В обозримом будущем компьютерный мир ожидают три потрясения: наступление нового тысячелетия, экспансия архитектуры Intel в лице процессора Merced и беспрецедентное расширение электронных сетей. Первые два - темы для других романов, а вот сетевые проблемы имеют прямое отношение к нашей статье. Скорее всего компьютеры, даже самые маленькие, уже никогда не будут чувствовать себя одинокими. Однако, как бессмысленно ставить несколько компьютеров рядом, точно также мало просто соединить их сетью. Банально, но система - это не просто объединение элементов. Если говорить о новом качестве, то хотелось бы получить возможность согласованной работы совокупности индивидуальных установок, включая совместное использование процессоров, памяти и т.д.
Несмотря на обилие разнообразных подходов и продуктов по сетевой тематике, положение сегодня оставляет желать лучшего. Такая оценка основана на том, что для создания сетевых распределенных приложений прикладным программистам в очередной раз предлагаются средства, специально рассчитанные на сеть.
Прозрачность сети для приложений - по-видимому, дело будущего, но уже сейчас в этом направлении сделаны конкретные шаги. В частности, очень любопытные подходы применяются для управления современными распределенными корпорациями и предприятиями. Общие архитектурные принципы и критерии оценки такого рода систем рассмотрены в [1]. Подробный (и, что приятно, компактный) обзор положения дел в этом сегменте компьютерной индустрии опубликован в [2]. Технология работы с конкретной системой управления информационной инфраструктурой предприятия описана в статье [3]. На основании этих работ, можно сделать вывод, что сегодня происходит переход от платформ управления сетями к новому уровню сервиса - управлению бизнес-процессами. В условиях компьютеризированного предприятия требуется не только отслеживать состояние сетей и их компонентов, но и владеть информацией о прикладном программном обеспечении, системах управления базами данных, серверных и клиентских системах. Соответственно происходит смена лидеров: традиционные "сетевики" SunSoft, Cabletron и Hewlett Packard уступают свои позиции Tivoli/TME, CA/TNG и BMC/Patrol. К числу новых лидеров можно смело отнести и компанию Siemens Nixdorf (SNI) с предлагаемой ею платформой TransView.
1. TransView - управление гетерогенной информационной инфраструктурой
В основе концепции TransView лежат два принципа. Первое: все разнообразие задач управления предприятием не может полностью покрываться одним продуктом. Второе: система управления предприятием должна быть открытой, способной интегрировать существующие специфические приложения заказчика, а также независимые приложения в единое решение.
Исходя их этих положений, сама SNI разрабатывает решения для реализации основных функций, таких как интеграция приложений, управление сетями и печатью, управление приложениями SAP R/3 и т. п. Кроме того, компания использует решения от независимых поставщиков - интегрируемые в TransView продукты составляют обширный каталог. Таким образом, стратегия развития TransView предполагает, во-первых, создание возможностей простого включения перспективных технологий, появляющихся на рынке, и, во-вторых, концентрацию собственных разработок на основных продуктах.
Имеющая открытую архитектуру и поддерживающая стандарты рынка TransView подходит для управления гетерогенными распределенными системами. Компоненты TransView реализованы на самых распространенных платформах: мэйнфреймах (BS2000), UNIX, NT и Windows.
Архитектура TransView открыта для других распространенных на рынке управляющих платформ: Open View Network Node Manager, Distributed Manager (OSI/CMIP) компании HP, MS System Management Server (SMS). Для специфических управляющих систем разных поставщиков (IBM NetView, Novell NetWare, CA Unicenter) TransView предлагает шлюзы управления. Эта система способна управлять широким спектром ресурсов: клиентами, серверными устройствами от разных производителей, периферийными устройствами (даже говорящими автоматами), а также приложениями.
TransView - это несколько продуктов (Рис. 1), построенных на стандарте SNMP и наследующих от него принцип распределенного управления менеджер/агент.
