Сети хранения могут привести к крупнейшему изменению парадигмы в компьютерном мире с момента появления локальных сетей.
Сети хранения (Storage Area Networks, SAN) — всего лишь последнее увлечение. На вашем месте я бы не стал заниматься их серьезным изучением и не торопился бы использовать эту технологию в своей практике. Конечно, все это при условии, что вы не боитесь пропустить одно из крупнейших изменений парадигмы с момента появления локальной сети. Я думаю, что в ближайшие несколько лет сети хранения станут столь же широко распространены, как и локальные сети. Если сейчас вы считаете, что любой сервер должен находиться в локальной сети, если ему необходим доступ к другим вычислительным ресурсам, то непременно будете убеждены и в том, что любой сервер обязан быть подключен к сети хранения, если ему требуется доступ к ресурсам хранения. Крупные дисковые массивы и библиотеки магнитных лент станут применяться повсеместно, и каждый, кто подключается к SAN, получит возможность использовать эти ресурсы. Я уверен, что это откроет невиданные ранее возможности хранения, точно так же как распространение технологий локальных и глобальных сетей в конечном итоге привело к появлению Internet.
Все вышесказанное может показаться чересчур оптимистичным, но я надеюсь, что SAN хотя бы немного вас заинтересовали. Разговор о сетях хранения стоит начать с анализа сложившейся ситуации для того, чтобы понять, почему размер памяти среднего сервера стал расти экспоненциально. Затем мне хотелось бы остановиться на вопросе о том, каким образом сети хранения могут улучшить положение дел. Кроме того, из данной статьи вы узнаете, почему растет популярность SAN, хотя ответ довольно прост: это нужное решение, появившееся в нужное время. Необходимо также объяснить, чем сеть хранения отличается от локальной сети или NAS.
Последние десять лет емкость накопителей на магнитных лентах росла экспоненциально. И на то есть причины. За это время требования к емкости хранения для среднего сервера выросли более чем в десять раз! Всего восемь лет назад хост с дисковой подсистемой емкостью 7 Гбайт назывался «монстром» из-за его гигантского размера. Теперь типичный хост, с которым системам резервного копирования и восстановления приходится иметь дело, обладает памятью в 50—100 Гбайт. Причем хосты с емкостью от 500 Гбайт до 1 Тбайт становятся вполне обычным явлением.
ПРИВЫЧКА — ВТОРАЯ НАТУРА
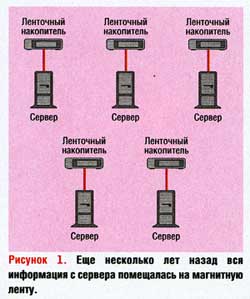
Когда-то серверы в центрах обработки данных имели такую небольшую емкость, что информация, которую они хранили, целиком помещалась на магнитную ленту. Часто на одной и той же ленте содержались резервные копии данных с нескольких систем. В подобных центрах обработки данных архитектура систем резервного копирования выглядела так, как показано на Рисунке 1. Многие или даже большинство систем поставлялись со своими ленточными накопителями, причем их хватало для резервного копирования всей системы, и зачастую на них можно было хранить резервные копии и для других систем. Все, что требовалось для полностью автоматического резервного копирования, — это написать несколько небольших сценариев для оболочки и утром поменять несколько лент.
В то время пропускная способность не составляла сколько-нибудь серьезной проблемы, прежде всего по причине небольшого объема копируемых данных. Даже если в разделяемой сети на базе одного концентратора на 10 Мбайт происходило множество коллизий, объем информации, пересылаемой по сети, был невелик. И к тому же многие системы имели собственные ленточные накопители, поэтому им не требовалось пересылать никаких данных по локальной сети.
Постепенно многие начали наращивать свои системы. Либо им надоело менять множество лент, либо информация не умещалась больше на одной ленте. Отрасли требовалось кое-что получше.
СНАЧАЛА СТАЛО ЛУЧШЕ, ПОТОМ ХУЖЕ
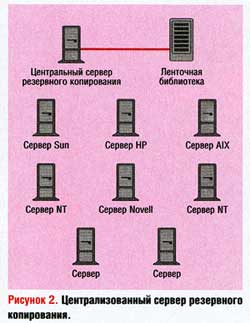
Некоторые первые новшества были связаны с концепцией централизованного сервера резервного копирования. Сочетание этого решения с ленточным накопителем снова сделало ситуацию управляемой. И все, что требовалось, — заплатить 5—10 тыс. долларов за программное обеспечение резервного копирования, еще 5—10 тыс. долларов за аппаратное обеспечение, и проблемы решались. Любую из систем можно было скопировать по сети на центральный сервер резервного копирования. Для этого достаточно было установить соответствующий экземпляр программного обеспечения на каждый из «клиентов», резервную копию которых нужно было сделать. Соответствующие программные пакеты были перенесены на все виды платформ, т. е. все системы, показанные на Рисунке 2, можно было скопировать на резервный сервер, вне зависимости от операционной системы.
