Это связано с тем, что технологии поиска, к сожалению, не развиваются в соответствии с темпами роста масштабов Web.
Традиционная поисковая технология (см. врезку « Традиционная технология информационного поиска в Web») работает следующим образом: пользователи вводят ключевые слова, затем поисковые службы просматривают Web-страницы на предмет наличия этих слов. Такой подход неизбежно порождает ряд всем известных проблем.
Прежде всего, для успешного завершения поиска пользователю необходимо подобрать адекватные ключевые слова. Если слова выбраны общие или чересчур многозначные, то на выходе мы рискуем получить слишком много информации, не имеющей никакого отношения к интересующему нас предмету. Например, если введены ключевые слова «history of rock», результат поиска может содержать ссылки на страницы о популярной музыке, геологии или исторических курсах университета. В том случае, если ключевые слова выбраны неверно, пользователь получит совершенно ненужные ему ссылки, если вообще что-либо получит. «В сущности, происходит вот что: булевы методы поиска, изобретенные в 60-х и 70-х годах, истощили свой ресурс», - считает Кевин Вербах, выпускающий редактор информационного бюллетеня Release 1.0, посвященного новым коммуникационным и компьютерным технологиям.
Для разработки адекватных технологий поиска есть ряд важных экономических стимулов. Многие поисковые службы, в том числе AltaVista, Excite, Lycos и Yahoo, превращают свои Web-страницы в информационные порталы, из которых можно получить доступ к разнообразным службам, включая поисковые машины, электронные магазины, информацию о котировке акций, прогноз погоды, чаты и др. Компании заинтересованы в том, чтобы привлечь к своим порталам как можно больше пользователей, поскольку от этого напрямую зависит размер платы, которую они смогут назначить своим рекламодателям и партнерам за размещение информации на сайте. На рис. 1 показаны пять Web-узлов, которые в мае 1999 года посетило наибольшее число пользователей.
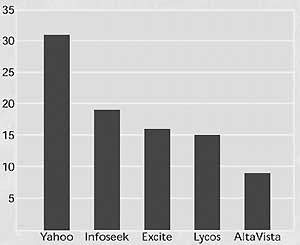 |
| Рис. 1. По данным компании Media Metrix, предоставляющей услуги измерения для Internet и цифровых средств передачи, наибольшее число пользователей в мае 1999 года собрали поисковые сайты Yahoo, Infoseek, Excite, Lycos и AltaVista. |
В борьбе за пользователя службы поиска играют ключевую роль - для многих людей главной причиной первого обращения к порталу является необходимость найти ту или иную информацию. Более того, по данным Nielsen Media Research (компания, которая занимается измерением уровня используемости компьютеров и Internet), к поисковым службам обращается около 71% всех пользователей Internet.
Однако сейчас, как отмечает Вербах, потребители информации считают современные поисковые машины примерно равными по своим возможностям. Так что, как правило, пользователи при выборе того или иного портала руководствуются иными причинами, нежели наличием определенной поисковой службы. Но если компания предлагает технологию поиска, которая существенно отличается от остальных, то вполне вероятно, что ее портал действительно привлечет большее количество пользователей. Поэтому сегодня так активно ведутся исследования в области новых технологий и методов поиска.
Проблемы
Размеры Web - это большое препятствие на пути к совершенствованию технологии поиска. Всего насчитывается около 350 млн. Web-страниц, а поисковая служба Alta Vista, которая является одной из самых информационно насыщенных, индексирует только 140 млн. страниц. При этом Web постоянно меняется - появляются новые ресурсы, ликвидируются устаревшие страницы. По оценкам Research Institute компании NEC, более 5% результатов поиска с помощью одной известной поисковой службы составили неверные или уже несуществующие, «мертвые», ссылки.
На стадии изучения находятся несколько новых, усовершенствованных методов поиска в Web. В некоторых поисковых службах, например, увеличивают размеры индексов, пытаясь тем самым обеспечить пользователя более широким спектром ссылок на нужную ему информацию.
Человеческий фактор
Метод использования человеческого фактора (human annotation) предполагает поиск не по ключевым словам, а по реакции пользователей на результаты, полученные ими во время прежних обращений к механизму поиска. Сторонники этого подхода считают, что на основании результатов предыдущих сеансов поиска, а также информации о том, ссылки на какие страницы Web-мастер решает включить в свой сайт, можно лучше понять, какие именно сайты удовлетворят требованиям нового поиска. Они отмечают также, что этот метод не позволяет администратору того или иного Web-узла свободно манипулировать поисковыми службами путем подбора ключевых слов.
Однако, по мнению Вербаха из Release 1.0, такой подход снижает эффективность работы поисковой службы, поскольку он заставляет ее всегда реагировать на результаты прежних обращений и оставляет мало свободы для удовлетворения потребностей новых пользователей.