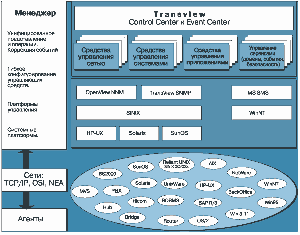 (1x1)
(1x1)Архитектура системы TransView
TransView Control Center служит главной интеграционной платформой для всех остальных продуктов TransView и специфических приложений пользователей. Однородная управляющая платформа TransView Control Centre создает условия для мониторинга и управления сложными информационными средами, комбинируя преимущества централизованного администрирования и распределенной обработки.
TransView Event Center позволяет коррелировать события и статусную информацию из различных источников (систем, приложений, сетевых элементов), анализировать события и определять автоматическую реакцию на них.
TransView SAX выполняет задачи управления программным обеспечением: администрирования, распространения и инсталляции в гетерогенных средах LAN/WAN. Управление относится к пользовательскому ПО, ОС и любым данным.
TransView LIVE Network Integrator - инструмент для централизованного и однородного администрирования и мониторинга систем типа SAP R/3 (компания SNI первой предложила централизованный мониторинг и управление системой R/3 через развитый графический интерфейс).
2. Control Center - интеграция управляющих приложений
Разнообразные задачи управления распределенной гетерогенной инфраструктурой не следует решать в рамках одной замкнутой системы, это одна из базовых посылок архитектуры TransView Control Center (TCC). Для каждой области, будь то управление системами, сетями или приложениями, требуется свое оптимальное решение, и сверх того, на каждом предприятии останутся свои специфические проблемы. Следовательно, полная система управления информационной инфраструктурой должна быть скорее конгломератом приложений.
TCC - это платформа интеграции набора относительно независимых продуктов для разных задач управления в полное, открытое и унифицированное решение. Важность такого рода средства определяется, по крайней мере, двумя обстоятельствами.
Во-первых, представьте себя в роли оператора предприятия, который должен одновременно следить за работой многочисленных систем (включая периферию - диски, роботизированные хранилища данных, устройства печати), обеспечивать их равномерную загрузку, следить, чтобы в сети не возникало заторов и поддерживать время ответа корпоративных баз данных в установленных пределах. Боюсь, что от одного перечисления может закружиться голова. Если каждую функцию мониторинга будет выполнять отдельное приложение со своим собственным пользовательским интерфейсом, оператору придется постоянно переключать внимание с одного продукта на другой - вряд ли кто-нибудь сможет с этим справиться.
Во-вторых, разработку управляющего приложения начинать каждый раз с нуля практически невозможно, особенно в производственных условиях, когда приложение должно работать в многоплатформной аппаратной и операционной среде.
Принимая во внимание эти два обстоятельства, необходимо дать и пользователям, и разработчикам единую концепцию управления, подкрепленную базовым программным аппаратом - именно это называют платформой управления.
Первое положение концепции управления TCC следующее: все разнообразные функции сводятся в одну центральную "Точку Управления и Администрирования". Обслуживаемые узлы могут быть разнесены на тысячи километров, на них могут работать разные приложения, но все операции выполняются из центрального пункта.
Основу интеграции приложений составляет несколько понятий: объект управления, событие, сообщение и реакция на сообщение. В гетерогенной среде даже однотипные ресурсы различаются - сетевое оборудование (мосты, маршрутизаторы) может быть разных моделей от разных производителей, а в качестве обрабатывающих хостов могут использоваться рабочие станции и ПК с различными операционными системами. Тем не менее, можно выделить абстрактный уровень, в котором несущественные с точки зрения управления различия стираются, и ресурсы становятся однородными. Это и есть понятие объекта управления. Объектами могут быть хосты, их периферия, компоненты сетевого оборудования, линии передач данных, пакеты ПО, приложения и т. д; в графическом интерфейсе TCC все они представляются унифицированно - пиктограммами. Разумеется, у каждого объекта есть масса собственных атрибутов, например местоположение, производитель, текущее состояние. До них тоже можно добраться, но это уже функция частных приложений, а поскольку есть интеграция, они запускаются тут же - из окна TCC.
