej). Затем эксперт применяет следующий оператор проверки к множеству правил, оставшемуся непроверенным (Runv).
После процесса проверки множество всех выявленных правил (Rall) разделяется на три взаимно непересекающихся множества: принятые правила (Racc), отвергнутые правила (Rrej) и, возможно, оставшиеся непроверенными правила (Runv). В конце Этапа 2 все принятые правила размещаются в поведенческих профилях соответствующих потребителей.
Операторы проверки
Предусмотрено несколько операторов проверки, которые можно использовать для анализа большого числа правил [7].
Группировка правил на основе сходства
Этот оператор помещает в группу похожие правила в соответствии с критериями сходства, определенными экспертом. В итоге эксперт может анализировать группы правил, а не отдельные правила одно за другим, и может принимать или отвергать сразу все правила в группе. Мы разработали метод, позволяющий эксперту указать различные уровни сходства правил. Мы также создали эффективный (с линейной сложностью) алгоритм группировки правил [7].
К примеру, в соответствии с условием сходства структуры атрибутов, все правила, имеющие одинаковую структуру атрибутов (без учета значений атрибутов и статистических параметров), считаются схожими. Рассмотрим правила на рис. 3. В соответствии с условием сходства структуры атрибутов оператор группировки помещает правила 1 и 2 в одну группу, поскольку они оба имеют структуру атрибутов Продукт => Магазин. Следовательно, любое правило с такой структурой атрибутов будет помещено в ту же группу, что и правила 1 и 2. Правило 3, однако, никогда не будет объединено вместе с правилами 1 и 2, поскольку у него иная структура атрибутов: Продукт => Купон Использован. Структура атрибутов лишь одно из множества условий сходства, которые может использовать оператор группировки правил на основе сходства.
Фильтрация правил по шаблонам
Этот оператор фильтрует правила, которые соответствуют шаблонам, определенным экспертом. Эксперт указывает шаблоны принятия и отказа от правил. Естественно, правила, которые соответствуют шаблону принятия, принимаются, а правила, которые соответствуют шаблону отказа — отвергаются. Правила, которые не соответствуют шаблонам, остаются непроверенными. Для этого оператора мы разработали язык спецификаций шаблонов правил и эффективный (с линейной сложностью) алгоритм согласования.
Рассмотрим следующий шаблон правил: REJECT HEAD = {Магазин = RiteAid}. Этот шаблон означает: «Отвергнуть все правила, в заголовках которых Магазин = RiteAid». Из семи правил, приведенных на рис. 3, только правило 1 соответствует данному шаблону и, как следствие, будет отвергнуто. Более сложным шаблоном правила является шаблон ACCEPT BODY ??? {Продукт} AND HEAD ??? {ДеньНедели, Количество}. Это правило означает: «Принять все правила, в теле которых есть атрибут Продукт (возможно среди других атрибутов), а также заголовки которых состоят из атрибутов ДеньНедели и Количество». На рис. 3 правила 5 и 7 соответствуют этому шаблону и будут приняты и помещены в профиль.
Удаление избыточных правил
Этот оператор удаляет правила, которые могут быть выведены из других — обычно более общих — правил и фактов. Другими словами, он удаляет правила, которые сами по себе не несут новой информации о поведении потребителя. Этот оператор содержит алгоритм, проверяющий правила на определенные условия избыточности [7].
Рассмотрим правило связывания Продукт = ЯблочныйСок => Магазин = GrandUnion (2%, 100%), которое было получено на основе данных о покупках, сделанных Джоном Доу. Само по себе это правило, как может показаться на первый взгляд, содержит информацию, характеризирующую поведение Доу (он покупает яблочный сок только в Grand Union), поэтому представляется логичным поместить его в поведенческий профиль Доу. Предположим, однако, что из имеющихся данных следует, что данный потребитель делает покупки исключительно в Grand Union. Правило относительно яблочного сока лишь является частным случаем. Таким образом, из-за наличия утверждения «потребитель делает покупки только в Grand Union» в фактическом профиле Джона Доу нет необходимости помещать в профиль правило о яблочном соке.
