Искусство реферирования, или составления аннотаций, или кратких изложений материала, иными словами, извлечения наиболее важных или характерных фрагментов из одного или многих источников информации, стало неотъемлемой частью повседневной жизни. Новости, которые предлагает нам телевидение, - это суть реферат мировых событий дня. Бегущая строка биржевых котировок - «сухой остаток» информации о купле-продаже, которую ежеминутно порождает рынок. Программа телевидения предлагает короткие анонсы фильмов и телезрители, думая, что листают программку, на самом деле читают реферативный журнал по киноискусству.
Хотя некоторые производители уже сейчас предлагают инструменты для реферирования, объем информации в Сети растет и оперативно получать ее корректные сводки становится все сложнее. Такие инструменты, как функция AutoSummarize в Microsoft Office 97, системы IBM Intelligent Text Miner, Oracle Context и Inxight Summarizer (компонент поискового механизма AltaVista), безусловно, полезны, но их возможности ограничены выделением и выбором оригинальных фрагментов из исходного документа и соединением их в короткий текст. Подготовка же краткого изложения предполагает передачу основной мысли текста, и не обязательно теми же словами.
Текст, полученный путем соединения отрывочных фрагментов, лишен гладкости, его трудно читать. Кроме того, источники информации вовсе не всегда являются текстами, ведь необходимо подготавливать аннотации и на видеозаписи, к примеру, спортивных соревнований, или формировать сводные данные по биржевым таблицам. Перечисленные инструменты реферирования рассчитаны на обработку только текстовой информации. И, наконец, они не могут работать сразу с несколькими источниками. Так, скажем, многочисленные ленты новостей в Web сообщают об одних и тех же событиях, и на этот случай мог бы оказаться полезен инструмент, способный выделить общие места и новую информацию.
Исследователи предлагают несколько подходов, призванных преодолеть эти ограничения. Они распадаются на две категории. В основе подходов, не предполагающих опору на знания, лежит отказ от добавления новых правил для каждой новой прикладной области знания или языка. Подход, опирающийся на знания, исходит из предположения, что если удается понять значение текста, сократить его становится проще, следовательно, полученная в итоге аннотация будет более качественной. Этот подход предусматривает использование базы знаний значительного объема, состоящей из правил, которые извлекаются, поддерживаются и затем адаптируются к новым приложениям и языкам. Впрочем, две эти категории не исключают друг друга. Известны несколько гибридных подходов.
Главным ограничением обоих методов является требование сжатия. Объем аннотации, или реферата должен составлять от 5 до 30% исходного текста. Подготовка аннотаций нескольких источников информации или формирование сводок для карманных устройств предполагает еще большую степень сжатия. Добиться выполнения таких жестких требований очень сложно, поскольку для этого необходим немалый запас знаний.
Еще одну сложность представляет оценка средств реферирования. Необходима гарантия того, что аннотация действительно является адекватной заменой текста, иными словами, пользователь должен быть уверен, что в кратком изложении выражены все основные мысли оригинала. Поэтому методы создания и оценки рефератов должны развиваться параллельно.
Различия средств реферирования
Главное различие между средствами реферирования состоит в том, что они, по существу, формируют - краткое изложение или набор выдержек. Так, выдержки из Геттисбергского обращения Авраама Линкольна могут выглядеть следующим образом: «Восемьдесят семь лет назад наши отцы ступили на эту землю, чтобы создать новую нацию». Краткое изложение того же текста будет звучать так: «В этой речи Авраам Линкольн призывает вспомнить солдат, которые отдали свои жизни в битве при Геттисберге». Оба типа изложения преследуют две основных цели: определить основную (или наиболее важную) мысль оригинала и принять решение о методе сокращения (или сжатия, или «урезания») информации. Однако рефераты различаются по функции [1] и целевым группам пользователей. Так, например, реферат может быть повествовательным, информативным или критическим.
Повествовательные рефераты формируются по классическому принципу извлечения информации: они предоставляют достаточный объем информации, чтобы создать у пользователя представление о соответствующих источниках, с тем чтобы их можно было отобрать для более внимательного прочтения.
