За последние годы произошел бурный рост продаж систем оперативной аналитической обработки данных (OLAP — online analytical processing) и хранилищ данных (Data Warehouse), однако до сих пор неясен вопрос, в чем же привлекательность этих систем?
Многомерный финансовый анализ, анализ продаж, возврата инвестиций, эффективности работы с заказчиком, анализ прибыльности каждой операции, расходов и себестоимости - обеспечивают преимущества в конкурентной борьбе. Все возможности многомерного анализа предоставляются пользователям на базе инструментария бизнес-интеллекта (BI — Business Intelligence), позволяющего манипулировать данными без знания их структуры, оперируя только понятиями деловой практики: объемы продаж, прибыль и затраты. Более того, быстрое получение подобной информации позволяет исключить из организации звенья-посредники, не генерирующие новой информации, а, следовательно, увеличить эффективность работы организации.
Все эти возможности анализа корпоративных данных появляются при наличии единого источника - хранилища данных. Собственно говоря, для средних и крупных предприятий создание такого хранилища - единственный путь организации оперативной аналитической обработки. Огромные объемы данных, рассредоточенные в корпоративных системах, хранящиеся в различных форматах — от таблиц Microsoft Excel до файлов ISAM на мэйнфреймах, — не позволяют производить достоверные выборки непосредственно из них.
Еще одной проблемой, связанной с тематикой анализа корпоративных данных, является проблема - анализ по наиболее важному из измерений - времени. Большинство данных, хранящихся во внешних источниках, таких как сеть Internet, содержат информацию только о текущем состоянии и поэтому не позволяют проводить такой анализ.
Классическим решением проблемы обеспечения аналитических приложений достоверной, полной и актуальной информацией является построение единого хранилища данных и, в случае необходимости, специализированных проблемно-ориентированных витрин данных. Построение хранилища или витрины данных — это процесс из нескольких этапов: сбор требований к хранимым данным, анализ способов их извлечения, реализация процессов загрузки данных в хранилище/витрину и пр. По оценке InfoWorld, наибольшие затраты, как правило, приходятся именно на последний этап, называемый как ETL (extraction, transformation & loading) - экстракция данных из источников, трансформация их в подходящую для загрузки в хранилище/витрину данных форму и собственно загрузка.
При попытке интеграции исходных данных пользователь оказывается перед выбором — либо объединять их с помощью множества программ-конверторов, что предполагает разработку кодов собственных программ преобразования, очистку и проверку данных, либо воспользоваться универсальным инструментом создания хранилищ данных. Исключением являются организации, внедрившие продукты, содержащие интегрированные средства OLAP. Но, как правило, такие продукты ориентированы на узкоспециализированные области - бухучет, управление запасами, и не позволяют проводить анализ в смежных областях.
Рассмотрим подробнее подходы компании Informix Software к промышленному решению проблем ETL-сферы. Отличительной особенностью предлагаемых компанией решений (DataStage и Formation) является ориентация на максимально комплексное и универсальное решение проблемы, минимизирующее использование нестандартных компонентов. Так, одной из особенностей DataStage является независимость от операционных систем, форматов данных и прикладных систем. Основные операции по экстракции данных, преобразованию форматов, проверке достоверности, интеграции, загрузке в хранилище обеспечиваются за счет существующих модулей расширения (plug-in) - программ, хранящихся в репозитории. Существует множество стандартных модулей расширения для различных источников данных, для различных систем, обеспечивающих функционирование хранилищ данных: Oracle, Red Brik, Terradata... Для проектировщика хранилищ предоставляется возможность создания собственных модулей расширения.
Все существующие сегодня ETL-инструменты можно разделить на две большие группы. С одной стороны отдельные поставщики, работающие с реляционными или многомерными серверами СУБД, включают в свои решения узкоспециализированные средства загрузки данных, ориентированные исключительно на свои серверы. К таким продуктам можно отнести, например, Oracle Express Relational Access Manager и Hyperion Essbase. С другой стороны, существуют и универсальные средства, которые обеспечивают загрузку из альтернативных источников данных в различные типы целевых приемников, производя при этом разные преобразования.