Помимо перечисленных трех операторов, есть и другие операторы проверки, например, визуализации, статистического анализа и просмотра [7]. Оператор визуализации позволяет эксперту анализировать подмножества непроверенных правил в таких визуальных представлениях, как гистограммы и секторные диаграммы. Оператор статистического анализа вычисляет разнообразные статистические характеристики непроверенных правил. Оператор просмотра позволяет эксперту анализировать отдельные правила или группы правил, непосредственно просматривая их на экране.
Как показано на рис. 5, эксперт последовательно применяет операторы проверки к множеству непроверенных правил, пока не будет выполнено условие TerminateValidationProcess, останавливающего этот процесс. Эксперт может определить условия прекращения процесса проверки по-разному. Приведем два примера.
- Процесс проверки продолжается до тех пор, пока не будут проверена некоторая заранее определенная доля всех правил (например, 95%).
- Процесс проверки заканчивается, когда операторы проверки на каждом шаге проверяют лишь небольшое число правил, т.е. когда затраты на выбор и применение каждого дополнительного оператора проверки себя не оправдывают, поскольку в итоге к множеству проверенных правил добавляется лишь несколько новых («закон убывающей доходности»).
Система 1:1PRO
Система 1:1Pro (сокращение от One-to-One Profiling) реализует предложенные нами методы создания профилей и проверки. Система в качестве входной информации получает фактические данные и данные о транзакциях, хранящиеся в базе данных или в плоских файлах и генерирует множество проверенных правил, описывающих поведение конкретных потребителей. Допускается использование любой СУБД для хранения потребительской информации и различных инструментов добычи данных для выявления правил. Кроме того, в нее интегрируются другие инструменты, полезные для процесса проверки правил, например, средства визуализации и статистического анализа.
Архитектура системы 1:1Pro, показанная на рис. 6, соответствует модели клиент-сервер. Серверный компонент состоит из следующих модулей.
- Модуль координации координирует создание профиля, в том числе процесс генерации правил и последующий процесс проверки.
- Модуль проверки проверяет правила, выявленные с помощью средств добычи данных. В нынешней версии система поддерживает группировку на основе сходства, фильтрацию по шаблонам, удаление избыточных правил и операторы просмотра.
- Модуль коммуникаций отвечает за все взаимодействия с клиентом 1:1Pro.
- Интерфейсы с внешними модулями, такими как СУБД, инструменты добычи данных и средства визуализации. Каждый модуль требует отдельного интерфейса (рис. 6).
Клиентский компонент содержит модуль графического пользовательского интерфейса и модуль коммуникаций. Эксперт использует графический интерфейс, чтобы указать операции проверки и просмотреть результаты итерационного процесса проверки. На рис. 7 приведен пример окна для оператора фильтрации по шаблонам.
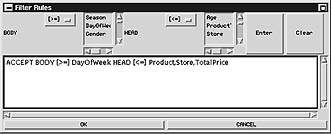 |
| Рис. 7. Окно графического пользовательского интерфейса для оператора фильтрации. Эксперт пользуется им, чтобы указать операции проверки и просмотреть результаты итерационного процесса проверки |
Модуль связи клиента посылает на сервер указанный экспертом запрос на проверку. Сервер получает операторы проверки и передает их через модуль координации компоненту проверки для последующей обработки. Некоторые операторы проверки, такие как оператор статистического анализа, генерируют выходные данные. Модули связи передают эти выходные данные из модуля проверки в модуль интерфейса.
Мы стремились к тому, чтобы сделать 1:1Pro открытой системой, которая без труда интегрирует широкий диапазон источников данных, а также инструментов добычи данных, визуализации и статистического анализа. В частности, мы разработали интерфейс базы данных, который поддерживает реляционные СУБД (например, Oracle или Microsoft SQL Server), плоские файлы и журналы регистрации в Web и другие источники данных.