Информативные рефераты заменяют собой текст, в основном они содержат основную или новую фактическую информацию в сокращенной форме.
Критические рефераты (или обзоры) сообщают не только суть информации, но и предлагают определенное мнение о ней. Критические рефераты обладают дополнительной ценностью по сравнению с оригиналом, поскольку предлагают выводы, которых нет в самом тексте. Критический реферат Геттисбергского обращения мог бы выглядеть так: «Несмотря на свою краткость, обращение, без сомнения, можно отнести к величайшим речам и истории Америки. Наиболее сильное впечатление оставляют его заключительные слова о власти народа».
Реферат может быть общим или ориентированным на специфического пользователя. Рефераты первого типа ориентируются на широкий круг читателей; к ним не предъявляются какие-либо специальные требования, поскольку реферат не предназначен для какой-то одной группы читателей. Рефераты второго типа, напротив, адресованы конкретному пользователю или группе пользователей с их специфическими потребностями (например, детям). Ориентированный на пользователя реферат обращения может быть, например, таким: «Сейчас мы ведем великую гражданскую войну... Мы должны принять главное сражение этой войны!»
До недавнего времени общие рефераты пользовались большей популярностью, однако, распространение полнотекстовых поисковых механизмов и средств фильтрации информации, адаптирующихся к требованиям конкретных пользователей, приводят к тому, что настраиваемые рефераты приобретают все большее значение.
Методы и архитектуры
Процесс реферирования распадается на три этапа: анализ исходного текста, определение его характерных фрагментов и формирование соответствующего вывода. Большинство современных работ концентрируются вокруг разработанной технологии реферирования одного документа.
Составление выдержек
Метод составления выдержек, предполагает акцент на выделение характерных фрагментов (как правило, предложений). Для этого методом сопоставления фразовых шаблонов, выделяются блоки наибольшей лексической и статистической релевантности. Создание итогового документа в данном случае —просто соединение выбранных фрагментов.
В большинстве методов применяется модель линейных весовых коэффициентов. Основу аналитического этапа в этой модели составляет процедура назначения весовых коэффициентов для каждого блока текста в соответствии с такими характеристиками, как расположение этого блока в оригинале, частота появления в тексте, частота использования в ключевых предложениях, а также показатели статистической значимости. Сумма индивидуальных весов, как правило, определенная после дополнительной модификации в соответствии со специальными параметрами настройки, связанными с каждым весом, дает общий вес всего блока текста U:
Weight(U) := Location(U) + CuePhrase(U) + StatTerm(U) + AddTerm(U)
Весовой коэффициент расположения (Location) в данной модели зависит от того, где во всем тексте или в отдельно взятом параграфе появляется данный фрагмент — в начале, в середине или в конце, а также используется ли он в ключевых разделах, например, вводной части или в заключении.
Ключевые фразы представляют собой лексические или фразовые резюмирующие конструкции, такие как «в заключение», «в данной статье», «согласно результатам анализа» и так далее. Весовой коэффициент ключевой фразы может зависеть также и от принятого в данной предметной области оценочного термина, типа «отличный» (наивысший коэффициент) или «малозначащий» (значительно меньший коэффициент).
Кроме того, при назначении весовых коэффициентов в этой модели учитывается показатель статистической важности (StatTerm). Статистическая важность вычисляется на основании данных, полученных в результате анализа автоматической индексации, при котором исследователи выявляют и оценивают целый ряд метрик, определяющих весовые коэффициенты термина. Эти метрики позволяют выделить документ из числа других в определенном наборе документов.
Одна группа метрик, например, метрика tf.idf, характеризует баланс между частотой появления термина в документе и частотой его появления в наборе документов (как правило, используется с другими метриками частоты и средствами нормализации длины).
И, наконец, эта модель предполагает просмотр терминов в блоке текста и определение его весового коэффициента в соответствии с дополнительным наличием терминов (AddTerm) - появляются ли они также в заголовке, в колонтитуле, первом параграфе и в пользовательском профиле запроса. Выделение приоритетных терминов, наиболее точно отражающих интересы пользователя, - это один из путей настроить реферат или аннотацию на конкретного человека или группу.