В рамках своего комплексного решения Informix Decision Frontier (IDF) компания Informix предлагает два универсальных ETL-инструмента: DataStage и Formation. Кроме того, к IDF относятся, в частности, следующие продукты: Extended Parallel Server; Red Brick Decision Server; MetaCube; Seagate Info.
Extended Parallel Server — реляционный сервер СУБД, который в рамках Decision Frontier позиционируется как средство поддержки первичного хранилища детальных фактов или operational data store (ODS), содержащего совокупную актуальную информацию операционной среды.
Red Brick Decision Server — специализированный ROLAP-сервер, обладающий дополнительными функциями (оптимизация запросов типа star join, материализованное хранение результатов агрегация, оптимизация массовой загрузки и проч.), ориентирующими его на поддержку витрин данных.
MetaCube — средство аналитической обработки данных (построение отчетов, графиков, поиск тенденций и проч.).
Seagate Info — приобретенный программный продукт, предназначенный для построения отчетов по накопленным данным (функциональность частично пересекается с MetaCube).
Informix Formation
Данный программный продукт позволяет, как и большинство представителей этой группы, визуально описать с помощью специализированного языка диаграмм последовательность действий по экстракции данных из источников, трансформации и, наконец, загрузке в целевую схему (рис. 1).
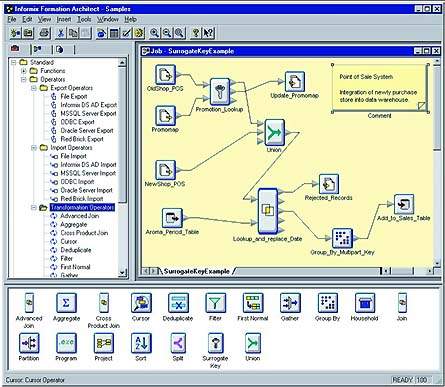 |
| Рис. 1. Рабочий экран Informix Formation Architect |
Formation состоит из двух компонентов: Architect (клиент) и Flow Engine (сервер). Architect предоставляет графический пользовательский интерфейс, в рамках которого пользователь задаёт диаграммы потоков данных в рамках ETL-процессов (рис. 1). После завершения составления диаграмм генерируется исходный код на языке C++, построенный на базе специализированных библиотек. Данный подход унаследован от ETL-продуктов первого поколения, которыми реально мог пользоваться только квалифицированный программист.
Серверный компонент (flow engine) обрабатывает исходный код на C++ и формирует набор исполняемых файлов, которые могут быть запущены для того, чтобы реально произвести соответствующие ETL-действия. Серверный компонент отвечает также за отслеживание хода выполнения этих работ. В отличие от клиентской части, тесно привязанной к Win32 платформе, серверная часть может исполняться как на Windows NT, так и на Sun Solaris и HP-UX. При этом утверждается, что в рамках всех этих операционных систем серверная часть продукта поддерживает интеллектуальное распараллеливание работ. В качестве источников данных могут применяться:
- Informix Dynamic Server (или Informix Extended Parallel Server или Informix Dynamic Server with Advanced Decision Support);
- Informix Red Brick;
- Oracle 7/8;
- Microsoft SQL Server;
- подключение к реляционным ODBC-источникам.
Отсутствуют возможности доступа к плоским файлам и базам данных для мэйнфреймов (DB2, IMS, VSAM).
Среди функций Formation, имеющих отношение к проблематике очистки данных можно найти функцию фильтрации данных по заданному условию со сбрасыванием «отбракованных» записей в специальные таблицы. Остальные работы по очистке (отслеживание незаполненных значений, несовпадение типов данных, неиспользуемые поля, дублирующиеся записи и пр.) предоставляются пользователю, который должен задавать соответствующие условия при обычных способах обработки (фильтрация с отбраковкой, фильтрация со слиянием записей, отображение полей исходных таблиц на поля целевых таблиц и пр.).