После этого возникла новая проблема. Многие стали считать, что достаточно купить экземпляр клиентского программного обеспечения, и все проблемы резервного копирования будут решены. Однако, по мере того как сети становились все больше и больше, выполнять резервное копирование за одну ночь оказывалось все труднее. Конечно, очень помог переход от разделяемых сетей к коммутируемым, как и появление сначала Fast Ethernet (100 Мбит/с), а затем соединений с пропускной способностью 400 Мбит/с (за счет объединения в один канал соединений на 100 Мбит/с). Но некоторые системы оказались слишком громоздкими для того, чтобы их резервное копирование можно было выполнять по сети, особенно при наличии крупных серверов баз данных, имевших емкость от 100 Гбайт до 1 Тбайт.
СОВРЕМЕННОЕ КОПИРОВАНИЕ — БЕЗ SAN
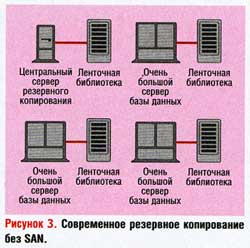
Несколько компаний, выпускающих программное обеспечение резервного копирования, пытались решить эту проблему за счет введения промежуточного сервера. На Рисунке 3 центральный сервер резервного копирования по-прежнему управляет всеми операциями резервного копирования и поддерживает большое количество клиентов по сети с пропускной способностью 100 или 1000 Мбит/с. Однако теперь библиотеку магнитных лент можно подсоединить к каждому из крупных серверов баз данных, чтобы они могли выполнять резервное копирование на свои собственные, локально подключенные ленточные накопители, вместо того чтобы пересылать данные по сети.
Это решило острую проблему нехватки пропускной способности, но потребовало немалых затрат и оказалось весьма неэффективным. Каждому из таких серверов требовалась библиотека магнитных лент, причем достаточно большая, чтобы можно было делать полную резервную копию. Такая библиотека стоила от 50 до 500 тыс. долларов, в зависимости от размера сервера базы данных.
Неэффективность подобного подхода не столь очевидна, как его дороговизна. Для многих серверов такого размера резервное копирование вовсе не нужно осуществлять каждую ночь. Если программное обеспечение базы данных позволяет создавать инкрементальные резервные копии, то полную копию можно делать раз в неделю или даже раз в месяц. Это значит, что в течение остального времени большая часть ленточных накопителей в библиотеке не используется.
Следует учесть и еще один момент — размер библиотеки (в первую очередь число накопителей, которое она содержит) часто определяется требованиями к операции восстановления, а не к резервному копированию. Например, у моего последнего клиента хранилась база данных емкостью 600 Гбайт, для которой потребовалось создать резервную копию. Хотя было сделано все для того, чтобы восстановление с магнитной ленты никогда не понадобилось, одним из условий оставалась гарантия восстановления в течение трех часов. Если для восстановления придется использовать ленточный накопитель, то это должно быть сделано не больше, чем за три часа. Учитывая это, была приобретена библиотека из 10 накопителей стоимостью 150 тыс. долларов. Конечно, если базу данных можно восстановить за три часа, то и ее резервную копию можно сделать за те же три часа. Однако это означает, что библиотека стоимостью 150 тыс. долларов бездействует примерно 21 ч в день. В этом-то и состоит еще один недостаток концепции промежуточного сервера с точки зрения эффективности — аппаратное обеспечение простаивает большую часть времени.
Итак, нужен такой способ резервного копирования на локально подключенные к серверам баз данных ленточные накопители, чтобы они могли совместно использоваться другим крупным сервером в том случае, когда необходимо сделать резервную копию на этот же накопитель. Раньше добиться этого было попросту невозможно.
ОПИСАНИЕ SAN
Для совместного использования ресурсов необходима сеть. Чтобы вычислительные ресурсы были доступны всем сотрудникам, были созданы локальные сети. С их помощью стало возможным обращение к любому вычислительному ресурсу (компьютеру) с любого другого. Это вводит концепцию разделяемого ресурса, который может совместно использоваться несколькими клиентами.
Одним из самых ярких примеров разделяемого ресурса является сетевая файловая система (Network File System, NFS). Она позволяет хранить данные десяткам или даже сотням клиентов и воспринимается ими как локальная файловая система, хотя на самом деле размещается на сервере NFS. Как только клиент сохраняет файл в NFS, другой может считывать или записывать информацию так, как если бы эти операции выполнялись с его локальными дисками. Тем, кто начал работать в отрасли после того, как появились NFS, трудно понять, насколько революционной была эта концепция. Она решила мириады проблем и открыла целый ряд возможностей, которые до ее появления нельзя было даже представить.