На рис. 1 приведена обобщенная архитектура реферирования без опоры на знания. На аналитическом этапе применяется модель линейных весовых коэффициентов, предполагающая выполнение последовательности вычислений частоты и операций сопоставления строк или шаблонов, которые для каждого блока исходного текста выдают весовые коэффициенты четырех типов (Location, CuePhrase, StatTerm, AddTerm). Затем эти коэффициенты суммируются для каждого блока, после чего выбираются n блоков, обладающих наивысшей суммой коэффициентов (значение n может быть определено на основании степени сжатия) для включения в реферат.
|
||||||||
|
|
||||||||
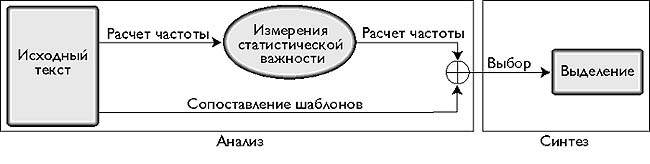
Этот метод был создан еще в 60 - 70-х годах, но большинство систем, подготавливающих такого рода конспект на основе выдержек, до их пор используют подход, проиллюстрированный на рис. 1 [2]. Анализ сравнительных характеристик различных моделей, произведенный с целью определить производительность [3] каждой, показал, что локализацию блоков текста можно считать одной из самых полезных функций, особенно в сочетании с функцией выявления ключевых фраз.
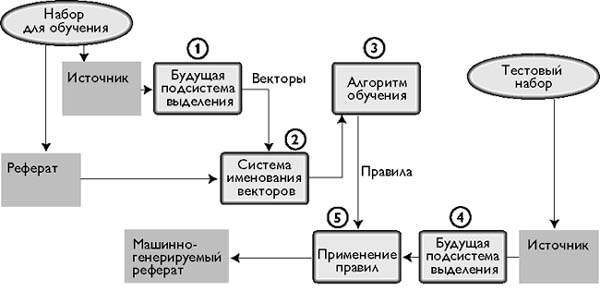
В большинстве систем пользователь задает параметры настройку вручную, и выбор параметров зависит скорее от текущих потребностей, поскольку относительная значимость различных характеристик может сильно различаться для текстов разного стиля. Пытаясь автоматизировать этот процесс и, возможно, повысить производительность, исследователи из Xerox PARC, такие как Джулиан Купьеч и его коллеги, разработали классификатор, способный обучаться правилам выделения фрагментов. На рис. 2 показано, как этот классификатор использует набор определенных пользователем рефератов и соответствующие исходные тексты для автоматического определения критериев адекватного выбора фрагментов.
Этот основанный на собрании документов метод, который используют системы реферирования Inxight, подходит для текстов различных стилей, но для этого пользователи должны располагать полными текстами и соответствующими рефератами для каждого стиля.
Конечно, главное преимущество линейной модели заключается в простоте ее реализации. Однако выделение предложений (или параграфов), не учитывающее взаимоотношений между ними, приводит к формированию бессвязных рефератов. Некоторые предложения могут оказаться пропущены, либо в них могут встречаться «висящие» слова или словосочетания (слово или фраза, которые невозможно понять без другого слова или фразы). Например, если в тексте содержится обоснование некоего положения, состоящее из нескольких фраз, а в реферат попадает только одна из них, смысл может быть потерян или искажен. Можно привести следующий текстовый фрагмент, который иллюстрирует эту проблему. «Билл Диксон поступил на работу в Procter & Gamble в 1994 году. В 1996 году он стал ее вице-президентом». В этом фрагменте можно указать два потенциально «висящих» слова «он» и «ее», которые не имеют смысла без предыдущей фразы, из которой становится ясно, что «он» - это Диксон, а «ее» - это компания Procter & Gamble. Если в реферате первая фраза будет потеряна, текст потеряет свою информативность.