Таким образом, абсолютно все приложения, интегрированные в TCC, можно запускать с центрального пункта управления. Конечно, любая операционная среда позволяет это делать, но здесь мы имеем дело с распределенной системой, и приложения запускаются не на сервере TCC, а там, где укажет оператор. В отличие от традиционных средств удаленного запуска (Telnet, Remote Shell, Remote Exec) входить в целевую систему, искать исполняемый файл приложения в дереве каталогов конкретной машины не нужно, а это уже определенное достижение.
С точки зрения управления, больший интерес представляют приложения, способные генерировать сообщения о событиях, происходящих в контролируемых объектах. Обеспечиваемая TCC базовая поддержка определяет схему, по которой сообщение о зарегистрированном событии пересылается в центральный пункт TCC. Здесь все сообщения централизованно запоминаются, анализируются, и, как результат, по ним инициируются предопределенные действия. В простейшем случае реакцией на сообщение может быть оповещение персонала путем вывода на экран TCC текста сообщения, изменения цвета пиктограммы объекта управления или подачи звукового сигнала. Возможна и другая реакция. Допустим, приложение, обслуживающее принтер, сгенерировало сообщение о событии "Закончилась бумага". TCC может быть сконфигурировано так, что при поступлении этого сообщения ответственному лицу посылается e-mail с просьбой заправить новую пачку бумаги. Для некоторых других ситуаций и соответствующих сообщений TCC может автоматически запустить графический интерфейс программного управления принтером, и все необходимые действия оператор выполнит непосредственно из окна TCC.
2.1. Централизованный мониторинг приложений
С точки зрения архитектуры TransView Control Center представляет собой распределенную программную систему, состоящую из Менеджера TCC, который выполняется на центральном узле сети, и множества агентов, работающих на других узлах (причем эти узлы могут быть разноплатформенные - NT или UNIX) и собирающих всю оперативную информацию. Функция агентов - мониторинг приписанных к ним приложений.
Агенты бывают двух видов: собственные агенты TCC и специальные агенты для отдельных управляющих приложений. Первые рассчитаны на определенный протокол взаимодействия с приложениями, которые записывают свои сообщения в Log-файл, а агенты достают их оттуда и переправляют Менеджеру. Один такой агент способен параллельно вести несколько приложений, в то время как специальный агент осуществляет мониторинг только "родного" приложения. На каждой целевой системе может выполняться несколько агентов, и полная картина выглядит как множество групп агентов, посылающих сообщения серверу TCC.
Менеджер и агенты взаимодействуют по протоколу SNMP через Информационную Базу Управления - MIB, содержащую определения всех объектов и атрибутов. Сообщения передаются путем присваивания конкретных значений атрибутам, например, адреса системы, в которой произошло событие, или текста сообщения. Для каких-то интегрируемых в TCC управляющих приложений могут потребоваться дополнительные опции (объекты или атрибуты). Именно в этом случае создаются специализированные агенты со своей собственной MIB.
2.2. Организация Менеджера TCC
Таким образом, используя принцип Менеджер/агенты TransView Control Centre соединяет преимущества, с одной стороны, схемы централизованного администрирования систем и, с другой стороны, распределенных приложений. Однако для сетей большого масштаба, особенно при переходе от локальных конфигураций к глобальным, управление из одного единственного пункта не будет эффективно. Наряду с распределением контроля требуется и распределение управления.
С этой целью в TCC введен принцип административных доменов, и именно на нем держится модульная структура системы управления и возможность масштабирования. Домены - это способ дробления сети на несколько более мелких центров, каждый из которых может обслуживаться в известной степени независимо. Разбиение на домены может отражать естественную структуру сети, производственную ситуацию или организационные требования. К примеру, каскадирование сети в виде доменов, причем с возможностью оперативного переконфигурирования, может стать эффективным способом поддержки "виртуальных команд" - географически распределенных временных коллективов, создаваемых для решения производственных задач. В этом случае появляется аппарат для гибкого моделирования, зависящего от задачи распределения административной ответственности в соответствии с требованиями заказчика и организационной структурой. Меняя домены, можно по-разному использовать имеющуюся информационную инфраструктуру.