Точно так же как локальная сеть позволила создать NFS, так и SAN породила новую концепцию — сетевое устройство хранения (Network Storage Device, NSD). Оно представляет собой обычное устройство хранения (такое, как диск, оптический диск или ленточный накопитель), подключенное к SAN. Причем любым устройством в сети SAN оно воспринимается как локально подключенное. Проще говоря, включение ленточного накопителя в SAN позволяет каждому компьютеру, находящемуся в этой сети, выполнять резервное копирование на ленточный накопитель так, как если бы этот накопитель был физически подключен к нему через кабель SCSI.
SAN ИЛИ LAN?
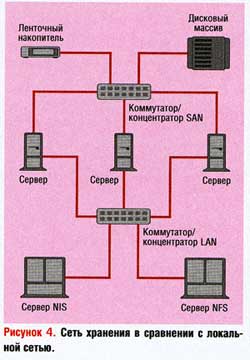
При взгляде на сети, изображенные на Рисунке 4, может возникнуть естественный вопрос: «В чем отличие локальной сети от сети устройств хранения?» Вся разница в протоколе, с которым они работают. Системы в локальной сети для связи друг с другом используют IP, IPX или другие «типичные» сетевые протоколы. Системы в SAN для взаимодействия с сетевыми устройствами хранения применяют протокол SCSI (обычно передавая данные по Fibre Channel).
Термин SCSI может ввести в заблуждение, поскольку этой аббревиатурой называют и физический носитель (кабель SCSI), и протокол для передачи трафика. Разобраться в этом поможет сравнение сетей друг с другом. Трафик IP передается по медной витой паре и волоконным кабелям с помощью протокола Ethernet, а трафик SCSI — по медным кабелям SCSI с применением протокола SCSI. В этом случае последний выполняет те же обязанности, что и протоколы IP и Ethernet. Трафик SCSI доставляется по волоконно-оптическому кабелю и с помощью протокола SCSI поверх протокола Fibre Channel. В данных обстоятельствах протокол SCSI по существу выполняет те же функции, что и протокол Ethernet.
Локальная сеть представляет собой набор серверов, клиентов, коммутаторов и маршрутизаторов, которые передают данные с помощью IP, IPX, Ethernet и аналогичных протоколов, причем, как правило, IP и IPX работают на базе Ethernet. Сеть устройств хранения — это набор устройств хранения, серверов, коммутаторов и маршрутизаторов, в которой данные пересылаются посредством протоколов SCSI и Fibre Channel. Чаще всего SCSI реализуется поверх Fibre Channel.
В период совместного использования удаленных файлов (Remote File Sharing, RFS), т. е. во времена, предшествовавшие NFS, ленточный накопитель можно было смонтировать так, чтобы он поддерживал RFS. В результате накопитель воспринимался так, как будто он был подключен локально, но это не была сеть устройств хранения в ее современном определении. Обмен данными со смонтированным таким образом ленточным накопителем осуществлялся по протоколам UDP и IP, накладные расходы которых существенно больше по сравнению со SCSI. Сервер-отправитель должен был разделить на пакеты блок данных и присвоить заголовок каждому пакету, а сервер-получатель из этих пакетов «собрать» блоки данных. Протокол SCSI в сети устройств хранения практически не влечет дополнительных накладных расходов при записи на ленточный накопитель или диск, как если бы эти устройства были подключены локально.
SAN ИЛИ NAS?
Мне представляется важным рассказать и о том, чем сеть устройств хранения отличается от подключаемых к сети устройств хранения (Network Attached Storage, NAS). Поскольку эти аббревиатуры весьма похожи, данные термины часто путают, особенно учитывая тот факт, что они стали появляться в рекламных материалах примерно в одно и то же время. На самом деле это совершенно разные понятия. Чтобы внести полную ясность, вернемся немного назад.
Сначала существовала NFS, с ее помощью несколько клиентов UNIX могли обращаться к одной файловой системе по локальной сети. Затем появилась единая файловая система (Common Internet File System, CIFS). С ее помощью несколько клиентов Windows и OS/2 могли обращаться по сети к одной файловой системе. Сервер NAS — это просто модуль, который предназначен исключительно для реализации служб NFS и CIFS. (Первоначально такие серверы обеспечивали только хранение на базе NFS, но с недавних пор стали поддерживать и CIFS.) На Рисунке 4 можно видеть сервер NAS, реализующий по локальной сети службы NFS для трех серверов, расположенных над ним.
Благодаря NAS файловая система на другой стороне локальной сети (где используется IP и т. д.) выглядит так, как если бы она была подключена локально. SAN, показанная на Рисунке 4, способствует тому, что устройство на другой стороне SAN также воспринимается подключенным локально.