Рис. 8. Фрагмент файла регистрации 1:1Pro.
В текущей реализации 1:1Pro использованы методы выявления правил связывания для создания профилей потребителей. Однако наши методы не ограничиваются только конкретной структурой правил или определенным алгоритмом их выявления. Мы можем добавлять как коммерческие, так и экспериментальные инструменты добычи данных, которые используют не только методы выявления связей, а скажем, еще и метод дерева решений [9]. Одна из проблем, касающаяся применения внешних средств добычи данных, состоит в том, что формат представления правил в них отличается от нашего. Мы решили эту проблему за счет создания конвертеров правил для внешних средств добычи данных, которые взаимодействуют с 1:1Pro.
Эксперт указывает операторы проверки с помощью модуля графического пользовательского интерфейса, а файл регистрации записывает эти операторы по мере их применения. Файл регистрации описывает весь процесс проверки, давая экспертам возможность отслеживать все операции, связанные с проверкой. Эксперт может также «откатиться» на любой шаг процесса, если эти шаги оказались бесполезны, выбрав соответствующий оператор в файле регистрации и вновь запустив процесс с этого оператора. Записи файла регистрации состоят, в частности, из следующих полей:
- ResultId — экземпляр оператора проверки, используемый на данном шаге;
- Operator — тип оператора (группировка, просмотр, фильтрация);
- SourceId — экземпляр ранее примененного оператора проверки;
- Date/Time — временная метка, показывающая, когда был создан оператор проверки;
- Notes — комментарии эксперта предметной области.
Серверный компонент 1:1Pro, реализованный на языках Си++ и Perl, работает на платформах Linux и Unix. Клиентский компонент, реализованный на Java, может работать на том же компьютере, что и сервер, или на другом. Он может запускаться из модуля просмотра апплетов или как автономное приложение.
Эксперименты
Мы протестировали 1:1Pro на реальном маркетинговом приложении, которое содержало данные за год о 1903 семьях, покупающих различные безалкогольные напитки. Этот набор данных имел 21 поле, характеризующее покупки, и 353421 запись (в среднем, 186 записей на семью).
В качестве теста мы выполняли сезонный анализ. Другими словами, мы создавали профили потребителей, содержащие индивидуальные правила, описывающие поведение потребителей в зависимости от времени года. Например, правила могли описывать виды продуктов, которые семья покупает в определенное время (только зимой, только по выходным) или время, когда потребитель покупает конкретные продукты.
Модуль добычи данных системы сгенерировал 1022812 правил связывания, т.е., в среднем, около 537 правил на семью. Почти 40% из 407716 выявленных правил относились к пяти или меньшему количеству из 1903 семей. В свою очередь, из этих 40% почти половина правил (196384 правил) применялись только к одной семье. Эти данные показывают, что многие из выявленных правил описывают уникальное поведение отдельных потребителей. Поскольку традиционные подходы к созданию профилей потребителей, базирующиеся на сегментации, не описывают индивидуального поведения, они не способны выявить большую часть правил, обнаруженных нами. С другой стороны, некоторые из выявленных правил применимы ко многим семьям. К примеру, девять правил касались более 800 семей. В частности, ДеньНедели = Понедельник => Покупатель = Женщина применимо к 859 семьям.
Поскольку мы были знакомы с этим приложением, мы взяли на себя роль экспертов и самостоятельно провели проверку правил. В таблице 1 приведены комментарии к процессу проверки. Мы начали с удаления избыточных правил, а затем применили несколько операторов фильтрации, большинство их которых представляли собой фильтры удаления правил. Удаление избыточных правил и многократное применение фильтров помогло нам проверить 93,4% правил.
