Известно несколько способов повышения производительности компьютерных систем, самый очевидный из которых - разработка более быстрых аппаратных модулей. Однако, принципиально новые аппаратные архитектуры появляются не так часто и тогда выбирается другой путь - когда однопроцессорные системы по характеристикам производительности достигают своего верхнего предела, их заменяют системами с несколькими связанными процессорами. Вокруг способов этого связывания и разгораются сегодня основные баталии. Долгое время на рынке лидировали архитектуры, базирующиеся на концепции общей памяти или на существенно более гибкой концепции симметричного мультипроцессирования (SMP). Однако, с точки зрения сегодняшних перспектив, можно предвидеть, что в ближайшем будущем на коммерческом рынке появятся приложения, для которых потребуются альтернативные процессорные концепции - с принципиально неограниченной масштабируемостью как в отношении производительности, так и размеров памяти. Это не означает, что новые архитектуры будут превосходить любую из сегодняшних - напротив, это обычная реакция на специфические требования конкретных прикладных областей, которые и приводят к созданию специальных процессорных архитектур.
1. SMP и MPP - две судьбы, две архитектуры
Система Reliant RM1000 (альянс Pyramid c Siemens Nixdorf) относится к классу систем с массовым параллелизмом (MPP). Рассмотрим основные характеристики MPP архитектур, используя базы данных в качестве примера типичной коммерческой области их применения.
Сегодня базы данных, как правило, реализуются таким образом, чтобы обработка поступившего от приложения задания реализовывалась путем запуска группы процессов, синхронизируемых через разделяемую оперативную память. Кроме того, для того, чтобы ускорить доступ к информации, части базы данных хранятся в разделяемой глобальной области (SGA - Shared Global Area), которая также доступна для всех процессов СУБД. И в однопроцессорных, и в многопроцессорных системах время реакции зависит от двух главных факторов: производительности процессоров и ввода/вывода. Вообще говоря, большая буферная область также уменьшает время реакции, если только доступ к данным не осуществляется совершенно хаотически.
В многопроцессорных архитектурах SMP (рисунок 1) существенно, по сравнению с однопроцессорными, увеличивается суммарная процессорная мощность, однако в характеристиках системы ввода/вывода такого пропорционального роста нет. Поэтому верхний предел производительности систем SMP диктуется характеристиками системы ввода/вывода. Природа приложений, ориентированных на оперативную обработку транзакций (OLTP), делает необходимым выполнения максимально большого числа запросов, но производительность шины в SMP системах налагает ограничение на масштабируемость, хотя из соображений вычислительной производительности здесь требуются кластерные процессорные архитектуры с разделяемыми дисками. Как показывает практика, в SMP системы, обслуживающие коммерческие БД, не имеет смысла включать больше 30 процессоров. Единственным возможным решением при использовании SMP систем в этих приложениях является создание очень больших буферных областей.
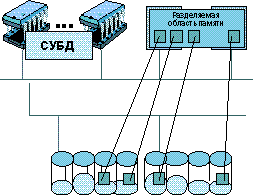
Рисунок 1.
Симметричная многопроцессорная система (SMP).
Архитектура систем с массовым параллелизмом, как и архитектура SMP, позволяет эффективно наращивать производительность за счет увеличения числа процессоров. Однако в этой архитектуре одновременно происходит адекватное увеличение производительности системы ввода/вывода, так как каждый узел имеет собственные средства ввода/вывода, не зависящие от всех других узлов (рисунок 2).
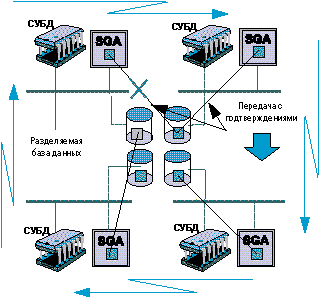
Рисунок 2.
Системы с массовым параллелизмом.
Независимость узлов создает, однако, и проблему - у них нет разделяемой общей памяти, через которую происходит синхронизация различных процессоров в SMP архитектурах. Таким образом, в этом случае необходима быстрая сеть, связывающая индивидуальные процессоры.