СОВРЕМЕННОЕ РЕЗЕРВНОЕ КОПИРОВАНИЕ — С ПОМОЩЬЮ SAN
Как же создать SAN и действительно ли она упрощает резервное копирование данных?
Если посмотреть на список всех сайтов Web производителей SAN, расположенный по адресу: http://www.backupcentral.com/hardware-san.html, то возникает ощущение, что нет никаких шансов разобраться во всех возможных сочетаниях систем хранения, предлагаемых с SAN. Однако приложения резервного копирования для SAN довольно просты. Цель создания SAN состоит в том, чтобы к сетевому устройству хранения (библиотеке магнитных лент) могли получить доступ несколько инициаторов операции сохранения (клиентов резервного копирования). Для этого необходимо, с одной стороны, взаимодействие маршрутизатора SAN со SCSI, а с другой — с Fibre Channel, как это показано на Рисунке 5. Для связи адаптеров шины хоста (Host Bust Adapter, HBA) с маршрутизаторами потребуются концентраторы или коммутаторы SAN. И, наконец, вам понадобится продукт резервного копирования, который поддерживает SAN. Он будет действовать как «регулировщик трафика» для всех клиентов, которые теперь начнут конкурировать за право доступа к этому центральному ресурсу хранения.
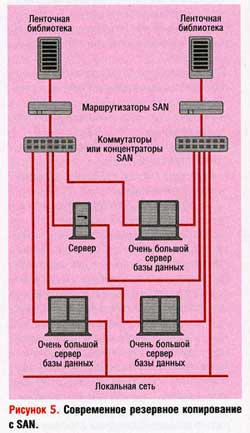
Поскольку библиотеки магнитных лент на Рисунке 5 подключены к маршрутизаторам SAN, а коммутаторы или концентраторы SAN связаны и с маршрутизаторами, и с серверами, все серверы воспринимают ленточные накопители в библиотеках магнитных лент так, как если бы они были физически подключены к каждому серверу, связанному с SAN. Теперь серверы можно настроить так, чтобы они распознавали ленточные накопители. Например, ввести на сервере Sun команду drvconfig и указать накопители, а на сервере HP-UX — команду insf. При работе в других операционных системах может потребоваться перезагрузка.
После того как всем серверам станут видны все дисководы, может возникнуть хаос, если они одновременно предпримут попытки выполнения операции записи на эти накопители. В данном случае необходимо специальное программное обеспечение, которое будет выполнять функции регулировщика трафика. Оно предоставляется производителем программного обеспечения резервного копирования.
Такие программные пакеты представляют ресурсы хранения клиентам с учетом их требований в каждый конкретный момент. Это называется динамическим выделением накопителей, или разделением накопителей, в зависимости от терминологии конкретного производителя. Лично я предпочитаю термин «динамическое выделение накопителей», поскольку разделение накопителей часто путают с разделением библиотеки. Разделение библиотеки — это просто подключение ленточных накопителей одной библиотеки к нескольким машинам, что позволяет им совместно использовать данную библиотеку. Такой процесс возможен без маршрутизатора сети хранения. Данная библиотека будет доступна всем клиентам резервного копирования, но они не смогут разделять накопители. Разделение накопителей, или динамическое выделение накопителей, позволяет двум различным хостам задействовать один и тот же физический накопитель в разное время в зависимости от своих нужд. В конфигурации, показанной на Рисунке 5, все ленточные накопители в обеих библиотеках могут быть динамически зарезервированы для любого сервера, подключенного к сети устройств хранения. Поскольку для доступа к каждой библиотеке существуют разные пути, вы получаете определенную избыточность. Если одна библиотека, маршрутизатор или коммутатор выйдут из строя, накопители в работающей библиотеке могут быть выделены тем серверам, которым они требуются.
МЕХАНИЗМ РАБОТЫ ДИНАМИЧЕСКОГО РЕЗЕРВИРОВАНИЯ НАКОПИТЕЛЕЙ
Поскольку все клиенты имеют физический доступ ко всем ленточным накопителям в библиотеке, их можно динамически выделять тем клиентам, которым они необходимы. Как все это работает? Предположим, что библиотека ленточных накопителей на Рисунке 5 содержит шесть ленточных накопителей. Первое, что необходимо сделать, — распределить по времени операции создания полных резервных копий трех клиентов таким образом, чтобы никакие две системы не пытались создавать полную резервную копию в одну и ту же ночь. Инкрементальные резервные копии могут (и должны) делаться каждую ночь, поскольку они обычно не требуют той же пропускной способности, которая необходима при создании полной копии.
