В одном из номеров журнала была помещена статья [1] о системе Convex Exemplar SPP1200 - сейчас, примерно через полтора года, имеет смысл снова возвратиться к этой архитектуре и посмотреть, какие изменения произошли с данной моделью суперкомпьютера, теперь уже производства HP/Convex. Альянс двух компаний позволил расширить диапазон предлагаемых вычислительных серверов и сегодня в семействе Exemplar анонсированы два типа моделей, принадлежащих классу суперкомпьютеров: "S class" - 4-16 ЦПУ, 256 Мбайт - 16 Гбайт памяти и "X-class" - 4-64 ЦПУ, 1 Гбайт - 64 Гбайт памяти.
Разработчики системы Exemplar, как и разработчики других современных систем с суперкомпьютерной архитектурой, пытаются в конструкциях новых систем найти компромиссное решение двух задач:
Отсюда понятно, какую большую роль играет в высокопроизводительных архитектурах обеспечение гладкой масштабируемости всех ресурсов системы: вычислительной производительности, объема памяти, подсистемы ввода/вывода, сетевых интерфейсов и операционной среды. Однако одной масштабируемости еще мало: простота использования, мобильность приложений во многом определяется однородностью всех ресурсов уже на базовом уровне.
Главный подход, которому следовали до сих пор практически все поставщики высокопроизводительных систем, состоит в том, что за основу берется архитектура SMP, обеспечивающая однородность ресурсов, а поддержка масштабируемости реализуется средствами аппаратуры коммутации компонентов системы, построенной по модульному принципу. До недавнего прошлого аппаратура внутрисистемной передачи данных строилась по двум принципам. В "чистых" SMP-системах использовалась системная шина, к которой подвешивались все части системы, а в суперкомпьютерах они соединялись напрямую, например кабелем CrayLink. И тот, и другой подход имеют существенные недостатки. Пропускная способность системной шины устанавливает верхний предел производительности всего комплекса и, следовательно, предел масштабируемости. Несмотря на то, что появились очень мощные шины - SGI PowerPath2 (1.2 Гбайт/с), Sun Gigaplane (2.6 Гбайт/сек), предел все равно существует. Прямые же точечные соединения хороши в суперкомпьютерах, но они дороги и их число при увеличении числа компонентов возрастает комбинаторно.
Компания Convex была первой из производителей, кто пошел по среднему пути, использовав весьма популярную сегодня двухуровневую организацию памяти NUMA с поддержкой когерентности данных на разных уровнях еще в самом первом поколении семейства Exemplar - SPP1000 (1994 год). Для обеспечения однородного доступа к ресурсам был применен матричный коммутатор - кроссбар (на первом уровне) и сеть обмена CTI - на втором. Сейчас такое решение стало почти общим местом для систем класса суперкомпьютерных серверов: Sequent NUMA-Q, SGI Origin и Onyx2.
Платформы Exemplar S/X представляют собой уже уже четвертое и пятое поколение масштабируемых систем Exemplar, предыдущие реализации которых - SPP1000, SPP1200, SPP1600 (рисунок 1) были пионерскими в области высокомасштабируемых комплексов с однородной разделяемой памятью. Следует отметить, что архитектура, заложенная в первых поколениях SPP1X00, оказалась достаточно удачной для адаптирования все более производительных процессоров. Фактически, появление каждого нового поколения SPP базировалось на очередном процессоре PA-RISC: PA-7100, PA-7200, PA-8000 (рисунок 2). Как и прежде, системы Exemplar S/X сохраняют полную бинарную совместимость с предшествующими поколениями.
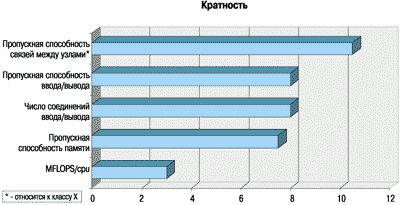
Рисунок 1.
Сравнение характеристик SPP2000 с предыдущими поколениями Exemplar.
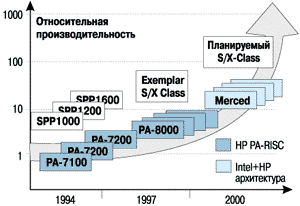
Рисунок 2.