MPP системы особенно полезны для приложений, интенсивно нагружающих систему ввода/вывода, когда, например, поиск информации требует сканирования больших участков базы данных. Те из систем баз данных, которые могут распределять запросы по индивидуальным процессорам, создают оптимальные условия для использования MPP архитектур. В отличие от OLTP приложений, именно на такую обработку ориентированы системы поддержки принятия решения (DSS - Decision Support System).
Обслуживая приложения, которые выполняются на нескольких процессорах, СУБД должна функционировать на распределенной основе, используя сеть. Существует три основные способа, с помощью которых это можно осуществить:
1. База данных реализуется на распределенной основе в сети. Части логической базы данных реально распределяются и хранятся на разных процессорных узлах, при этом индивидуальные узлы не имеют доступа к массовой памяти друг друга. Это очевидно приводит к очень высокому уровню обменов в сети - обработка транзакций будет порождать интенсивную перекачку данных между процессорами. Поэтому программное обеспечение базы данных в этом случае должно быть достаточно сложным.
2. База данных устанавливается на распределенной основе в сети с планированием разделения данных по узлам. Каждый процессор работает только со своей подобластью данных и получает соответствующую долю общей нагрузки.
3. Массовая память разных узлов делается совместно доступной для всех узлов. В этом случае возникает необходимость дополнительного программного решения, обеспечивающего синхронизацию доступа для записи в массовую память (Рисунок 2).
Можно использовать несколько способов согласования маршрутов прохождения данных к массовой памяти.
Независимо от того, какой из возможных физических способов соединения выбран, для приложений верхнего уровня требуется обеспечить прозрачный доступ ко всем областям массовой памяти, и это соответствует концепции виртуальных дисков в MPP системах.
Системы с распределенными базами данных нуждаются в средствах синхронизации запросов на запись. Для этого можно использовать, например, локальную сеть, и реализовать глобальную службу блокировки доступа к блокам базы данных, используя технику передачи сообщений. Если находится блок, к которому два узла параллельно хотят получить доступ для записи, должен быть произведен обмен этого блока между претендентами либо через общее дисковое пространство, либо некоторым способом через сеть.
Весьма эффективны механизмы синхронизации в SMP системах, по крайней мере, они значительно лучше, чем подходы, которые используются в кластерах баз данных. Единственной приемлемой альтернативой для минимизации временных задержек, обусловленных проблемой синхронизации, являются высокоскоростные сети и механизм передачи сообщений с подтверждением (block pinging). Однако, OLTP приложения, в которых транзакции приводят к большому числу изменений, более эффективно могут быть реализованы на SMP архитектурах.
Впервые MPP системы начали использоваться на коммерческой основе для поддержки приложений с интенсивным чтением данных и первые MPP приложения были связаны с обработкой данных для систем принятия решений. MPP системы лучше всего подходят для реализации таких приложений БД, которые вносят мало изменений в БД или меняют несвязанные между собой данные. Примерами типичных приложений, обладающих этими свойствами являются следующие.
Все эти приложения главным образом используют доступ для чтения в больших базах данных, и, следовательно, проблема синхронизации для них не имеет особого значения, следовательно они могут фактически неограничено масштабироваться при использовании MPP систем. Таким образом, MPP системы представляют собой альтернативу традиционным мэйнфреймовым архитектурам, особенно с точки зрения масштабируемости по массовой памяти и сетевым связям.
Приведем суммарный список наиболее важных особенностей, отличающих MPP системы.
2. Система Reliant RM1000
2.1 Архитектура
Архитектура Reliant RM1000 (рисунок 3) основана на множестве отдельных процессоров, соединенных высокоскоростной сетью. Такую архитектуру можно назвать слабо связанной, так как отдельные процессоры относительно независимы друг от друга, или архитектурой параллельных вычислений с массовой масштабируемостью - по аналогии с MPP - вычисления с массовым параллелизмом.
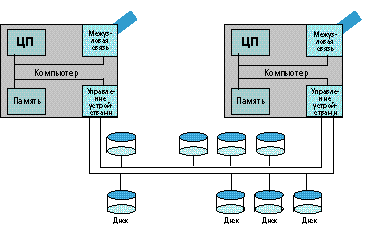
Рисунок 3.
Архитектура системы Reliant RM1000.