Есть множество работ, в которых делаются попытки решить эту проблему, в основном за счет разного рода «заплаток». В ряде подходов создается специальное окно для предыдущего предложения реферата, с помощью которого можно определить наличие смыслового разрыва или «висящего» слова. В других случаях предложения, содержащие «висящие» слова, исключаются из реферата, либо делаются попытки разрешения ссылок, которые предполагают такие слова, или их сверки путем краткого лингвистического анализа. При таком подходе степень сжатия уменьшается, т. к. в реферат привносится посторонняя информация. Кроме того, когда основной реферат уже сформирован, трудно восстановить исходный процент сжатия.
Формирование краткого изложения
Когда Кельвина Кулиджа однажды спросили, что говорил священник на проповеди о грехе, он ответил: «Он рассказал, чего следует воздерживаться» [4]. Этот ответ служит примером возможностей интуитивного понимания, положенного в основу изложения - человеку, который уловил общий смысл информации, легче выделить главное и изложить вкратце ее содержание.
В отличие от линейной модели в методах подбора выдержек, для подготовки краткого изложения информации, требуются мощные вычислительные ресурсы для систем обработки естественных языков (NLP — natural language processing), в том числе грамматики и словари для синтаксического разбора и генерации естественно-языковых конструкций. Кроме того, для реализации этого метода нужны некие онтологические справочники, отражающие соображения здравого смысла и понятия, ориентированные на предметную область, для принятия решений во время анализа и определения наиболее важной информации.
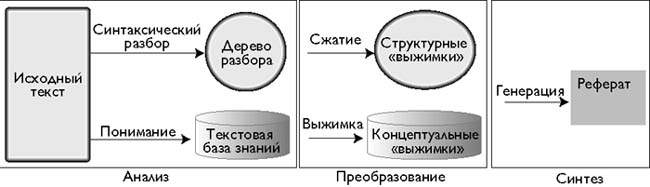
Как показано на рис. 3 метод формирования краткого изложения предполагает два основных подхода. Первый (вверху) опирается на традиционный лингвистический метод синтаксического разбора предложений.
В этом методе применяется также семантическая информация для аннотирования деревьев разбора. Процедуры сравнения манипулируют непосредственно деревьями с целью удаления и перегруппировки частей, например, путем сокращения ветвей на основании некоторых структурных критериев, таких как скобки или встроенные условные или подчиненные предложения. После такой процедуры дерево разбора существенно упрощается, становясь, по существу, структурной «выжимкой» исходного текста.
Второй подход к составлению краткого изложения уходит корнями в системы искусственного интеллекта и опирается на понимание естественного языка [5] Синтаксический разбор также входит составной частью в такой метод анализа, но деревья разбора в этом случае не порождаются. Напротив, формируются концептуальные репрезентативные структуры всей исходной информации, которые аккумулируются в текстовой базе знаний. В качестве структур могут быть использованы формулы логики предикатов или такие представления, как семантическая сеть или набор фреймов. Примером может служить шаблон банковских транзакций (заранее определенное событие), в котором перечисляются организации и лица, принимающие в нем участие, дата, объем перечисляемых средств, тип транзакции и т.д.
Представленный на рис. 3 этап преобразования уникален для реферирования на базе знаний. В процессе преобразования концептуальное представление претерпевает несколько изменений. Избыточная и не имеющая прямого отношения к тексту информация устраняется путем удаления поверхностных суждений или отсечения концептуальных подграфов. Затем информация подвергается дальнейшему агрегированию путем слияния графов (или шаблонов) или обобщения информации, например, при помощи таксономических иерархий отношений подклассов. Для выполнения этих преобразований предложены методологии на базе выводов, такие как макроправила, которые манипулируют логическими предположениями, или операторы, которые выделяют определяющие шаблоны в текстовой базе знаний [7]. В результате преобразования формируется концептуальная репрезентативная структура реферата, по существу, концептуальные «выжимки» из текста.