1. Архитектура системы Exemplar
Система Exemplar SPP2000 сохранила основные черты архитектуры SPP1X000 и по-прежнему в ней можно выделить три уровня: процессор - гиперузел - кластер гиперузлов. Масштабируемость SPP2000 обеспечивается на уровне гиперузлов и поддерживается двумя аппаратными средствами: матричным коммутатором и сетью обмена.
Платформы Exemplar S/X остаются системами параллельного мультипроцессирования с высокой степенью масштабируемости, но сохраняют простую, как и в персональных вычислителях, модель программирования, характерную для архитектуры SMP. Систему в целом можно рассматривать как комплекс из определенного числа MIMD-процессоров - от 4 до 64, разделяющих большую однородную физическую память и высокоскоростные порты ввода/вывода.
Поскольку физически память распределена по различным частям системы, такая простая модель поддерживается программно и аппаратно подсистемой управления общей глобальной памятью, которая в терминологии Convex получила название GSM - это реализация общего подхода к архитектуре двухуровневой памяти CC-NUMA. Обеспечивая виртуальную однородность памяти, GSM автоматически распределяет данные и поддерживает их согласованность, избавляя программиста от необходимости вручную управлять процессами пересылки данных и их обновления в различных частях системы.
1.1 Системы класса S
Системы Exemplar SPP-2000S представляют собой суперсерверы среднего класса, в которых связь между различными модульными компонентами реализована посредством кроссбара. Следующий уровень масштабируемости - это серверы класса X, в которых несколько серверов SPP-2000S объединяются в единую систему с помощью сети обмена. По сути дела, SPP-2000S можно рассматривать, как непосредственный преемник гиперузла в SPP-1200/1600, в котором, однако удвоено число процессоров и увеличен объем памяти.
Система класса S обладает следующими характеристиками:
На рисунке 3 приведены основные компоненты архитектуры системы S класса.
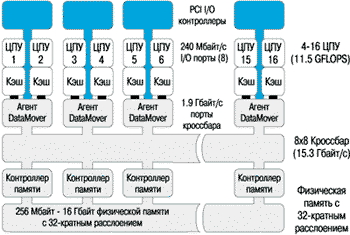
Рисунок 3.
Архитектура системы класса S.
Кроссбар. Как уже было сказано, архитектура семейства Exemplar во многом определяется наличием кроссбара, большая пропускная способность которого (15.3 Гбайт/с), возросшая в 6 раз по сравнению с предшествующими системами SPP, обеспечивает очень высокую производительность для большинства приложений. Конструкция кроссбара позволяет осуществлять доступ из множества процессоров и каналов ввода/вывода к подсистеме памяти без взаимных блокировок, даже когда все эти устройства работают параллельно. Использование кроссбара позволяет избежать падения производительности с ростом числа компонентов, характерного для архитектуры систем с общей шиной.
Системы класса S в максимальной конфигурации могут содержать 16 процессоров, 8 плат памяти, 8 каналов ввода/вывода и 24 PCI контроллера ввода/вывода. Объединяющий их кроссбар представляет собой матричный коммутатор, который имеет по 8 портов со стороны процессорной подсистемы и со стороны подсистемы памяти. В предыдущих системах кроссбар имел размерность 5х5. Со стороны обрабатывающей подсистемы каждый из 8 портов кроссбара подсоединяется к процессорам через плату, называемую агентом. Агент обслуживает пару процессоров PA-8000, канал ввода/вывода производительностью 240 Мбайт/с и блок DataMover. Со стороны подсистемы памяти порты кроссбара подключены к платам памяти, имеющим 4-х кратное расслоение.
Кроссбар работает на частоте 120 МГц (8.33 нс). Ширина тракта между агентом и чипами контроллеров памяти составляет 64 разряда. Поэтому номинальная пропускная способность порта кроссбара составляет 960 Мбайт/с в каждом направлении. Кроссбар является неблокирующимся, так что все работающие порты могут использовать полную полосу пропускания при условии, если все целевые порты, к которым производится обращение, разные. Следует заметить, что на самом деле реально имеются 2 кроссбара - входной и выходной, и для каждой комбинации из 8 агентов и 8 контроллеров памяти существуют два пути в кроссбаре. Поэтому суммарная пиковая полоса пропускания кроссбара составляет
960 Мбайт/с * 8 * 2 = 15.36 Гбайт/с.