В ту ночь, когда не предполагается создавать полную резервную копию, каждый клиент получает равное количество (два) из шести имеющихся накопителей для создания своей инкрементальной копии. Если запланирована полная резервная копия, две оставшиеся системы будут выполнять инкрементальное резервное копирование и получат по два накопителя каждая. Системе, выполняющей полное резервное копирование, также будет предоставлено два накопителя. Пока ситуация не намного улучшилась по сравнению с тем временем, когда еще не было SAN. Однако формирование инкрементальных резервных копий закончится значительно быстрее, чем полной копии. Программное обеспечение динамического выделения накопителей может затем переназначить четыре накопителя для выполнения полного резервного копирования, учитывая, что втрое увеличивает потенциальную скорость передачи данных, поскольку теперь можно использовать все шесть ленточных накопителей. Это и определяет различие между полным резервным копированием, занимающим 24 ч, и резервным копированием, которое длится 8 ч.
При наличии SAN все накопители используются максимально эффективно. Резервное копирование выполняется локально и не затрагивает локальную сеть. Пропускная способность ограничена только системной платой сервера и емкостью коммутаторов, маршрутизаторов и библиотек. Но самый сильный эффект достигается при восстановлении, поскольку восстанавливаемый сервер может получить доступ к любым ленточным накопителям в обеих библиотеках. Это позволяет ускорить процесс, не приобретая для каждого сервера отдельную библиотеку с 20 ленточными накопителями.
ИСПОЛЬЗОВАНИЕ SAN
Почему вопрос о применении SAN рассматривается прежде, чем зашла речь о ее создании? Ответ очень прост. До тех пор пока вы не знаете, что можно сделать с помощью SAN, вам не следует ее проектировать! Таким образом, вначале мне хотелось бы дать вам некое представление о потенциальных вариантах использования такой сети устройств хранения. Затем я намереваюсь рассказать о том, как все это выглядит на практике.
По существу, сеть устройств хранения, представленная на Рисунке 6, позволяет делать следующее:
- автономную консолидацию систем хранения;
- интерактивную консолидацию систем хранения;
- создание систем действительно высокой готовности.
Конечно, эти утверждения можно трактовать достаточно широко.
Автономная консолидация систем хранения — это всего лишь иной способ объявить, что вы можете разделять библиотеку магнитных лент между несколькими серверами. Интерактивная консолидация систем хранения позволяет создать пул дисковых систем, которые по мере необходимости выделяются нуждающимся в них серверам. Поскольку с помощью SAN несколько серверов могут обращаться к нескольким физическим дискам по нескольким физическим путям, можно говорить о создании системы действительно высокой готовности.
АВТОНОМНАЯ КОНСОЛИДАЦИЯ СИСТЕМ ХРАНЕНИЯ
В правом верхнем углу Рисунка 6 представлена библиотека ленточных накопителей, подключенная к SAN через маршрутизатор. Предполагается, что существует зона, где находится библиотека ленточных накопителей, и что три сервера, Сервер A, Сервер B и Сервер C, будут воспринимать каждый из накопителей библиотеки так, как если бы они были физически к ним подключены. При подобной конфигурации автоматизированное устройство также будет подсоединено к одной из шин SCSI на задней панели маршрутизатора SAN и окажется доступным для всех трех серверов. Каждый из них затем сможет создавать файлы на устройстве так же, как при параллельном подключении к ленточному накопителю или автоматизированному устройству с помощью SCSI.
И что же дальше? При такой организации каждый сервер может попытаться взять на себя управление как автоматизированными устройствами, так и ленточными накопителями. Если он будет делать это независимо, то наступит хаос. Здесь и требуется программное обеспечение разделения автоматизированных устройств и накопителей от поставщика программ резервного копирования. Оно станет выступать в роли «регулировщика трафика», выделяя ленточные накопители для тех серверов, которые в них нуждаются. Конкретный механизм реализации данного подхода существенным образом зависит от производителя. Приведенное ниже описание справедливо для целого ряда крупных поставщиков.
Один сервер конфигурируется как главный сервер (например, сервер NetWorker или NetBackup Master Server). На нем будет размещаться база данных резервного копирования и планирующей информации. (База данных резервного копирования отслеживает, что именно хранится на каждом из ленточных накопителей.) Этот сервер также выделяется в качестве автоматизированного сервера управления для автомата библиотеки ленточных накопителей, и в результате он будет действовать как «регулировщик трафика». Каждый из двух серверов затем конфигурируется как промежуточный сервер (например, NetWorker Storage Node или NetBackup Media Server). Все накопители в библиотеке конфигурируются в виде «виртуальных» накопителей, к которым серверы обращаются с запросом на использование.