Все процессоры в RM1000 имеют собственную оперативную и дисковую память и называются процессорными узлами. Высокоскоростная сеть, соединяющая узлы, организована в виде регулярной решетки, в которой каждый узел подсоединен к сети через маршрутизатор.
Маршрутизаторы (MRC- плата сетевого маршрутизатора) обеспечивают обмен данными между процессорными узлами. Каждый маршрутизатор может одновременно передавать пакеты данных в четырех направлениях.
Узел сети состоит из одного микропроцессора, оперативной памяти, сетевого интерфейса и двух SCSI-2 контроллеров. Системные диски подсоединены к двум узлам: каждая SCSI шина соединена с контроллерами ввода/вывода двух микропроцессоров. Двойное подключение позволяет применять автоматическое переключение при сбое в узле, что гарантирует постоянный доступ к диску.
Компьютер Reliant RM1000 поставляется в следующей конфигурации. Конструктивно процессорные узлы объединяются в ячейки, которых может быть до 32. В ячейку входит 6 микропроцессоров, 24 диска (по 2 или 4 Гбайт), 128-512 Мбайт оперативной памяти на узел, 16 Кбайт первичный и 1-4 Мбайт вторичный кэш. В качестве процессоров используются модели из семейства MIPS Rxxxxx.
Маршрутизация данных. Узлы могут взаимодействовать со своими четырьмя соседями через четыре пары коммуникационных каналов, соединенных с MRC. Каждая пара каналов имеет интерфейс шириной в 8 бит и работает на частоте 50 МГц. Кроме того, для управления передачей данных между двумя MRC задействованы дополнительные сигнальные линии. Коммуникационные каналы используют асинхронный протокол передачи данных, а средняя скорость передачи, полученная в результате измерений, составляет 160 Мбайт/сек.
Каждый MRC может без конфликтов одновременно работать с четырьмя коммуникационными каналами, передавая, таким образом, до 200 Мбайт/с (4*50). В коммуникационных каналах не предусматривается проверка четности или какой-либо иной механизм контроля ошибок - целостность пакетов данных гарантируется путем использования контрольных сумм пакетов.
Передаваемые по сети данные делятся на флиты (flit) и пакеты. Флит является наименьшей передаваемой по сети единицей данных (8 бит). Когда MRC посылает данные в соседний MRC, для управления процессом прохождения данных используются сигналы запроса/подтверждения. Если принимающий MRC не в состоянии больше получать данные, он прекращает посылать подтверждающие сигналы и посылающий MRC переходит в состояние ожидания. Передача возобновляется после посылки подтверждающего сигнала.
Пакет состоит из последовательности флитов. Первые два флита из пакета являются адресными и управляют прохождением данных по сети. Остальные флиты составляют собственно пакет данных, а самый последний флит - хвостовой - сигнализирует о конце пакета.
Технология движения пакетов по сети напоминает продвижение червя. Два первых флита пакета генерируют путь между передающим и принимающим узлами. Первый из них задает относительное расстояние от передающего узла в направлении запад/восток, а второй флит - в направлении север/юг. По заданному пути передаются флиты тела пакета. При передаче хвостового флита все MRC на пути передачи освобождаются и становятся доступными для передачи следующего пакета.
Преимущества архитектуры. Во всех других мультипроцессорных системах от SNI применялась и применяется архитектура SMP - общая основная память разделяется между несколькими процессорами через системную шину и используются интеллектуальные контроллеры шин ввода/вывода. Каждый процессор имеет прямой доступ к памяти. Архитектура Reliant RM1000 дает следующие преимущества.
Надежность, работоспособность, легкость в обслуживании. Достижение этих целей связано с использованием избыточных технических компонентов и механизмов автоматического восстановления после сбоя для критических системных функций. Легкость обслуживания достигается за счет поддержки автоматической диагностики ошибок, генерации сообщений, например, автоматического звонка в ближайший сервисный центр, и замены отдельных устройств без прекращения работы системы. Предусмотрено дублирование ключевых компонентов.
Система Reliant RM1000 снабжена также функцией автоматической коррекции ошибок для сети, дисков, процессорных узлов, источников питания и вентиляторов. Поскольку архитектура системы имеет высокую степень модульности и избыточности, отдельные компоненты могут заменяться без остановки работы.