После проверки большого количества правил с помощью относительно небольшого числа операторов фильтрации, мы решили изменить подход к проверке — и применить к оставшимся непроверенными правилам оператор группировки. Оператор группировки создал 652 группы. Затем мы рассмотрели несколько более крупных групп и проверили содержащиеся в них правила. В результате, мы смогли проанализировать все правила, за исключением 37370. В этот момент мы столкнулись с проявлением закона убывающей доходности — каждое последующее применение оператора проверки позволяло выявить все меньше «верных» правил. И мы прервали процесс проверки. На все про все ушло около часа (включая время работы ПО и время экспертизы). Мы проверили 97,2% правил — 4% были приняты и 93,2% отвергнуты. Результаты показывают, что системы может проверить значительное число правил в приложениях персонификации среднего размера.
В результате процесса персонификации мы сократили размер профиля потребителя в среднем с 537 непроверенных правил до 21 принятого правила. Пример принятого правила для одной семьи: Продукт = ЗамороженныйЙогурт & Сезон = Зима => КупонИспользован = Да. Другими словами, зимой эта семья покупает замороженный йогурт в основном на купоны. Мы приняли это правило, поскольку оно отражает важный момент использования купонов. Пример отвергнутого правила для одной семьи: Продукт = Пиво => Покупатель = Мужчина, поскольку пиво, как правило, в этой семье покупает мужчина. Мы отвергли это правило, поскольку оно не относится к сезонному анализу.
Поскольку до этого мы сами выполняли процесс проверки, мы решили попросить эксперта по маркетингу провести другой сезонный анализ тех же самых данных. Эксперт начала анализ с применения операторов удаления избыточных правил и нескольких операторов фильтрации по шаблону, используемых для удаления правил (например, операторы, которые отвергают все правила, в которых отсутствуют атрибуты Сезон или ДеньНедели). Затем она сгруппировала оставшиеся непроверенными правила, проанализировала несколько полученных групп и прервала процесс проверки. В этот момент она пришла к выводу, что отвергать больше нечего и решила принять все оставшиеся непроверенными правила. В итоге, она одобрила 42 969 правил (4,2% всех выявленных правил), потратив на проверку около 40 минут.
Эксперт по маркетингу отметила, что наш процесс оценки правил по сути своей субъективен, поскольку различные эксперты имеют разный опыт и представление о приложении. Разные эксперты получили бы разные результаты оценки, используя один и тот же процесс проверки.
Следует подчеркнуть, что принятые правила, хотя эксперт считает их корректными и уместными, могут казаться неэффективны. Другими словами, они могут не гарантировать получение обоснованных результатов, таких как решения, рекомендации и другие связанные с пользователем действия. Сейчас мы работаем над тем, чтобы интегрировать в 1:1Pro концепцию эффективности.
Мы также решаем проблему генерации множества неуместных правил, которые впоследствии отвергаются в результате процесса проверки. Эту проблему можно решить, предоставив эксперту возможность указать ограничения типов интересующих правил еще до этапа их выявления. В [12] предлагаются способы указать такие ограничения и, тем самым, заранее сократить количество выявленных правил, которые, по мнению эксперта, не имеют отношения к решаемой задаче. Поскольку эксперту крайне сложно предсказать все уместные и неуместные правила, проверка по-прежнему необходима. Таким образом, идеальное решение состоит в том, чтобы объединить этапы указания ограничений, добычи данных и проверки правил в одной системе. Сейчас мы работаем над реализацией этих методов в системе 1:1Pro.