Наличие этих формальных репрезентативных слоев (структурные и концептуальные «выжимки») отличает подход на базе знаний от подхода, не предполагающего опору на знания. Как видно из рис. 3, этап синтеза одинаков для обоих подходов: текстовый генератор преобразует структурное или концептуальное представление в естественно-языковую аннотацию. Некоторые системы предоставляют пользователю возможность управлять получаемыми «выжимками» методом указания, и не предполагают этапа генерации, при условии, что исходные тексты предоставляются наряду с их кратким изложением. Этот тип реферирования опирается на предварительно определенные структуры знаний, которые заранее указывают системе реферирования, какую концепцию считать более характерной, или какие концептуальные свойства (роли или поля) имеет та или иная концепция. Средство реферирования полностью представляет семантическую информацию в виде связей между узлами в концептуальном графе, как таксономические (подкласс или экземпляр) или метонимические (часть) отношения. В этом случае, он также задает направление и критерии выбора для процедуры поиска или формирования заключений. Правила вывода на базе рефератов или общие схемы вывода (такие как терминологическая классификация) используют эту информацию для определения информации, наиболее точно отражающей существо текста. Эта информация определяет, какие иерархии обобщения должны быть пройдены и какие концептуальные подграфы могут быть при необходимости сжаты. На рис. 4 показаны основы этого процесса.
Выдержки или изложение
Методы извлечения выдержек легко настроить для обработки крупных массивов информации. Поскольку их деятельность ограничена выбором фрагментов, предложений или фраз, текст реферата лишен связности. С другой стороны, метод формирования кратких изложений выдает более сложные аннотации, которые нередко содержат информацию, дополняющую исходный текст. Так как они опираются на формальное представление информационного наполнения документа, их можно настроить на весьма высокие степени сжатия, например, такие, которые требуются для рассылки сообщений на устройства PDA. Методы заполнения шаблонов подходят только для текстов, построенных по определенному шаблону, хотя средства реферирования могут использовать определенные статистические технологии на этапе анализа.
Методы, предполагающие опору на знания, как правило, требуют полноценных источников знаний. Это требование до сих служило препятствием для их широкого распространения. Последние тенденции в области систем NLP на базе наборов текстов сулят в будущем предоставление синтаксических анализаторов, охватывающих широкий диапазон знаний, исчерпывающих словарей (таких как WordNet) и онтологических справочников (таких как CYC или Penman Upper Model). Кроме того, для обучающих систем NLP наработан большой объем текстов, в том числе набор текстовых файлов, таких как The Wall Street Journal, или грамматически аннотированных наборов, таких как Penn Treebank консорциума Linguistic Data Consortium. И, наконец, разработчики средств реферирования все больше склоняются к гибридным системам, а исследователям все более успешно удается объединять статистические методы и методы, основанные на знаниях.
Методы оценки
Целью методов оценки рефератов является определения адекватности (и достоверности) или пользы реферата по отношению к оригинальному тексту. Сейчас известны две методики оценки. Первый - оценка «изнутри» (или нормативная оценка). Пользователи судят о качестве реферата, анализируя сам реферат. Пользователи оценивают гладкость текста, делают вывод о том, насколько хорошо реферат отражает основные идеи оригинала, либо сравнивают его с идеальным рефератом, написанным автором исходного текста или другим специалистом. Ни одна из этих оценок не может считаться полностью удовлетворительной. В частности, идеальный реферат составить исключительно сложно и такие продукты очень редки. Подобно тому, как существует множество способов описать некое событие, пользователи могут признать приемлемыми несколько рефератов, будь то настроенные на пользователя или общие краткие изложения или наборы выдержек. Как показывает практика, люди вообще редко приходят к согласию относительно того, какие положения или выражения следует включать в реферат [8].
Второй метод - оценка «извне». Пользователи оценивают качество реферата по тому, как он влияет на завершение той или иной работы, например, помогает ли он найти источники информации по данному вопросу или насколько хорошо он позволят ответить на определенные вопросы, относящиеся ко всему содержанию текста.