Когда один из серверов должен выполнить резервное копирование или восстановление, он посылает главному серверу запрос на обращение к накопителю. Если главный сервер имеет доступный ленточный накопитель, то он может сразу выделить его этому серверу, после чего доступ к нему со стороны других серверов закрывается. Когда другой сервер обращается с аналогичным запросом, а «свободных» накопителей нет, он получит сообщение о том, что придется подождать, пока накопитель освободится. По окончании работы первый сервер сообщает главному серверу о том, что накопитель ему больше не нужен. Главный сервер может затем предоставить освободившийся накопитель другому серверу, ожидающему ресурс.
Как видно, такая конфигурация обеспечивает динамическое выделение ленточных накопителей. Это также позволяет каждому серверу, подключенному к SAN, выполнять резервное копирование всех данных непосредственно на свой собственный ленточный накопитель. Причем в этом случае можно обойтись без передачи информации по локальной сети и освободить администраторов от необходимости выделения одного или нескольких ленточных накопителей для эксклюзивного использования.
Такое решение позволяет действительно максимально увеличить возврат от инвестиций на приобретение библиотек ленточных накопителей. Вместо того чтобы покупать множество библиотек небольшого размера и подключать несколько ленточных накопителей к каждому серверу, достаточно потратиться на одну или две действительно крупные библиотеки и динамически выделять накопители тем серверам, которым они нужны. Приобретя вторую библиотеку, с помощью SAN вы еще больше увеличите доступность ленточных накопителей для всех серверов. Когда SAN еще не было, промежуточный сервер мог использовать только ту библиотеку ленточных накопителей, которая физически подключена к нему. Теперь всякий раз при покупке очередной библиотеки вы можете добавлять новый уровень готовности к своей системе резервного копирования, поскольку каждый сервер вправе обращаться к любой библиотеке.
ИНТЕРАКТИВНАЯ КОНСОЛИДАЦИЯ СИСТЕМ ХРАНЕНИЯ
В крупных центрах обработки данных нередко тысячи отдельных дисков распределяются между всеми серверами. Множество недостатков такого подхода стимулирует применение сетей хранения. Когда один из дисков выходит из строя, для его ремонта приходится разбирать сервер. Хотя эту проблему можно решить за счет покупки массивов RAID с оперативно заменяемыми дисками и, по крайней мере, одним запасным диском для каждого массива, выделение «горячего» резерва для каждого массива может оказаться весьма дорогостоящим. Кроме того, если резервный диск уже использовался и не был заменен, он не годится для автоматической замены неисправного носителя на другом сервере. И вряд ли стоит делать это вручную, поскольку в таком случае может быть нарушена целостность сервера, с которого заимствован диск.
Я вспоминаю одного клиента, для которого простой любого из его серверов был неприемлем. Как выяснилось, на серверах были установлены некачественные дисководы, причем это стало ясно только после того, как эти серверы достаточно долго поработали в реальных производственных условиях. Внезапно в них появилась протечка масла, из-за которой работа дисков была невозможна. Производитель предложил провести бесплатную замену, но это заняло более года. Хотя данная ситуация и кажется похожей на описанную выше проблему, тем не менее она несколько отличается. Использование отдельных дисков не позволяет с легкостью осуществлять превентивную замену старых или некачественных дисководов.
Еще один вопрос управляемости — выделение пространства. Очень часто одному серверу не хватает дискового пространства, в то время как у другого есть запас. Я знаю один крупный центр обработки данных, в котором диски на отдельных серверах были переполнены, хотя весь центр использовал только 10% всей емкости. Ни один диск из имевшегося дискового массива емкостью 30 Тбайт оказалось невозможно выделить для тех серверов, которые в этом нуждались. Его потребовалось бы перенести с одного сервера на другой, что привело бы к простою обоих серверов.
Размещение дисков в сети устройств хранения поможет справиться с этими и многими другими трудностями. Один из вариантов решений — размещение всей памяти в одном крупном массиве хранения в сети SAN. Этот массив может содержать избыточные источники питания, пути и диски, а также небольшой пул дисков«горячего» резерва для каждой системы. Причем последних в таком случае требуется намного меньше, чем при поддержке дисков «горячего» резерва каждой системы. Когда на каком-либо из дисков в массиве возникает сбой, массив хранения может автоматически заменить неисправный диск и уведомить об этом. Это «аппаратное» решение — самый проверенный метод устранения таких проблем. Однако покупать дорогостоящий массив не обязательно. Вы можете просто поместить JBOD в SAN и использовать корпоративное программное обеспечение управления томами для управления дисками и оперативным резервом.