Служебная сеть. Система Reliant RM1000 имеет служебную сеть для слежения и контроля за источниками питания, вентиляторами и аппаратными функциями. Такая сеть состоит из контрольных процессоров, которые осуществляют мониторинг внутри ячеек, состоящих из нескольких узлов, и между ними. Каждая ячейка для этих целей дополняется CEN картой, которая работает, как узел контроля за средой. Внутри ячейки служебная сеть выполняет следующие контрольные функции:
Кроме этого, служебная сеть используется для выполнения управляющих функций в масштабе всей системы, осуществляя перезапуск процессорных узлов, маршрутизаторов и всей остальной аппаратуры системы.
2.2. Операционная система
Операционная система Reliant RM1000 была разработана как основа для работы серверных систем баз данных, обладающих свойствами высокой производительности и масштабируемости. Для этого в ОС было реализовано ряд функций, направленных на поддержку параллельной архитектуры с массовой масштабируемостью.
Распределенная операционная система. Взятая за основу операционная система UNIX, была расширена для того, чтобы обеспечить оптимальную поддержку сильных сторон архитектуры Reliant RM1000: высокой степени готовности с минимальной зависимостью между индивидуальными системными компонентами (узлами, дисковыми модулями и т.д.) и копировании глобальных ресурсов.
Для таких баз данных, как Oracle 7 Parallel Server и Informix-OnLine Extended Parallel Server V.8, требуется унифицированный доступ к дисковой периферии - все процессорные узлы должны иметь один и тот же способ доступа ко всем системным дискам. Кроме того, необходим механизм глобальной блокировки для синхронизации параллельных обращений к дискам и для администрирования кэша БД. Базы данных, подобные Informix-OnLine Extended Parallel Server V.8, работают с данными, разделенными между процессорными узлами. Каждый узел управляет своими собственными данными и работа распределяется по процессорным узлам в соответствии с распределением данных.
Базы данных имеют надежные встроенные механизмы, которые позволяют успешно справляться с ситуациями, когда выходят из строя отдельные процессорные узлы. В таких случаях целостность базы данных автоматически восстанавливается на оставшихся неповрежденными узлах и гарантируется минимизация периода времени, в течении которого система находится в неработоспособном состоянии. Поэтому от аппаратуры и операционной системы требуется только минимальная поддержка реагирования на поломки процессоров.
Для поддержки перечисленных потребностей в операционной системе Reliant RM1000 предлагаются следующие средства:
Старт системы, конфигурирование и начальная загрузка выполняются посредством управляющих программ, каждая из которых запускается и работает только на собственном узле. Имеется также ряд других программ, специально созданных для Reliant RM1000, которые выполняются параллельно на нескольких узлах и поддерживают функционирование всей системы в целом.
Средства управления вводом/выводом. Средства управления вводом/выводом (IOCF) - это набор команд, библиотек и инструментов, которые обеспечивают, чтобы различные компоненты Reliant RM1000 работали параллельно друг с другом без конфликтов. Средства IOCF поддерживают устойчивость конфигурации и среды системных ресурсов, а также выполняют постоянный мониторинг для сбора нужной для системы информации о неисправностях в узлах или на дисках. Информация, полученная таким образом, хранится в пирамидальной объектной базе данных (POD).
Средства межузловой коммуникационной связи. Средства межузловой связи (ICF) - это основной механизм передачи и управления потоками сообщений между узлами и ячейками. Коммутация пакетов, обеспечиваемая ICF, весьма надежна. Сообщения, посланные посредством этого механизма, подтверждаются принимающим узлом. Если при передаче сообщения происходит ошибка, на передающий узел посылается соответствующее сообщение и инициируется повторная операция. ICF выполняет функции обеспечения совместимости с протоколом доступа к среде (MAC2 protocol); фрагментации и восстановления сообщений; управления потоком при соединении; распознавания поломок узлов; распознавания и повторной передачи утерянных пакетов; поддержки прямого доступа к памяти (DMA).