Подсистема памяти. Системы класса S могут иметь от 256 Мбайт до 16 Гбайт памяти SDRAM - Synchronous Dynamic Random Access Memory, физически распределенной по 2-8 платам. Благодаря использованию SDRAM подсистема памяти работает на более высокой тактовой частоте, чем было бы возможно с памятью типа DRAM, и имеет более высокую эффективную пропускную полосу. SDRAM все более широко применяется в системах разного уровня, включая ПК: это более производительная и имеющая меньшую цену память.
Чтобы объяснить преимущества SDRAM, рассмотрим вначале схематическое представление стандартной DRAM. DRAM имеет два компонента: собственно память и контакты. Адрес подается в DRAM на входных контактах, осуществляется доступ к памяти DRAM для выборки данных, которые затем выдаются на выходные контакты. Сразу после того, как доступ к данным завершен, происходит восстановление памяти, которое должно завершиться прежде, чем память может использоваться повторно. Во время восстановления DRAM не может отвечать на новые запросы, поступающие на контакты.
Модель SDRAM включает в эту схему дополнительный компонент: связь между контактами и ядром осуществляется через регистры. Теперь, когда адрес подается в SDRAM и по нему осуществляется доступ к памяти, из нее выбирается больше информации, чем подается на выходные контакты. Эти избыточные данные сохраняются на регистрах. После того, как выборка из памяти произведена, начинается ее восстановление, как и в стандартной DRAM. Однако во время восстановления сохраненные на регистрах дополнительные данные остаются доступными и могут быть выбраны. Таким образом, этот способ позволяет уменьшить потери времени при доступе в SDRAM за счет выборки дополнительных данных.
В Exemplar S память организована в единый массив - в этом отличие архитектуры Convex, например, от архитектуры S2MP SGI/Cray, в которой у каждого процессора имеется собственная локальная память. Возможность масштабирования в системах SPP2000-S обеспечивается тем, что память составляется из модулей, которые реализованы по технологии DIMM - Double In-line Memory Module. Эти модули, ориентированные на 64-разрядные процессоры, имеют большее число контактов (168) по сравнению со стандартными для ПК модулями типа SIMM, и существенно более высокую производительность. Память собирается из базовых 128- Мбайтных модулей DIMM (16 Мбит), которые равно распределены между контроллерами памяти. На каждой плате памяти может быть установлено до 4 модулей DIMM, и на каждый контроллер приходится 128, 256, 384 или 512 Мбайт памяти.
Степень расслоения памяти определяется количеством плат памяти, а не числом модулей DIMM. Каждый контроллер памяти дает 4-кратное расслоение, так что в полной конфигурации с 8 контроллерами получается 32-кратное расслоение, которое не зависит от реального объема имеющейся памяти.
Подсистема обработки. В верхней части рисунка 3 размещаются 8 блоков подсистемы обработки Exemplar S, которые называются блоками ресурсов обработки - PRB. Отдельный PRB показан на рисунке 4. Он состоит из двух процессоров HP PA-8000, канала ввода/вывода и модуля управления данными DataMover, являющегося блоком аппаратных средств GSM.
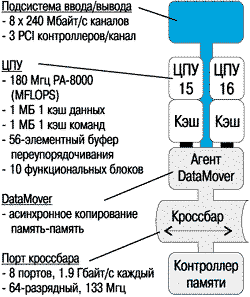
Рисунок 4.
Блок подсистемы обработки PRB.
Появление нового поколения системы Exemplar - SPP2000 во многом связано с процессором HP PA-8000, на котором базируются все модели. В свое время мы уделили достаточное внимание этому одному из самых быстрых процессоров [2], а здесь же приведем только некоторые краткие сведения.