Обслуживание доменов поддерживается клиент/серверной архитектурой Менеджера TCC. Серверная часть устанавливается на центральном узле ТСС, а графический интерфейс пользователя TCC (клиентская часть) может выдаваться как туда же, так и на другие узлы сети - пункты управления доменами. Взаимодействие серверных и клиентских компонентов происходит по протоколу RPC таким образом, что если с TCC одновременно работают несколько пользователей в разных пунктах, они получают синхронизированную информацию.
Графический интерфейс Менеджера TCC состоит из трех блоков:
- управления доменами (конфигурирование и закрепление за ними пользователей);
- управления приложениями (средства для регистрации в доменах систем и приложений, а также спецификации событий и атомарных действий);
- третий блок - окно событий (мониторинг выполняющихся приложений) в этом окне отображаются получаемые от приложений сообщения. Состав выводимых сообщений может быть ограничен с помощью фильтров, задающих область наблюдения и типы сообщений.
Уровень гибкости управления, который обеспечивает метод доменной организации, составляет, пожалуй, главное отличие TransView Control Center от многих сопоставимых с ним решений.
2.3. Интеграция приложений в TCC
В качестве приложения вместе с TransView Control Centre можно интегрировать исполняемые конструкции различных типов: простые команды оболочки ОС, отдельные программы пользователя или большой программный пакет. Включенное в TCC приложение может выполняться как на центральной, так и на удаленной системе (под центральной подразумевается система, на которой установлен Менеджер TCC), но в любом случае интегрированное приложение можно запустить из единого центра через графический интерфейс TCC.
Чтобы иметь возможность стартовать приложение, достаточно определить для него имя, пиктограмму и команду для запуска соответствующей программы, - все это вводится через графический интерфейс Менеджера TCC.
Если же приложение способно генерировать сообщения, необходимо выполнить дополнительные шаги конфигурирования. Во-первых, приложение должно быть известно не только Менеджеру, но и агенту TCC на той системе, где оно будет выполняться - ему сообщается имя приложения и Log-файл, в который оно будет писать свои сообщения.
После этого можно приступать к конфигурированию событий. Событием в TCC считается поступление какого-либо сообщения от агента, работающего на удаленном узле, поэтому различаются события непосредственно по тексту сообщения. В определении события указывается: приложение, подлежащее мониторингу, система, на которой это приложение выполняется, и реакция, если она нужна. Реакция представляет собой некоторое действие и временной фильтр. Под действием, как и при запуске приложений, здесь понимается операция запуска программы или команды на удаленной системе. С помощью временного фильтра можно задать условия, должна ли выполняться реакция при совершении события. Тем самым в разные периоды времени управление может меняться.
3. Управление событиями - Transview Event Center
Принцип каскадного управления информационной инфраструктурой на основе доменов, реализованный в TransView Control Center, получил дальнейшее развитие в другом продукте - Transview Event Center (TEC). Задача Event Center, как и TCC, - мониторинг распределенных по различным узлам сети агентов, но архитектурный принцип менеджер/агент расширен в TEC моделью менеджер/субменеджер. Здесь главный менеджер не обязательно связан с агентами - он управляет некоторым множеством своих подчиненных. Контролируют агентов субменеджеры, сообщая посредством трапов (SNMP trap) наверх по иерархии только о наиболее важных событиях. Такой аппарат особенно эффективен в первую очередь для масштабных инсталляций системы управления, например в среде WAN: каскадирование уменьшает нагрузку на центральный пункт управления и разгружает сеть.
В отличие от TCC, Transview Event Center не является функционально законченным продуктом. Его роль ограничивается автоматической обработкой событий, и чтобы получить полную систему управления, он должен быть интегрирован с каким-нибудь Менеджером Управления. Поскольку весь обмен сообщениями в TEC происходит по протоколу SNMP, в качестве Менеджера Управления могут выступать самые разные продукты: TCC, Transview SNMP, Network Node Manager и др.