Любое из этих решений позволяет значительно упростить проактивное обслуживание. Вы покупаете новый диск, подсоединяете его к массиву (или к SAN) и используете соответствующий менеджер томов для того, чтобы включить в работу новые диски и отключить старые. Старые или неисправные диски затем можно снять. Возможно, самое главное преимущество консолидации памяти в SAN — это динамическое выделение пространства. Если к ленточным накопителям могут обращаться серверы, которым они нужны, то точно так же дисководы можно выделять только тем серверам, где требуется больше памяти. Когда станет ясно, что данному серверу выделено слишком много места, лишнее пространство несложно отобрать и вернуть в пул хранения, доступный для всех серверов. Если памяти на сервере не хватает, а диски в резервном пуле хранения закончились, вы можете просто купить еще один диск и подключить его к SAN! Такой подход может также способствовать покупке массивов большего размера, стоимость которых в расчете на 1 Гбайт ниже. Если вы использовали разные диски, а нужно только 10 Гбайт, то покупку массива емкостью 20 Гбайт еще можно оправдать, но никак не 200 Гбайт. Начальство может попросить доказать целесообразность приобретения дополнительных 200 Гбайт памяти. Однако, поместив эти 200 Гбайт в SAN, так что любой сервер сможет использовать их по мере необходимости, преимущества будут очевидны! Намного проще обосновать приобретение тем, что всему центру обработки данных в скором времени потребуется еще 200 Гбайт дискового пространства.
Что же будет с резервным копированием, если всю интерактивную память объединить в SAN? Интерактивная консолидация систем хранения открывает две весьма интересные возможности. Рассмотрим массив хранения, представленный на Рисунке 6. При корректном распределении по зонам он виден всем трем серверам. Что произойдет, если сделать копию данных с Сервер A и открыть к ней доступ со стороны сервера Сервер B? Это позволит Сервер B выполнять резервное копирование данных Сервер A, вообще не создавая никакой нагрузки на Сервер A. А если у компании десятки серверов, резервное копирование которых будет выполняться таким образом? При открытии доступа к копии каждого из этих множеств данных по сети хранения, одного сервера, выделенного для их резервного копирования, было бы достаточно. В результате терабайты данных можно было бы копировать незаметно для серверов, которые эти данные используют. Сейчас так и начинают поступать в центрах обработки данных по всем Соединенным Штатам.
Каким образом это достигается? Идет ли речь о корпоративном менеджере томов или о функции, встроенной в массив хранения, такие копии можно создавать двумя способами. Наиболее распространенный из них — создание «третьего зеркала» данных. Отдельный набор дисков подключается через SAN как дополнительное зеркало к основным дискам, содержащим данные, которые необходимо скопировать. Как только зеркало установлено, приложение, использующее данные, переводится в режим резервного копирования, и зеркало разделяется. После этого приложение выводится из режима резервного копирования. В результате вы получаете полностью независимый набор дисков, который содержит копию ваших рабочих данных. Затем его сколь угодно долго можно использовать для резервного копирования.
Еще один способ сделать копию — так называемый «мгновенный снимок». Вместо того чтобы организовывать полностью отдельное зеркало, с помощью программного обеспечения для создания «мгновенного снимка», формируется «символическое» зеркало. «Мгновенный снимок» — это не физическая копия данных, как в случае с разделенным зеркалом. Для его получения приложение, которое использует основной диск, переводится в режим резервного копирования, создается «мгновенный снимок», и приложение выводится из этого режима. Затем созданный «снимок» появляется на любом сервере SAN как корректный, монтируемый диск, но на самом деле это всего лишь символическое представление.
После того как сделан «мгновенный снимок», программное и аппаратное обеспечение контролирует, какие блоки изменились на данном устройстве с момента его изготовления. Эту технологию называют «копией по записи», и она весьма напоминает «мгновенные снимки», которые можно создать с помощью файловых серверов Network Appliance и Veritas File System. Когда приложение резервного копирования пытается скопировать «мгновенный снимок», приложение генерации «мгновенных снимков» анализирует, какие блоки данных оно запрашивает. Если нужный блок данных не изменился с момента создания «мгновенного снимка», то информацию получают с исходного диска. В случае изменения запрашиваемого блока данных он извлекается из кэш-диска. Все это происходит незаметно для приложения резервного копирования.
Хотя обе рассмотренные технологии могут быть реализованы на локальных серверах и дисках, именно SAN позволила действительно воплотить их в жизнь. Только после размещения систем хранения в SAN «мгновенные снимки» или разделенные зеркала могут быть доступны другому серверу для резервного копирования. Недавно разработанная новая технология для SAN позволяет пересылать данные непосредственно с разделенного зеркала или «мгновенного снимка» на ленточный накопитель в SAN, не задействуя ни один из центральных процессоров. Такое решение часто называют резервным копированием без сервера (serverless backup), а технологию, которая позволяет его реализовать, — сторонней копией (third-party copy).