64-разрядный процессор HP PA-8000 имеет быстродействие 720 MFLOPS на тактовой частоте 180 МГц. Этот процессор производит 4-кратное суперскалярное распараллеливание, выполняя 4 операции с плавающей точкой за один такт, и имеет следующие архитектурные свойства:
PA-8000 - это первый чип, в котором реализован набор команд PA-RISC 2.0. Однако он сохраняет полную бинарную совместимость с предыдущими процессорами: PA-7100 и PA-7200. Основная задача архитектуры 2.0 - поддержка 64- разрядных целых чисел и 64-разрядной адресации.
С точки зрения межпроцессорного обмена данными важно, что PA-8000 имеет слабосвязанную архитектуру. В частности это означает, что он способен обслуживать запросы от сети обмена параллельно с запросами на доступ к своим данным, хранящимся в локальном кэше.
DataMover. Система управления глобальной разделяемой памятью GSM, использующаяся для перемещения данных между различными видами памяти, включает программные и аппаратные средства и имеет модульную структуру. Блок специализированной аппаратуры называется DataMover и включается в каждый PRB. DataMover занимается копированием данных со скоростью 450 Мбайт/с. Поддержка аппаратуры DataMover включена в операционную систему и компиляторы, в библиотеки PVM и MPI. Поэтому пользователи сразу почувствуют новые аппаратные возможности SPP2000 при работе своих приложений даже без изменения исходных текстов и перекомпиляции.
1.2 Системы класса X
Системы класса X - это следующий уровень интеграции вычислительных ресурсов и соответственно новый, более высокий уровень суперкомпьютерной производительности. SPP2000-X может включать до 64 процессоров PA-8000 с суммарной пиковой производительностью 46 GFLOPS.
В системах X-класса происходит объединение нескольких симметричных мультипроцессорных единиц, называемых гиперузлами. Каждый гиперузел является фактически системой класса S. Поскольку система строится из нескольких узлов, располагающих собственной памятью, появляется второй уровень. В SPP2000-X двухуровневая иерархия памяти поддерживается архитектурой СС-NUMA, в которой каждый уровень оптимизирован для параллельного доступа к разделяемым данным. Блоки памяти первого уровня соединяются между собой высокопроизводительной сетью обмена CTI. И в двухуровневой системе класса X, также как и в S-системах, сохраняется модель однородной разделяемой памяти и обеспечивается согласованность данных в кэшах процессоров.
Архитектура системы Exemplar теоретически масштабируется до 512 процессоров и до 512 Гбайт оперативной памяти.
Сеть обмена. Сеть обмена CTI - Coherent Toroidal Interconnect, построенная в соответствие со стандартом IEEE 1596-1992 SCI, была и в предыдущих поколениях SPP1X00. Теперь она получила развитие и выросла во втором измерении. CTI теперь состоит из совокупности колец, плоскости которых ориентированы в двух ортогональных направлениях (X и Y) (рисунок 5). Такое наращивание сети обмена - прежде был один набор колец, расположенных параллельно, - увеличило ее пропускную способность и повысило устойчивость к сбоям.
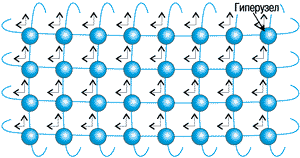
Рисунок 5.
Сеть обмена CTI.
Сеть обмена реализована в виде множества однонаправленных связей между гиперузлами типа точка - точка. Если рассмотреть одно кольцо, скажем в направлении X, то в нем есть выделенное направление, в котором передаются данные. Физически кольцо составлено из 8 независимых участков передачи данных, которые исходят от каждого из 8 контроллеров интерфейса в гиперузлах. Связь между некоторой парой гиперузлов полностью независима от всех остальных связей, что дает расслоение доступа вдоль кольца. Для увеличения производительности важно, что в контроллерах CTI могут храниться несколько ожидающих обработки запросов.
В согласии со стандартом SCI, сеть обмена использует протокол расщепления транзакций. Рассмотрим пример, в котором некоторый гиперузел запрашивает данные из удаленного гиперузла - целевого. Сеть обмена начинает использоваться сначала для посылки самого запроса, оформленного в пакет. Для простоты будем предполагать, что оба гиперузла находятся на одном кольце. Пакет запроса проходит по кольцу мимо тех гиперузлов, которые не являются пунктом назначения, пока его не увидит и не заберет себе целевой гиперузел. Подсистема памяти в целевом гиперузле затем предпринимает действия, необходимые для извлечения своих локальных данных. Параллельно с этим подсистема локальной памяти посылает запрашивающему гиперузлу уведомляющий пакет. Когда целевой гиперузел извлек требуемые данные, он формирует из них ответный пакет и подает его в сеть обмена для посылки в запрашивающий узел. Финальная часть этой транзакции состоит в посылке подтверждающего пакета из запрашивающего узла в посылающий. Расщепление, реализованное в этом механизме, состоит в том, что пакет запроса отделен от пакета ответа.