Event Center составляют два взаимодополняющих продукта: Event Configurator и Event Correlator. В соответствии с названием, Event Configurator предоставляет пользователю графический интерфейс, через который вводятся все необходимые настройки и определения. Конфигуратор существует в сети в единственном экземпляре - он устанавливается на сервер Менеджера Управления и запускается, например, в TCC, как обычное приложение.
Второй продукт - Event Correlator, напротив, может инсталлироваться на несколько систем в сети. Как раз Корреляторы и выступают в роли субменеджеров, выполняющих локальную обработку сообщений от агентов. Хотя Корреляторы и распределены по сети, все они централизованно администрируются через Event Configurator.
Обмен информацией в распределенной системе организован следующим образом. Связь между Конфигуратором и Корреляторами осуществляется через механизм сокетов и используется главным образом для выгрузки в Корреляторы конфигурационных файлов. Опрос Корреляторами агентов и посылка трапов в Менеджер происходит по протоколу SNMP. Поскольку большая часть обработки выполняется Корреляторами самостоятельно, им не требуется постоянное соединение с Менеджером - тем самым нагрузка на сеть значительно уменьшается.
Обычно при мониторинге агентов Информационная База Управления (MIB) располагается на системе Менеджера. Для модели менеджер/субменеджер с целью экономии памяти в TransView предложен несколько иной подход. В Event Center в роли менеджеров для агентов выступают Корреляторы, однако MIB не реплицируется на каждую систему, где они функционируют. По-прежнему ведется центральная MIB, в которую через интерфейс Конфигуратора заносятся идентификаторы объектов и правила мониторинга. При определении правил Конфигуратор осуществляет доступ к MIB центрального Менеджера, с которым он работает. Стыковка Коррелятора с MIB происходит в момент его запуска - он выбирает те правила и задания мониторинга, которые относятся к нему, и производит однозначную идентификацию всех объектов. Тем самым отпадает необходимость в перманентном доступе к центральной MIB.
Функциональность Event Center формируется в процессе конфигурирования. Единица работы по управлению - это "правило" на языке Пролог, которое определяется в окне Event Configurator. Языка Пролог бояться не нужно - в комплект поставки TransView входит большой набор готовых правил, которыми сразу можно воспользоваться. Правила определяют, какие из объектов MIB должны мониториться агентами. Простейшие правила специфицируют те объекты, которые требуется опрашивать, более сложные могут включать команды или процедуры Пролога по дальнейшей обработке данных.
Вначале все правила, построенные в конфигураторе, запоминаются в его внутренних файлах. Затем они передаются конкретному Коррелятору как задание мониторинга. Для этого имя Коррелятора связывается с правилом и именем целевой системы.
Файлы с правилами передаются через аппарат сокетов на систему Коррелятора, а затем происходит его автоматический рестарт, в ходе которого интерпретатор Пролога считывает текущие данные и начинает их обработку. В зависимости от задания Коррелятор приступает к мониторингу агентов и начинает принимать результаты опроса, которые либо тут же обрабатываются, либо записываются в Log-файлы. Log-файлы - это собственность Коррелятора, они хранятся на его системе и передаются в Конфигуратор по специальному запросу, где их можно представить, например, графически.
Коррелятор может производить мониторинг либо отдельных агентов, либо их групп. В первом случае одно или несколько правил передаются нужной системе в виде задания. Когда несколько агентов рассматриваются как группа, они мониторятся одним заданием. Каждый опрос, инициируемый Коррелятором, производится синхронно на всех системах в группе. Групповой мониторинг имеет важную особенность: данные, собранные от всех агентов, могут дополнительно оцениваться в специальных групповых правилах, что позволяет получить более полную картину работы.