Служба поиска Direct Hit использует технологию под названием Popularity Engine, применяющую специальный алгоритм отслеживания пользователей в ходе выполнения поисковых запросов. Как отмечает Гари Галлисс, один из создателей Direct Hit, это отслеживание проводится анонимно и не позволяет установить соответствие между определенными IP-адресами и Web-страницами. Popularity Engine следит за тем, какие Web-страницы посещает пользователь, сколько времени он проводит на каждом узле и какие гиперссылки выбирает. Direct Hit использует эту информацию, чтобы оценить, насколько данный Web-узел соответствует поисковому запросу. По мнению Галлисса, благодаря этому методу пользователь становится редактором поиска.
В поисковой службе Google, придуманной аспирантами Стенфордского университета Серджем Брином и Ларри Пейджем, объединены принципы поиска по ключевым словам и метод human annotation. Google использует собственный механизм сканирования Web-страниц Googlebot. Вместо ключевых слов Googlebot ищет гиперссылки. Для заданного предмета ведется поиск Web-страниц с гиперссылками на другие страницы, которые, по предположению Googlebot, соответствуют этому предмету. В основе Googlebot лежит метод сопоставления текстов и ряд других механизмов. Поисковая служба Google присваивает таким страницам первые места в своей классификации, и, с большой долей вероятности, именно они будут возвращены пользователю в ответ на поисковый запрос.
Компания IBM разрабатывает технологию поиска под названием Clever, в которой используется алгоритм HITS (Hyperlink-Induced Topic Search). Эта технология начинает со стандартного поиска по ключевым словам, позволяющего получить базовое множество страниц. Затем ведется поиск документов, которые имеют ссылки на эти страницы или на которые ссылаются страницы из базового множества. Clever классифицирует страницы базового множества и связанные с ними страницы по количеству ссылок на них. Страница, ссылку на которую посчитало нужным поместить на свой сайт значительное число Web-мастеров, получает название authority и считается ценным источником информации. Узел, имеющий ссылки на множество authority-страниц, называется хабом (hub) и рассматривается как ценный источник ссылок.
Быстрее, еще быстрее
Разработчики компании Fast Search&Transfer (www.fast.no) стараются максимально увеличить скорость работы своей поисковой службы (www.alltheweb.com), используя для этого несколько методов.
Как отмечает вице-президент компании Рей Ромагноло, благодаря масштабируемости архитектуры в этой поисковой системе среднее время отклика на сложный запрос не превышает одной секунды, тогда как в большинстве поисковых служб оно составляет от 4 до 4,5 секунд. Такой высокой производительности удается достичь благодаря нескольким факторам: быстрым алгоритмам индексации, большим массивам серверов, системе хранения и средствам межсоединения, а также программному обеспечению, эффективно использующему серверные возможности.
В Fast Search&Transfer считают, что масштабируемая архитектура позволит поисковой службе компании эффективно справиться как с ростом количества поисковых запросов, так и с постоянным увеличением числа Web-страниц. Индекс этой поисковой службы включает 80 млн. страниц и в ближайшем будущем должен вырасти до 200 млн. Если это произойдет, служба поиска Fast Search&Transfer будет иметь один из самых больших индексов.
Фильтрация
Поисковые службы iAtlas и Northern Light используют технологию фильтрации, которая позволяет получить результаты, наиболее близкие к предмету запроса. При обращении к службе поиска по ключевым словам пользователь заполняет электронную форму, в которой сообщает, что ему нужна, например, информация только по определенным отраслям промышленности или по конкретным регионам.
«При поиске нужно учитывать род занятий пользователя и его задачи, - считает Курт Монаш, исполнительный директор и один из основателей компании Elucidate Technologies, которая занимается разработкой различных программных продуктов, в том числе связанных с поисковыми службами. Это сделает поиск более точным.». Правда, если пользователь задаст слишком общие критерии фильтрации, он рискует потерять потенциально нужные результаты.
Естественный язык
Некоторые службы поиска уже имеют возможность обрабатывать запросы на естественном языке. Например, в Ask Jeeves пользователь, который собирается продать свой автомобиль, вместо одного или нескольких ключевых слов может ввести такой вопрос: «Сколько баксов я могу выручить за свою тачку?». Поисковая служба отошлет его на сайт, предоставляющий информацию о рыночных ценах на подержанные автомобили.
Механизмы поиска по запросам на естественном языке анализируют грамматическую структуру запроса и определяют его смысл, а затем используют результаты данного анализа для поиска по ключевым словам. Однако, как отмечает Джон Лафферти, профессор факультета компьютерных наук и Института языковых технологий университета Карнеги Меллон, применение естественного языка пока не имело большого успеха. По его мнению, технология поиска по запросам на естественном языке еще не в состоянии провести эффективный грамматический разбор запроса из-за недостаточной зрелости применяемых для этого алгоритмов. Монаш из Elucidate не согласен с Лафферти: «Для меня очевидна продуктивность поисковых служб типа Ask Jeeves, поскольку по своей структуре большинство запросов на самом деле одинаковы».