Благодаря расщеплению в протоколе транзакций и параллельности подтверждающих пакетов, которые не вносят никаких задержек, близость узлов не имеет никакого значения. Если запрашивающий узел и целевой узел физически близки в прямом направлении передачи, то пакет запроса проходит короткий путь, а пакет ответа - длинный, и наоборот. Поэтому общая длина пакетов всегда составляет полный цикл кольца.
Следует отметить, что CTI обеспечивает реальную аппаратную поддержку доступа к общей глобальной память, в то время как системы без этой функции лишь программно эмулируют перемещение страниц из одного гиперузла в другой.
Для минимизации издержек доступа к глобальной памяти каждый гиперузел содержит кэш ссылок на страницы памяти, полученные по сети обмена от других гиперузлов. Система гарантирует идентичность кэшей в различных гиперузлах - если два или несколько гиперузлов обращаются по одному адресу памяти, они получат одинаковые данные.
2. Оценки производительности
Теория - теорией, но сейчас потенциальные пользователи ждут убедительных практических результатов, подтверждающих преимущество систем с иерархической организацией памяти NUMA над системами с общей шиной. Сегодня имеются данные по Exemplar S в конфигурации с 16 процессорами. Ожидается, что появление в середине 1977 года платформы Exemplar X архитектуры NUMA с 64 процессорами радикально повысит показатели производительности. Однако компания Convex, имеющая большой опыт разработки и эксплуатации систем с глобальной разделяемой памятью, пришла к выводу, что для эффективной работы архитектуры NUMA требуются определенные усилия по ее настройке и оптимизации. Компьютер Exemplar S/16 рассматривается как промежуточный этап, хотя и даются гарантии масштабируемости и полной совместимости этих платформ.
В приводимых данных следует обратить внимание не на абсолютные показатели - они существенно возрастут при переходе к Exemplar X, а на то, происходит ли существенное падение производительности при увеличении числа процессоров. Поскольку здесь рассматривается Exemplar S, по сути дела сравниваются возможности архитектуры с кроссбаром Convex и SMP архитектур с системной шиной. Использованные тесты описаны в статье [3].
В таблице 1 проводится сравнение пропускной способности памяти по тесту STREAM. Как и следовало ожидать, Cray J90, наследующий суперкомпьютерную технологию коммутации Cray, демонстрирует результаты, на порядок превосходящие остальные. Результаты Exemplar S значительно лучше характеристик RISC систем с системной шиной.
Таблица 1.
Тест пропускной способности памяти STREAM.
|
e = оценка |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В тесте STREAM для измерения пропускной полосы памяти используется довольно простая модельная программа, но и другие тесты демонстрируют преимущества кроссбара Exemplar S. Тест SPECrate_fp95 не помещается целиком в кэш и дает среднюю нагрузку на иерархию памяти. График на рисунке 6 показывает, что у сервера HP класса K с разделяемой шиной происходит сильное падение производительности при увеличении числа процессоров, в то время как Exemplar S c кроссбаром имеет более плоский график. Отметим, что хотя и K460, и Exemlar S используют одинаковый процессор, показатели SPECrate для них отличаются существенно. Это отражает то обстоятельство, что система класса K оптимизирована для менее производительных систем, а не для high end.
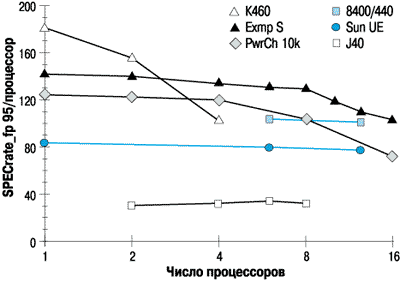
Рисунок 6.