Event Correlator обладает способностью генерировать трапы. Он посылает их когда происходят предопределенные события: соответствующие спецификации должны быть сделаны через предикаты Пролога в правилах. Кроме того, Корреляторы сами могут получать трапы и обрабатывать их несколькими способами. Одна из возможностей - определение фильтров. В фильтре трап прежде всего однозначно идентифицируется, затем данные трапа могут быть сохранены в памяти и впоследствии обработаны. К примеру, с помощью фильтра можно задать переадресацию трапа в Менеджер без какой-либо обработки.
4. Мониторинг сети - TransView SNMP Manager
TransView SNMP Manager функционально покрывает классическую область применения платформ управления - собственно сети и их компоненты. Сегодня, однако, подобное средство - это только одна из частей TransView. С другой стороны, концепция управления распределенными приложениями, реализованная в TransView Control Center, использует те же механизмы SNMP, которые были разработаны для управления сетями, а это позволяет легко интегрировать SNMP Manager с TCC, а также использовать его в качестве Менеджера Управления для Event Center.
Как и другие, основанные на SNMP управляющие продукты, SNMP Manager собирает информацию от распределенных в сети агентов, производящих мониторинг сетевого оборудования: линий связи, мостов, маршрутизаторов, хабов и шлюзов. Все данные оцениваются и представляются через графический интерфейс - Сетевой Монитор. Организация интерфейса имеет две цели: во-первых, администратор в любой момент может оценить состояние всей сети; во-вторых, оперативно регистрируя сбой на общей картине, он может запросить дополнительные данные, выделив фрагмент сети и ввести новые управляющие настройки для коррекции неисправностей. Интерфейс Сетевого Монитора может быть разбит на любое количество иерархических уровней от глобального обзора до индивидуальных систем. Для повышения наглядности на картину сетевой топологии можно наложить стандартные типовые или реальные изображения, например план здания. Такие карты строятся в SNMP Manager автоматически - эта функция называется DISCOVERY. Она самостоятельно регистрирует все устройства в сети TCP/IP и формирует окно Сетевого Монитора с пиктограммами устройств, соединенных линиями связи.
О нарушении работоспособности или совершении предопределенного события, например выхода некоторой величины за порог, немедленно сообщается сетевому оператору. Кроме специального окна, содержащего текстовые сообщения, SNMP Manager показывает алармы непосредственно на карте Сетевого Монитора, изменяя цвет пиктограмм или линий связи. Раскраска делается вовсе не случайно - различные цвета соответствуют разным весам алармов, причем эти веса вычисляются на основе контекстно-зависимой модели зависимости сбоев. Таким образом, даже не прибегая к сообщениям, прямо на карте сети администратор может не только осмотреть все "горячие точки", но и оценить реальный статус происходящего. Кроме визуализации, изменение состояния может инициировать различные действия, например, звуковой сигнал или старт специального приложения.
Функции управления производительностью SNMP Manager собирают все данные, необходимые для индивидуализированного учета, что особенно важно для распределенной системы коллективного пользования. Данные о нагрузке и производительности систем, а также сетевых компонентов периодически, через индивидуально конфигурируемые интервалы регистрируются и передаются в БД для последующего анализа.
5. Управление ПО - TransView SAX
Управление программным обеспечением: администрирование, распространение и инсталляция - это, пожалуй, основная причина головной боли ИТ менеджеров корпораций. Неудивительно поэтому, что продукт TransView SAX, позволяющий управлять ПО, не посещая рабочих мест, весьма популярнен среди заказчиков TransView.
Область действия SAX - администрирование и доставка ПО в гетерогенных сетях, включающих как ОС UNIX, так и Windows. В принципе, особенно в наших условиях, для этих задач можно рассчитывать на более простые решения - передачу файлов и скрипты. Однако известны примеры корпоративных сетей, в которых весь сетевой трафик постоянно занят перекачкой новых версий ПО, а на остальное пропускной способности уже не хватает. Разработчик TransView действует в этих условиях аккуратнее и хитрее, используя, как и в других продуктах, все тот же иерархический принцип.