Недавно в США была проведена крупномасштабная оценка систем реферирования. Она проходила в рамках программы Tipster, целью которой было способствовать совершенствованию технологий обработки текстов [9]. Программа предполагала две оценки. На первом этапе пользователь получал возможность ознакомиться либо с источником, либо с рефератом, ориентированным на пользователя, и должен был решить, соответствует ли увиденный им текст заявленной теме. На втором этапе пользователь мог ознакомиться либо с источником, либо с общим рефератом и должен был либо выбрать тему (из нескольких предложенных вариантов), к которой, по его представлению должен был относиться документ, или решить, соответствует ли он хотя бы какой-либо теме. Как видно из таблицы 1, автоматические средства реферирования проявили себя в этом испытании очень хорошо. На основании реферата, составляющего всего от 27 до 10% текста, пользователи могут составить заключение о тексте так же точно, как из него самого, затратив на это вполовину меньше времени (5-процентная погрешность не является статистически значимой).
Таблица 1. Оценка релевантности с использованием рефератов по отношению к полному тексту
| Тип реферата | Сжатие по длине | Сжатие по времени | Потери точности |
| Ориентированные на пользователя | 77% | 50% | 5% |
| Общие | 90% | 60% | 0% |
В ходе этого тестирования не учитывались конкретные методы реферирования; все 16 систем реферирования основывались на подходе, не предполагающем опору на знания. Они различались своей способностью вырабатывать рефераты, ориентированные не пользователя; системы, наиболее точно отражающие потребности пользователей, демонстрировали сходное поведение при выделении предложений.
Новые сферы применения
Сейчас оформляются четыре области, где велика потребность в реферировании. Во всех четырех - средствам реферирования придется иметь дело с такими форматами документов, как HTML и XML. Кроме того, они должны будут пользоваться информацией, заключенной в тегах, связанных с каждым документом. Работа над средствами реферирования гибридных источников и источников на разных языках только начинается, первые прототипы были предложены для реферирования большого числа документов и подготовки аннотаций для мультимедийных источников.
Различные языки
Высококачественные машинные переводчики, обрабатывающие любой ввод, пока остаются предметом мечтаний. Все, на что можно рассчитывать сейчас в этой области, и что может оказаться действительно полезным, - это механизмы фильтрации. Пользователи могут применять такие фильтры для получения одноязычных рефератов, охватывающих информацию из источников на разных языках. После этого нетрудно решить, нужен ли более подробный перевод этих источников.
Гибридные источники
В этих приложениях средства реферирования должны извлекать информацию из отформатированных данных и из неотформатированного текста. Таковы, например, сообщения об игроке футбольной команды, в которых статистическая информация о нем объединена с информацией из базы данных, содержащей сведения о его последних успехах. Такие приложения еще очень новы и не имеют под собой серьезного теоретического фундамента.
Большое число документов
В средствах реферирования этого типа методы реферирования одного документа должны быть распространены на большой набор документов. Объем такого набора может варьироваться от гигабайт до байт. Для обработки разных объемов нужны разные механизмы. Каждый метод предполагает анализ каждого документа набора и извлечение информации из всех в процессе преобразования и синтеза. Средства реферирования по-прежнему должны выполнять операции отсечения информации, ее объединения и обобщения, и при этом иметь дело с набором документов вместо одного. Простое объединение рефератов каждого документа не может считаться удовлетворительным, т. к. при наличии большого числа рефератов они неизбежно будут содержать избыточную информацию.
Средства реферирования должны выявлять сходства и различия во всех документах (что общего, что присуще только одному документу, в чем они различаются) путем сравнения и слияния представлений содержимого документа, полученных на этапе анализа [8, 10, 11]. Так, например, при использовании генератора естественного языка, средство реферирования может формировать по шаблону анонс новости дня о террористическом акте, причем информация о двух событиях находится в двух различных источниках.
По сообщениям агентства «Рейтер» в результате террористического акта совершенного в городе N, погибло 6 человек. Однако AP сообщает о большем количестве жертв.
Поскольку несколько отличающиеся друг от друга сообщения об одном и том же событии нередко появляется в различных источниках информации, были разработаны средства реферирования, которые отбрасывают избыточную информацию из всех сообщений и предоставляют их краткое изложение [12].