Литература
[1] P. Hagen, «Smart Personalization», The Forrester Report, Forrester Research, Cambridge, Mass., July 1999
[2] Comm. ACM, Special Issue on Recommender Systems, vol. 40, no. 3, 1997
[3] P. Resnick et al., «GroupLens: An Open Architecture for Collaborative Filtering of Netnews», Proc. 1994 Computer-Supported Cooperative Work Conf., ACM Press, New York, 1994, pp. 175-186
[4] U. Shardanand and P. Maes, «Social Information Filtering: Algorithms for Automating ?Word of Mouth?», Proc. Conf. Human Factors in Computing Systems (CHI 95), ACM Press, New York, 1995, pp. 210-217
[5] W. Hill et al., «Recommending and Evaluating Choices in a Virtual Community of Use», Proc. Conf. Human Factors in Computing Systems (CHI95), ACM Press, New York, 1995, pp. 194-201
[6] M. Pazzani, «A Framework for Collaborative, Content-Based and Demographic Filtering», Artificial Intelligence Review, Dec. 1999, pp. 393-408
[7] G. Adomavicius and A. Tuzhilin, «Expert-Driven Validation of Rule-Based User Models in Personalization Applications», J. Data Mining and Knowledge Discovery, Jan. 2001, pp. 33-58
[8] R. Agrawal et al., «Fast Discovery of Association Rules», Advances in Knowledge Discovery and Data Mining, AAAI Press, Menlo Park, Calif., 1996, chap. 12
[9] L. Breiman et al., Classification and Regression Trees, Wadsworth, Belmont, Calif., 1984
[10] G. Piatetsky-Shapiro and C.J. Matheus, «The Interestingness of Deviations», Proc. AAAI-94 Workshop Knowledge Discovery in Databases, AAAI Press, Menlo Park, Calif., 1994, pp. 25-36
[11] A. Silberschatz and A. Tuzhilin, «What Makes Patterns Interesting in Knowledge Discovery Systems», IEEE Trans. Knowledge and Data Engineering, Dec. 1996, pp. 970-974
[12] R. Srikant, Q. Vu, and R. Agrawal, «Mining Association Rules with Item Constraints», Proc. Third Int?l Conf. Knowledge Discovery and Data Mining, AAAI Press, Menlo Park, Calif., 1997, pp. 67-73
Гедиминас Адомавичус — аспирант Института математики Куранта Нью-йоркского университета. К области его научных интересов относятся добыча данных, персонификация и научные вычисления. С ним можно связаться по адресу adomavic@cs.nyu.edu. Александр Тужилин — адъюнкт-профессор Школы бизнеса Штерна Нью-йоркского университета. Он занимается вопросами обнаружения знаний в базах данных, персонификацией и временными базами данных. С ним можно связаться по адресу atuzhili@stern.nyu.edu.
Gediminas Adomavicius, Alexander Tuzhilin. Using Data Mining Methods to Build Customer Profiles. Computer, February 2001, pp. 74-82. All rights reserved, 2001, IEEE Computer Society. Reprinted with permission from IEEE CS.
Глоссарий
Персонификация
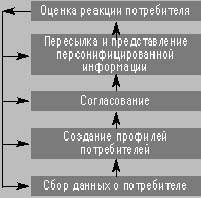 |
| Этапы процесса персонификации Оценка реакции потребителей обеспечивает обратную связь для каждого из предыдущих этапов |
Персонификация — относительно новая область, поэтому разные авторы по-своему определяют эту концепцию [1]. Мы называем персонификацией итерационный процесс, состоящий из шагов, представленных на рисунке A.
Сбор данных о потребителе
Персонификация начинается со сбора данных о потребителе, получаемых из различных источников. Эти данные могут включать в себя информацию о покупках, сделанных потребителем через Web, и о действиях, связанных с просмотром информации, а также демографических и психографических данных. После того, как данные собраны, их необходимо подготовить, отфильтровать и записать в хранилище данных [2].
Создание профилей потребителей
Основная задача в разработке приложений персонификации — создание точных и полных профилей на основе собранных данных.
Согласование
Системы персонификации должны согласовывать информационное наполнение и услуги с предпочтениями конкретных потребителей. Это согласование требует применения различных подходов. Например, компании BroadVision и Art Technology Group используют бизнес-правила для определения того, какое именно информационное наполнение должно доставляться в каждой конкретной ситуации. Чтобы дать персонифицированные рекомендации, системы подготовки рекомендаций используют такие технологии, как фильтрация на основе информационного наполнения и совместная фильтрация. Системы, опирающиеся на информационное наполнение, рекомендуют элементы, аналогичные тем, которым потребитель отдавал предпочтение в прошлом. Системы совместной фильтрации рекомендуют элементы, которые ранее выбирали другие потребители со схожими вкусами и предпочтениями.