SPECrate_fp95 в пересчете на один процессор.
Дополнительные электронные компоненты системы Exemplar (агент, кроссбар, TCI) уменьшают его производительность в однопроцессорном варианте, но четко проявляют преимущества в больших конфигурациях. SGI Power Challenge показывает среднее падение производительности при увеличении числа процессоров, конкуренция за шину проявляется в диапазоне 8- 16 процессоров, что однако существенно меньше максимальной 36 процессорной конфигурации. Можно заметить, что хотя сам процессор Alpha 437 МГц очень мощный, оценка SPECrate_fp в системе DEC AlphaServer 8400 ограничена производительностью общей шины 87.5 МГц. В системе Sun UltraEnterprise падения производительности не видно, из-за того, что в ней используется комбинация шины локальной памяти (переключатель UPA) и общесистемной шины Gigaplane. В SMP сервере J40 используется коммутатор памяти фирмы IBM. Оценивая эти результаты, нужно не забывать, что SPECrate изначально был определен для общей памяти и не предназначался для измерений в архитектурах с распределенной памятью.
Следующим рассмотрим тест Linpack NxN, оценивающий производительность самых мощных вычислительных платформ на решении системы линейных уравнений. Тест Linpack используется для составления списка TOP500 и приводимые оценки результатов Convex Exemplar S заслуживают особого внимания, особенно если сравнить их с предшественником - SPP1600. Таблица 2 указывает на то, что Exemplar S имеет лучшую производительность по Linpack, чем конкурирующие модели даже с большим числом процессоров. Однако, Linpack все же измеряет производительность в "лучшем случае", поскольку при его выполнении число обменов между процессорами мало и механизмы, поддерживающие иерархию памяти, задействованы слабо.
Таблица 2.
Результаты теста Linpack (GFLOPS).
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Параллельные тесты NAS Parallel Benchmark (NPB) предоставляют более широкий выбор с различными соотношениями между объемом вычислений и обмена. Сейчас имеются данные об Exemplar S по 8 тестам NPB класса A, результаты по 3 тестам приводятся на рисунках 7-9. Из них видно, что Exemplar в конфигурациях до 16 процессоров показывает примерно одинаковые результаты с SMP системами Power Challenge 90 и компьютером со смешанной архитектурой IBM SP.
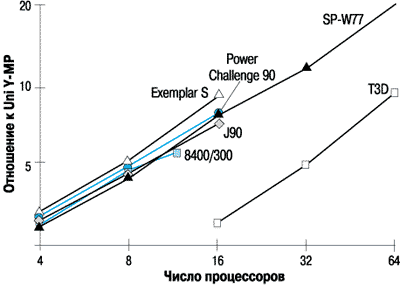
Рисунок 7.
Вычислительная динамика жидкостей (NPB класс А).
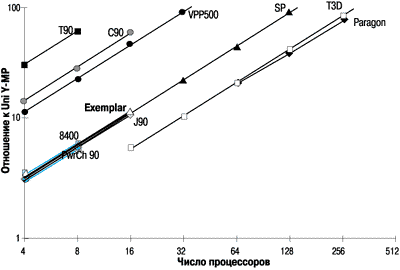
Рисунок 8.
Вычисление интеграла методом Монте-Карло (EP).
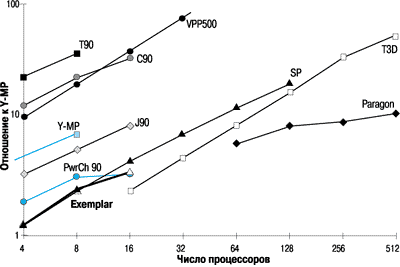
Рисунок 9.
Быстрое преобразование Фурье (FT).
Убедительных подтверждений преимуществ масштабируемости архитектуры Convex NUMA придется, однако, подождать до появления Exemplar X в 1997 году.
Литература
[1]. В.Шнитман, Системы Exemplar SPP1200. Открытые системы, N 6, 1995, сс. 42-47.
[2]. М.Кузьминский, Процессор PA-8000, Открытые системы, N 4, 1995.
[3]. Д.Французов, Оценка производительности суперкомпьютеров. Открытые системы, N 6, 1995, сс. 48-51.