Другие средства реферирования могут отслеживать общую тему в различных сообщениях и представлять результаты своей работы при помощи диаграмм и графиков [13].
Мультимедиа
Хотя исследования в этой области находятся еще на очень ранней стадии, растущий объем мультимедийной информации делает ее едва ли не самым важным объектом для обработки средствами реферирования. Соответствующие технологии должны обрабатывать информацию из источников разного типа на этапе анализа, на этапе извлечения и на этапе синтеза, когда происходит интеграция информации разного типа. Существующие методы работы с аудио позволяют вычленять из потока информации законченные фрагменты (иными словами, распознавать периоды тишины в разговоре, смену говорящего, снятие телефонной трубки, а также осуществлять контентный анализ). Есть также технологии обработки видео (определения ключевых элементов и логотипа, например), которые помогают определить существенные ее фрагменты. Так, например, цель одной ведущейся в настоящее время работы состоит в том, чтобы определять содержание, скажем, видеофильмов, при помощи ПО распознавания шаблонов. Оно позволяет определить, какие фрагменты содержат интересные события (например, происшествия, драки, яркие проявления характеров и другие) [14].
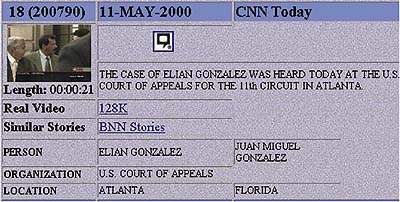 |
|
Рис. 5. Средство реферирования мультимедиа, использует Broadcast News Navigator, который выполняет поиск, просмотр и реферирование теленовостей На экране представлен мультимедийный реферат информационного наполнения видеофрагмента, выданный на запрос поискового механизма. Реферат включает в себя ключевые предложения, а также информацию о наиболее важных персонах, организациях и местоположении, сопровождаемые видео. Нажатие на кадре видео активизирует воспроизведение видеофрагмента при помощи соответствующего плейера. Система предлагает также ссылки на информационные сообщения, которые считаются относящимися к делу. |
На рис. 5 приведен примерный реферат, созданный системой Broadcast News Navigator [15] - средством поиска, просмотра и реферирования телевизионных новостей. BNN опирается на стратегию представления смешанной среды, объединяя ключевые кадры, автоматически извлеченные из видеофрагментов, в аннотации в закрытых текстовых вставках, образованных из захваченных текстовых фрагментов, а также с информацией об организациях, местоположении и участвующих в событиях лицах. Прогресс в области автоматического распознавания речи из аудиоисточников должен стимулировать развитие этих средств реферирования.
В перспективе, во всяком случае, в ближайшей, подход, не предполагающий опору на знания, будет доминировать, особенно в сочетании с механизмами обучения выбору. Приложения на базе знаний могут получать большее распространение в тех предметных областях, для которых существуют достаточно большого размера грамматики и источники знаний. Важно учитывать, что для работы с этими источниками нужны либо специалисты, обладающие широкими познаниями в своей области, либо необходимо сделать упор на методы машинного обучения. Для того чтобы сделать возможной эмпирическую оценку автоматически сформированных рефератов, необходимы дополнительные наборы текстов (и их рефератов).
В целом, отрасль средств реферирования находится в самом начале своего развития. Существует единое мнение о необходимости лучших методов оценки, однако, большинство задач еще не решено, в том числе, сохраняется необходимость в масштабируемых методологиях создания аннотаций. Тем не менее, многие из описанных здесь технологий уже работают, и можно ожидать, что инструменты реферирования будут играть решающую роль в завоевании широких информационных пространств в будущем.
Удо Хан (hahn@coling.uni-freiburg.de) — адьюнкт-профессор университета Альберта Людвигса, Фрайбург (Германия), специализирующийся в области технологий обработки естественного языка. Индерджиет Мани (imani@mitre.org) — научный директор подразделения Information Systems and Technology Division корпорации Mitre.