Каталоги
Некоторые поисковые узлы представляют собой каталоги. Недавно компания Netscape Communications приобрела два проекта: NewHoo Community Directory Project и Open Directory (http://dmoz.org). В последнем на некоммерческой основе участвуют эксперты по различным областям знаний. В их задачу входит создание и сопровождение каталогов Web-сайтов, которые предоставляют информацию по интересующей данного эксперта предметной области. Ряд поисковых служб, в том числе HotBоt и Lycos, приобрели патент на использование Open Directory.
Сторонники такого подхода заявляют, что благодаря привлечению экспертов-волонтеров проект сможет расширяться по мере роста Internet. Есть, правда, определенные сомнения в том, будет ли труд добровольных экспертов столь же эффективным, как создание каталогов специалистами, нанятыми и обученными компаниями-разработчиками поисковых служб.
Усовершенствованная технология поиска нужна и военным. Центр космических и военно-морских систем (Space and Naval Wafare Center) агентства DARPA вложил 2 млн. долл. в разработку технологии классифицирующего поиска, которая ведется в университете штата Миссисипи.
Что касается коммерческих поисковых служб, то, как отмечает Вербах, они, скорее всего, будут стремиться занять каждая свою нишу и предоставлять информацию лишь на определенные темы и/или индексировать только определенное множество документов.
Будущее поисковых служб Web-порталов, по всей видимости, связано не с одним, а сразу с несколькими новыми методами поиска, которые сейчас осваивает передовой отряд поисковых машин.
Об авторe
Илан Гринберг (Ilan Greenberg) - независимый автор из Сан-Франциско, специализирующийся на проблемах сетевых технологий. С ним можно связаться по электронной почте ilang@ix.netcom.com.
Ли Гарбер (Lee Garber) - редактор новостей журнала Computer. С ним можно связаться по электронной почте l.garber@computer.org
Searching for new search technologies, llan Greenberg and Lee Garber, - IEEE Computer, August 1999, pp. All rights reserved.
Традиционная технология информационного поиска в Web
В 1990 году в университете МакГилл в Монреале был разработан Archie - первый механизм поиска в Internet. Archie ищет файлы на FTP-серверах. В этот период были сделаны еще две поисковые машины для поиска на серверах службы gopher: Veronica, разработанная в 1992 году в Университете штата Невада и Jughead, созданная в 1993 году в Университете штата Юта.
Существующие службы поиска разделяются на поисковые машины и каталоги.
Поисковые машины (такие как AltaVista и HotBot) традиционно включают три компонента: программу сканирования (crawler), индекс и программное обеспечение поиска. Crawler, или spider (паук) - это программа, которая автоматически просматривает различные web-сайты и создает индексы ресурсов URL, ключевые слова, ссылки и текст. Программа-сrawler может также переходить по расположенным на сайте ссылкам на другие, близкие по содержанию, страницы. При этом она периодически возвращается к исходным сайтам, чтобы проверить, не произошли ли какие-нибудь изменения. Когда пользователь делает поисковой машине запрос, ее программное обеспечение проходит по созданному индексу в поиске Web-страниц с заданными ключевыми словами и классифицирует эти страницы по степени близости к предмету поиска.
Каталоги (например, LookSmart и Yahoo) работают не с индексами, а с описателями Web-страниц, составленными либо Web-мастерами, либо специальными редакторами, которые просматривают Web-страницы. В ответ на запрос каталоги выполняют поиск по этим описателям. Некоторые поисковые машины, например, Microsoft MSN и Netscape Search, на самом деле являются гибридными технологиями, поскольку тоже используют каталоги. В каталогах не применяется программа-сrawler, поэтому они не могут автоматически обнаружить изменения Web-страниц. Однако сторонники этого подхода настаивают на том, что для ряда запросов результаты, полученные по описаниям подготовленным человеком, могут оказаться более осмысленными.
Обычно поисковая машина получает от пользователя одно или несколько ключевых слов вместе с булевыми операторами «И», «ИЛИ», «НЕ» и просматривает индексированные Web-страницы в поиске этих ключевых слов. Для определения порядка вывода результирующих страниц поисковая машина использует алгоритм классификации сайтов, которые содержат заданное ключевое слово.
Поисковый механизм может, например, подсчитать, сколько раз ключевое слово встречается на странице. Он также может искать ключевое слово в метатэгах (matatag), то есть тэгах HTML, которые предоставляют информацию о Web-странице. В отличие от большинства HTML-тэгов метатэги никак не влияют на внешний вид документа. Они содержат сведения об информационном наполнении Web-страницы и некоторые его ключевые слова.
Раньше некоторые администраторы сайтов нарушали нормальную работу машины поиска по ключевым словам, забив ключевыми словами всю свою Web-страницу или поместив в метатэги ключевые слова, не имеющие никакого отношения к содержимому их узла. Но разработчики поисковых служб нашли способ противодействия: либо службы вообще не сканируют метатэги, либо ставят на нижние позиции в своей классификации те узлы, которые используют ключевые слова, не имеющие отношения к их реальному содержимому.