В сети, работающей под TransView SAX, целевые системы (клиенты под UNIX и Windows) соединены с центральным депо ПО через несколько субдепо. Новые версии ПО и данные, необходимые для операций на целевых системах (например, новый список цен), накапливаются в депо и инсталлируются на целевые системы по расписанию без вмешательства оператора. Происходит это, однако, не напрямую, а в несколько этапов, через субдепо, которые служат промежуточными пунктами хранения и распределения. Такая организация доставки позволяет существенно уменьшить затраты на передачу данных в сетевой среде.
Субдепо, наравне с центральным депо (если оно есть), являются полноценными точками распространения ПО: имеют собственную постоянную память для продуктов и полностью интегрированы в аппарат администрирования Системы Управления. Субдепо имеют следующие особенности:
- при необходимости можно задать временной интервал между загрузкой субдепо и инсталлированием на целевую систему. Например, имеет смысл производить загрузку в периоды низкой загрузки сети;
- в субдепо может одновременно храниться несколько версий одного продукта. Соответственно, обновление версий для каждой целевой системы не требует их загрузки из Системы Управления в субдепо.
Поскольку операции распределены по сети и по времени, очень важно, что в любой момент сетевой администратор получает точную информацию о составе распространяемого ПО, состоянии субдепо и целевых систем. Обеспечиваемая в TransView целевая система автоматически регистрируется в субдепо, а информация о ней направляется в базу данных Системы Управления (функция Autodiscovery).
Все средства представления и управления SAX такие же, как для целевых систем UNIX, так и для ПК с NT, Windows 95 или Windows 3.1x. Кроме того, функция субдепо реализована не только для UNIX-серверов, но и для серверов NT. Что касается мира UNIX, то здесь TransView SAX реализован на большом количестве платформ: Reliant UNIX, Sinix, UnixWare, HP-UX, NCR UNIX, Sun Solaris и AIX.
Существуют различные варианты SAX. Рассматривая для определенности версию для Windows - TransView SAX-PC, можно выделить в ней три основные части:
- Система Управления (Менеджер) обеспечивает управление продуктами, клиентами и группами клиентов. Набор ее функций достаточно широк: от доставки продуктов клиентам до инвентаризации;
- Система Администрирования, с помощью которой доставляемые продукты (ПО или данные) упаковываются и конфигурируются, а затем передаются для хранения в депо Менеджера;
- Машина Доставки инсталлирует и деинсталлирует продукты на целевых системах в полностью автоматическом режиме.
Сейчас TransView SAX-PC позиционируется как средство управления клиентами, входящими в состав рабочей группы. Однако она еще может быть интегрирована в реализацию SAX масштаба предприятия. В этом случае SAX-PC выступает в роли субдепо, и ее Система Управления берет на себя функции локального администрирования от центрального Менеджера предприятия.
6. Управление печатью - TransView Enterprise Printing
TransView Enterprise Printing управляет массовой печатью, выполняемой как на централизованной принтерной системе, так и в сетевой среде клиент/сервер. Достоинства первого варианта проявляются там, где требуется сочетание высокого качества и большого объема печати. Параллельно с таким подходом большинство компаний имеют сетевую инфраструктуру, соединяющую рабочие места с достаточно качественными принтерами, на которых производится вывод индивидуальных документов, отчетов, графиков и т.д. TransView Enterprise Printing поддерживает обе эти формы организации и применяется для управления принтерными ресурсами в гетерогенной среде клиент/сервер.
Как и при локальном выводе, во время работы с TransView Enterprise Printing пользовательские задания печати отправляются в спул, который имеет распределенную структуру и разбит на домены. Диспетчеризация спула осуществляется Супервизором, который на основе параллельного мониторинга принтеров домена выбирает задания из очереди и перенаправляет их на свободные принтеры.
TransView Enterprise Printing обеспечивает широкий набор функций для запуска заданий печати и контроля за ними, например, очереди управляются по времени и по приоритету. В сетевом варианте могут использоваться модели принтеров, различающиеся по типу, техническим характеристикам, способам подключения (например, для обслуживания спула можно задействовать даже принтеры, подсоединенные к ПК). При такой неоднородности ресурсов большое значение приобретает аппарат TransView Enterprise Printing для модификации и преобразования печатаемых данных посредством фильтрующих программ, таблиц преобразований, манипулирования шрифтами и форматами.