Литература
[1] H. Borko and C.L. Bernier, Abstracting Concepts and Methods. Academic Press, New York, 1975
[2] R.E. Wyllys, «Extracting and Abstracting by Computer,» Automated Language Processing, H. Borko, ed., John Wiley & Sons, New York, 1967, pp. 127-179
[3] J. Kupiec, J. Pedersen, and F. Chen, «A Trainable Document Summarizer,» Proc.18th Int?l ACM SIGIR Conf. Research and Development in Information Retrieval, E.A. Fox, P. Ingwersen, and R. Fidel, eds., ACM Press, New York, 1995, pp. 68-73
[4] The Giant Book of American Quotations, Grammercy Books, New York, 1992, p. 209
[5] J. Hutchins, «Summarization: Some Problems and Methods,» Proc. Informatics 9: Meaning-The Fron-tier of Informatics, K.P. Jones, ed., Aslib, London, 1987, pp. 151-173
[6] T.A. van Dijk, «Semantic Macro-Structures and Knowledge Frames in Discourse Comprehension,» Cognitive Processes in Comprehension, M.A. Just and P.A. Carpenter, eds., Lawrence Erlbaum, Hillsdale, N.J., 1977, pp. 3-32
[7] U. Hahn and U. Reimer, «Knowledge-Based Text Summarization: Salience and Generalization Operators for Knowledge-Based Abstraction,» Advances in Automatic Text Summarization, I. Mani and M. Maybury, eds., MIT Press, Cambridge, Mass., 1999, pp. 215-232
[8] G. Salton et al., «Automatic Text Structuring and Summarization,» Information Processing & Management, Vol. 33, No. 2, 1997, pp. 193-207
[9] I. Mani et al., «The Tipster Summac Text Summarization Evaluation,» Proc. 9th Conf. European Chapter of the November 2000
[10] I. Mani and E. Bloedorn, «Summarizing Similarities and Differences Among Related Documents,» Information Retrieval, Vol. 1, No. 1, 1999, pp. 35-67
[11] D.R. Radev and K.R. McKeown, «Generating Natural Language Summaries from Multiple Online Sources,» Com-putational Linguistics, Vol. 24, No. 3, 1998, pp. 469-500
[12] J.G. Carbonell and J. Goldstein, «The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries,» Proc. 21st Int?l ACM SIGIR Conf. Research and Development in Information Retrieval, ACM Press, New York, 1998, pp. 335-336
[13] R.K. Ando et al., «Multidocument Summarization by Visualizing Topical Content,» Proc. ANLP/NAACL 2000 Workshop on Automatic Summarization, 2000, pp. 79-88
[14] R. Lienhart, S. Pfeiffer, and W. Effelsberg, «Video Abstracting,» Comm. ACM, Vol. 40, No. 12, 1997, pp. 54-62.
[15] A. Merlino, D. Morey, and M. Maybury, «Broadcast News Navigation Using Story Segments,» Proc. ACM Multimedia 97, ACM Press, New York, 1997, pp. 381-391
The Challenges of Automatic Summarization, Udo Hahn, Inderjeet Mani, IEEE Computer, November 2000, pp. 29-36. Copyright IEEE CS, Reprinted with permission. All rights reserved.
Ресурсы по системам реферирования
AAAI Spring Symposium on Intelligent Text Summarization (Stanford, Calif., March 1998).
ANLP/NAACL 2000 Workshop on Automatic Summarization (Seattle, Wash., May 2000).
COLING-ACL98 Tutorial on Text Summarization (Montreal, Canada, August 1998).
Summarizing Text for Intelligent Communication Symposium (Dagstuhl, Germany, 1993).
TIPSTER Summarization Evaluation Conference (Baltimore, Md., August 1998); www.itl.nist.gov/div894/894.02/related_projects/tipster_summac/index.html
Workshop on Intelligent Scalable Text Summarization (Madrid, Spain, July 1997).
Общие источники: www.cs.columbia.edu/~radev/summariza-tion/; www.mitre.org/resources/centers/iime/aats.html
Assoc. for Computational Linguistics, Morgan Kaufmann, San Francisco, 1999, pp. 77-85