Доставка и представление
Компании, работающие в области электронной коммерции, предоставляют потребителям персонифицированную информацию разными способами. В соответствии с одной из классификаций методов доставки, они подразделяются на принудительные (push), по запросу (pull) и пассивные (passive) [3]. Методы принудительной доставки обращаются к потребителю, который в данный момент времени не работает с системой, например, посылая ему сообщение по электронной почте. Методы доставки по запросу уведомляют потребителей о наличии персонифицированной информации, но отображают эту информацию только тогда, когда потребитель формулирует соответствующий запрос. Пассивные методы доставки отображают персонифицированную информацию в контексте приложения электронной коммерции. Например, когда потребитель обращается на Web-сайт за конкретным продуктом, он также видит рекомендации по другим, связанным с ним продуктам. Система может представлять персонифицированную информацию в различной форме: в повествовательном изложении, в виде списка, упорядоченного по релевантности, или с помощью разных видов визуализации [3].
Определение реакции потребителей
Компании могут использовать различные «электронные параметры» для оценки эффективности технологий персонификации [4]. Например, компания, занимающаяся электронной коммерцией, может определить, стали ли потребители больше времени проводить на ее Web-сайте и, как следствие, тратить больше денег, появились ли у компании новые потребители благодаря персонифицированным службам, а также увеличивается ли число постоянных клиентов среди потребителей.
Как показано на рисунке A, оценка реакции потребителей рассматривается как отдача от возможных улучшений на каждом из четырех остальных этапах процесса персонификации. В частности, разработчики системы должны на основе реакции потребителей решить, нужно ли собирать дополнительные данные, создавать более качественные профили пользователей, разрабатывать лучшие алгоритмы согласования и совершенствовать представление информации. Если этот итерационный процесс правильно организован, со временем он будет способствовать улучшению отношений с потребителями, позволяя лучше понять требования клиентов, более точно ориентировать информацию на потребителей и предлагать более качественные рекомендации и услуги.
Вопросы реализации
Чтобы корректным образом реализовать процесс персонификации, надо решить несколько задач. Больше всего потребителей волнуют вопросы конфиденциальности, и компании должны учитывать это при создании своих систем. Прогресс в обеспечении конфиденциальности именно на персонификации сказывается критическим образом. Масштабируемость процесса персонификации — еще один важный момент. Растущие компании должны быть готовы к тому, что им придется работать с миллионами потребителей и десятками тысяч продуктов. Более того, предоставление персонифицированных услуг в оперативном режиме требует эффективных методов профилирования и согласования с требованиями потребителей.
Персонификация — весьма обширная область, и многие компании сосредотачиваются только на отдельных этапах этого процесса. Перечень организаций, занимающихся персонификацией, можно найти на сайтах www.personalization.com и www.personalization.org.
Литература
[1] Comm. ACM, Special Issue on Personalization, vol. 43, no. 8, 2000
[2] D. Pyle, Data Preparation for Data Mining, Morgan Kaufmann, San Francisco, 1999
[3] J.B. Schafer, J.A. Konstan, and J. Riedl, «E-Commerce Recommendation Applications», J. Data Mining and Knowledge Discovery, Jan. 2001
[4] M. Cutler and J. Sterne, «E-Metrics,» NetGenesis Corp., 2000
| Оператор проверки | Принятые правила | Отвергнутые правила | Непрове- ренные правила |
| Ограничение избыточности | 0 | 186727 | 836085 |
| Фильтрация | 0 | 285528 | 550557 |
| Фильтрация | 0 | 424214 | 126343 |
| Фильтрация | 0 | 48682 | 77661 |
| Фильтрация | 10052 | 0 | 67609 |
| Группировка (652 групп) | 23417 | 6822 | 37370 |
| Группировка (4765 групп) | 7181 | 1533 | 28656 |
| Всего | 40650 | 953506 | 1724281 |