7. Управление SAP R/3 - TransView Live Network Integrator
Если в сети работает несколько систем управления предприятием SAP R/3, для них можно создать общую точку мониторинга, и сделать это поможет TransView Live Network Integrator (LNI). LNI дает системному администратору четкое представление о базе данных R/3 (распределении по хостам, процессах, отношениях) и о связанных с ними реализациях R/3. Получив уведомление о проблемах функционирования, он может тут же определить, какой из экземпляров R/3 дал сбой.
LNI через протокол SNMP собирает информацию с индивидуальных систем R/3 и производит ее графическую обработку. Данные динамически агрегируются и изображаются во временной развертке - к оператору они поступают уже полностью подготовленными для анализа.
Кроме того, LNI обеспечивает администратору прямой доступ к системам R/3 со своей собственной сетевой платформы управления. Это позволяет задействовать входящую в состав R/3 программу мониторинга - CCMS прямо в среде сетевого управления.
LNI можно использовать либо независимо, либо интегрировав ее в TransView SNMP или TransView Control Center. Интеграция приводит к тому, что алармы SAP R/3 становятся видимыми на карте сети. В то же время средства управления алармами TransView позволяют реализовать автоматическое реагирование на особые ситуации.
Заключение
По-видимому, трудно оценить TransView, не представляя себе масштаб проектов, в которых он применяется. Поэтому приведем несколько примеров.
Общество Содействия Науке Макса Планка (Max Planck Gesellschaft), самая крупная в Германии исследовательская организация и одно из самых известных в мире обществ содействия искусству и естественным наукам, было создано в 1911 г. Оно поддерживает 70 институтов в 60 городах с числом сотрудников около 12 тыс. человек. Институты, входящие в общество Макса Планка (MPG), разбросаны по всей Германии. Чтобы справиться с децентрализацией, мощные сетевые коммуникации связывают 75 систем UNIX (30 RM400, 45 RM200 и RM300) и около 1000 ПК с Windows 3.11 и NT. Управление сетью, системами и приложениями осуществляется с помощью TransView Control Center, SNMP, SAX и SAX-PC.
Среди заказчиков TransView - крупнейшие операторы телекоммуникаций (Belgacom SA), оптовые поставщики (Carson Pirie Scott & Co), банки (BW Bank, APO Bank, SHB). Очень крупную сеть имеет почтовая служба Deutsche Post AG - около 1.700 серверов (Sinix, NCR-Unix и NT) и 15 тыс. клиентских машин, обслуживающих 10 млн. потребителей разнообразных услуг связи. Для распространения ПО используются TransView SAX и SAX-PC. Еще один пример - управление информационной инфраструктурой муниципального хозяйства одного из мегаполисов Германии - Кельна. Сегодня 50 административных зданий и вспомогательных подразделений города объединены в общую сеть, состоящую из 120 UNIX серверов от HP, SNI и Olivetti, трех мэйнфреймов SNI, 2800 ПК Windows. В общей сложности муниципалитет Кельна имеет почти 8 тыс. автоматизированных рабочих мест. Диагностика, актуализация программного обеспечения, управление и поддержка функций безопасности осуществляются средствами системы TransView.
Российские пользователи распределенных гетерогенных систем тоже давно работают с системой TransView - в качестве одного из наиболее ярких примеров можно привести МВД России.
Литература
- Н.Дубова. Интегрированные системы управления распределенной корпорацией, Открытые Системы, N1, 1998, с. 69-75
- С.Штайнке. Состояние платформ, LAN Magazine, т. 4, N3, Март 1998, с. 97-103
- Н.Дубова, Е.Кутукова. Unicenter TNG - управление распределенной корпорацией. Открытые системы, #2, 1998, с. 54-59