Informix DataStage
Данный ETL-продукт во многом подобен Formation, например, имеет средство визуального проектирования диаграмм ETL-процессов (рис. 2). Он состоит из клиента и сервера, один из которых предназначен для ведения репозитория проектов, а другой - для выполнения и отслеживания хода работ уже спроектированных ETL-задач, но обладает рядом существенных отличий.
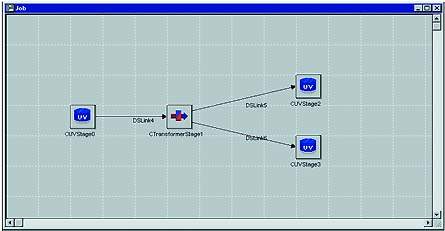 |
| Рис. 2. Рабочий экран Informix DataStage Designer |
Существенное отличие: существует репозиторий проектов DataStage, позволяющий организовывать распределенную работу проектировщиков хранилища или витрин данных. Несмотря на то, что в DataStage происходит предварительная компиляция, она производится не путем преобразования в C++, а затем в исполняемые коды, а из внутреннего описания в репозитории - во внутренний байт-код. Это с одной стороны даёт все преимущества подлинной кроссплатформности (один и тот же ETL-проект может выполняться на серверах DataStage для различных платформ), а с другой - позиционирует DataStage как средство построения витрин данных, (первичного хранилища детальных фактов). В случае с «витринами» объемы существенно меньше, что в случае с интерпретируемым байт-кодом неизбежно приводит к потере производительности. Хотя, если рассматривать чисто функциональные возможности DataStage, то ничто не препятствует и такому применению данного программного продукта.
В качестве потенциальных источников DataStage поддерживает те же данные, что и Formation и, кроме того:
- SyBase;
- UniVerse (СУБД компании Ardent, предыдущего владельца данного продукта; относится к классу «унаследованных» СУБД);
- другие «унаследованные системы».
На этапе трансформации можно производить традиционные для ETL-инструментов преобразования (сортировка, агрегация и пр.), а также дополнительные действия, такие как смена представления данных с сохранением степени гранулярности, преобразование записей типа «уровень» (по состоянию на такую-то дату некоторый показатель имел такое-то значение) в записи типа «факт» (такого-то числа данный показатель изменился на столько-то) и другие.
Существуют возможности по очистке данных - фильтрация некорректных записей, коррекция ошибок, обновление устаревших данных и проч. Имеются также расширенные возможности по загрузке данных в целевую схему - загрузку можно производить как в режиме «по записи», так и в режиме «обновление целой таблицей». Существует возможность подсоединить к системе собственные расширения, обеспечивающие оптимальную загрузку в нестандартные системы. Загрузчик старается по возможности распараллелить процесс загрузки и утилизировать все доступные ему ресурсы.
Говоря о расширениях, следует отметить одну особенность DataStage, существенно отличающую его от других ETL-инструментов - этот продукт позволяет дополнять «известные» ему алгоритмы трансформации и очистки данных новыми, написанными на языке Visual Basic, что делает его продуктом с открытой архитектурой. Это позволяет расширять функциональность системы пользовательскими «добавками». Также существует возможность добавлять новые типы источников данных.
DataStage реализован на основе промышленной СУБД UniVerse производства Informix, поддерживающей многомерные данные. В DataStage используются производительные механизмы обработки и передачи данных, поддерживаются хэшированные таблицы с размещением в оперативной памяти увеличивающие скорость доступа к промежуточным данным.
Промышленные версии DataStage включают в себя MetaStage - мощное средство для управления, согласования и интеграции метаданных различных продуктов проектирования и разработки приложений. MetaStage позволяет вывести технологию разработки корпоративных систем на новый уровень.
Об авторах
Павел Кириллов (pavel@lanit.ru) — сотрудник компания ЛАНИТ.
Илья Шабаев (ila@ipmce.ru) — директор компании АРК.