Пирамидальная объектная база данных (POD). Вся информации по аппаратной и программной конфигурации системы хранится в объектном виде в базе данных - POD. Эта база данных используется в качестве справочного каталога для администрирования и не имеет каких-либо интерфейсов для прикладных программ. POD доступна из всех узлов загрузки системы. Узел загрузки - это такой системный узел, на котором при рестарте системы питание включается в первую очередь. С него устанавливается общая конфигурация и затем загружаются другие узлы. POD обеспечивает следующие функции:
Распределенный менеджер блокировки (DLM). Средства DLM обеспечивают базовый механизм глобальной блокировки для синхронизации в сети. Они дают возможность пользователям - системным клиентам на разных узлах производить глобальный захват разделяемых ресурсов для синхронизации доступа к ним. Такая координация обеспечивает гарантию полной согласованности работы большого числа процессоров. DLM устойчив к сбоям: в случае выхода из строя какого-либо узла блокировка ресурсов реконструируется и заново распространяется по сети. Для выполнения своих функций DLM поддерживает:
Виртуальная консоль. Когда система уже загружена с какого-то загрузочного узла, с ней можно установить связь через системную консоль или другой терминал. На виртуальной консоли открывается несколько окон: одно - для выходной информации и по одному окну - для загруженного узла. По команде autoconf происходит автоматическое распознавание распределенной аппаратуры и на экран выводится фактическая аппаратная конфигурация каждого индивидуального узла. Выходная информация включает распределение дисков по процессорным узлам и данные производителя относительно SCSI периферии.
Интерфейсы системного администратора (MVM и CLI). Операционная система поддерживает два типа интерфейсов: визуальный менеджер сети (MVM) - графический интерфейс в стиле Motif и строчный командный интерфейс (CLI). Графический интерфейс MVM обеспечивает доступ к функциям IOCF, устанавливается на одном из узлов системы RM1000 и может использоваться через консоль или любой другой X терминал - виртуальную консоль. Виртуальная консоль взаимодействует с узлами по протоколу самого низкого уровня и открывает окно для каждого загруженного узла.
Все задачи администрирования могут быть выполнены с какого-либо одного узла через MVM или CLI.
Обслуживание в оперативном режиме. Аппаратные средства системы RM1000 спроектированы так, чтобы позволить выполнять задачи обслуживания без прерывания работы системы. Это относится к заменам процессорных узлов, дисков, источников питания и вентиляторов. В систему были специально добавлены несколько компонентов программного обеспечения, чтобы облегчить следующие процедуры.
? Работа с SCSI периферией: расширены функции автоматического опознавания изменения конфигурации. В стандартном Unix состав периферии устанавливается при загрузке системы и любое подключение/выключение устройства требует рестарта. Модули MVM сделаны с учетом оперативного режима и любое изменение конфигурации немедленно отражается в окнах консоли.
? Добавление и удаление процессорных узлов: новые узлы можно добавить, осуществив инициализацию и конфигурирование его ресурсов. Узлу присваивается идентификатор и имя, которые заносятся в конфигурационные файлы системы.
Распределенный файл журналирования ошибок. Журналирование ошибок расширяет стандартный аппарат операционных систем, производя запись зарегистрированных аппаратных и программных ошибок, возникающих в любом месте системе, в интегральные Log-файлы. Этот аппарат позволяет фиксировать ошибки масштаба кластера; дублировать записи об ошибках, с целью избежания потерь при выходе из строя узла или диска; использовать специальный интерфейс, позволяющий прикладным программам создавать и обрабатывать записи журнала.
3. Протокол TCP/IP во внутренней сети RM1000
MPP системы, подобные Reliant RM1000, обеспечивающие доступ по сети к каждому из большого количества почти независимых узлов, могут иметь очень сложную сетевую конфигурацию и требуют специализированных сетевых решений. В основе примененного в RM1000 подхода лежит отделение внутренней сети от внешней и создание специального интерфейса для маршрутизации сообщений между ними.
Возможна конфигурация RM1000, в которой для внутренней сети вообще нет выделенной подсети Internet и вся система включена в Internet через один узел. В этом случае специальная функция - Proxy Provider производит отображение всех узлов внутренней сети во внешнюю. Для этого внутренние узлы эмулируются узлами, которые имеют доступ к внешней сети и доступны извне по IP (рисунок 4).
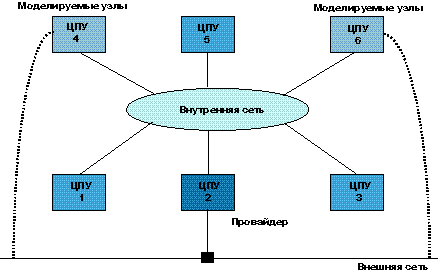
Рисунок 4.
Взаимоотношение внешней и внутренней сети.
Если же на базе внутренней сети в конфигурации строится подсеть Internet, то тогда связь между узлом внутренней сети и внешними системами устанавливается напрямую.
Возможна также комбинация этих способов связи. Например, автоматически распознается ситуация, когда несколько узлов обращаются к одной и той же внешней подсети. Эта информация используется при маршрутизации: при сбое передачи данных происходит автоматическая перенастройка маршрута.
3.1 Виртуальный TCP/IP
В большинстве MPP систем делается явное различие между узлами, имеющими и не имеющими доступ к внешней сети. Для передачи информации между внутренними узлами используется интерфейс на базе TCP/IP, который обеспечивает доступ через внутреннюю высокоскоростную сеть MPP. При таком решении полностью сохраняются все функциональные возможности TCP/IP для организации взаимосвязей внутри и вне MPP системы. Внешняя система может иметь доступ к внутренним узлам через стандартные механизмы маршрутизации. Пакеты данных доставляются к узлам, которые имеют доступ извне, и маршрутизируют эти пакеты внутри MPP системы через TCP/IP. Именно такая реализация была выбрана для системы Reliant RM1000.
При создании сетевой организации, которая бы упрощала администрирование и создание клиент/серверных приложений, необходимо найти компромиссное решение следующих проблем:
Эти проблемы могут быть решены путем использования монитора транзакций или путем введения единого взгляда на MPP систему в целом из внешней сети. Использование монитора транзакций при работе с UNIX не вызывет каких-либо проблем. Однако, такое решение может очень существенно ограничить применимость средств разработки потенциальных приложений. Поэтому в ОС Reliant Unix был реализован распределенный протокол TCP/IP, который включает такие базовые механизмы как: глобальное пространство имен; виртуальные сетевые интерфейсы; интерфейсы с TCP/IP; интерфейсы для конфигурирования.
Глобальное пространство имен. Распределенный протокол TCP/IP прежде всего является глобальным пространством имен для регистрации серверов, предоставляемых видов обслуживания и соединений с клиентами на системном уровне. При конфигурировании производится регистрация услуг, которые будут предоставляться системой. Когда клиент устанавливает связь со службой, это событие также регистрируется в глобальном пространстве имен, как соединение. Тем самым обеспечивается постоянный обзор существующих сервисных связей системы Reliant RM1000. Так как одинаковые услуги предоставляются разными серверными узлами, то компилируются таблицы для распределения серверных узлов по услугам. При получении запроса на какое-то специальное обслуживание распределенный протокол TCP/IP может выделить серверный узел, установив связь на основе этой таблицы. Типичный критерий выбора узла - это, например, "карусель" или выбор по кругу, либо выбор по степени рабочей нагрузки узла на момент установления связи.
Виртуальные интерфейсы с виртуальным TCP/IP. В распределенном протоколе TCP/IP виртуальный интерфейс устанавливается по виртуальному IP адресу, которому реально соответствует группа процессорных узлов. Когда клиент выдает запрос на какое-то обслуживание, он указывает виртуальный IP адрес и идентификатор нужных услуг, например, услуг базы данных. Из группы серверов с данным IP адресом выделяется один реальный узел и устанавливается соединение узел - клиент.
Узлы сети могут быть сгруппированы любым числом способов. В примере, представленном на рисунке 5, к узлам 1, 2 и 3 можно получить доступ через виртуальный адрес vi0, а к узлам 4,5 и 6 - через виртуальный адрес vi1. Кроме того, получить доступ ко всем узлам можно через адрес vi2.
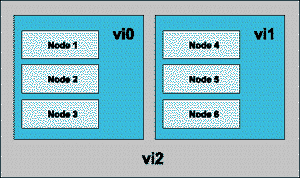
Рисунок 5.
Виртуализация узлов.
Распределенный протокол TCP/IP может подразделять узлы сети на пулы, имеющие независимые пространства имен, причем узлы из разных пулов не могут обмениваться информацией друг с другом. Если распределенный протокол TCP/IP не установлен, все узлы принадлежат разным пулам, каждый из которых содержит один процессорный узел.