СИСТЕМЫ ДЕЙСТВИТЕЛЬНО ВЫСОКОЙ ГОТОВНОСТИ
Еще одна область, получившая ощутимое преимущество от появления SAN, — это системы высокой готовности. Поскольку SAN открывает доступ множеству серверов к многочисленным физическим устройствам по различным путям, создать системы действительно высокой готовности становится намного проще. Рассмотрим Сервер B и Сервер C (см. Рисунок 6) — у того и другого в наличии независимые пути доступа к обоим коммутаторам справа. Каждый из этих коммутаторов имеет отдельные пути доступа к двум дисковым массивам. При наличии корпоративного менеджера томов и приложений высокой готовности, два дисковых массива и приложение можно зеркалировать на оба сервера. В такой системе нет ни одной критически уязвимой точки. Эту модель можно расширить до кластеров из десятков систем с разделяемыми общими функциями.
Кластерные системы ставят уникальную задачу для систем резервного копирования и восстановления. Тактики использования разнообразны. Первый способ состоит в резервном копировании обоих узлов как клиентов. Резервная копия будет создана для всей информации, но разделяемые данные придется копировать дважды. (На самом деле это нужно делать столько раз, сколько узлов в кластере.) Другая тактика заключается в резервном копировании кластера как целого. Некоторые файлы конфигурации операционной системы на отдельных узлах в этом случае могут не попасть в резервную копию, а вот копировать разделяемые данные потребуется только однажды. Уровень сложности любого метода резервного копирования кластера зависит от поддержки им оперативного восстановления работы отдельных приложений. Лучший пример этому — приложение Tru64 TruCluster компании Compaq. Оно позволяет передавать выполнение каждого приложения с одного узла на другой, не затрагивая другие приложения. Достоинство такого подхода в том, что приложения можно распределить между несколькими узлами кластера, но непросто узнать, какой именно узел содержит базу данных Oracle. Вас могут ожидать следующие трудности.
- Вы пытаетесь создать резервную копию объекта, известного как кластер А.
- Приложение резервного копирования регистрируется в кластере, но на самом деле оно регистрируется на узле A или узле B.
- На одном из узлов A или B работает Oracle. На другом располагаются файлы базы данных Oracle, но их нельзя перевести в режим резервного копирования.
- Ваша задача — понять, на каком именно узле работает приложение, а затем выполнить rsh/ssh на этой системе для перевода базы данных в резервного копирования. Это можно сделать с помощью оболочки Cluster Application Availability (CAA) компании Compaq.
Таким образом, кластер ставит уникальную задачу для специалистов по вопросам резервного копирования и восстановления. Хотя тема высокой готовности имеет очень важное значение, она выходит за рамки данной статьи. Я просто хотел бы подчеркнуть, что существует и третья область, где применение SAN дает преимущества, хотя это может вызвать свои сложности.
СОЗДАНИЕ SAN
На Рисунке 6 изображена гипотетическая сеть SAN, состоящая из трех серверов, трех коммутаторов, маршрутизатора, двух дисковых массивов (RAID в отдельном корпусе), дискового массива старшего класса и библиотеки ленточных накопителей. Как насчет создания такого монстра? Но сначала решите, зачем вам это нужно. Только после этого можно подумать, где взять компоненты, необходимые для создания сети устройств хранения. Вот почему, прежде чем объяснить, как создать такую сеть, я рассказывал о возможностях использования SAN.
Какие же производители способны превратить гипотетическую SAN в реальную? Компоненты такой сети могут быть приобретены у множества поставщиков, в разумных пределах, конечно. Любую функциональность, о которой будет говориться далее в данной статье или о которой было сказано выше, обеспечивают, по крайней мере, четверо из них (за исключением «сторонней копии» — эту новую технологию поддерживают пока далеко не все поставщики). Например, резервное копирование на основе разделенных зеркал предлагают Compaq, EMC, Hitachi и IBM, но я уверен, что такие функции поддерживают не только они. Единственное различие в том, как они реализованы и сколько стоят.
Итак, вы должны ясно представлять себе, чего ожидаете от SAN. Надеюсь, данная статья поможет составить определенное мнение об этом. Как только вы соберетесь трансформировать свои идеи в реальный план, вам придется обратиться ко множеству производителей, чтобы понять, какой вклад они могут внести в осуществление ваших намерений и достижение намеченных целей. Например, некоторые из них могут предоставить OEM-версии каждого из компонентов, изображенных на Рисунке 6, в том числе и серверы. (В том случае, конечно, если вы захотите работать с их операционной системой.) Даже если вы откажетесь от их ОС и будете использовать ту, которую предпочитаете, вам стоит приобрести у них все остальное — от адаптера шины хоста до дискового массива старшего класса. Обычно это значительно упрощает работу, поскольку различные компоненты будут тестироваться вместе.
Если компоненты не прошли испытания, можно ожидать неприятных сюрпризов. Я помню один проект, где удалось сэкономить место на объединительной панели за счет подключения маршрутизатора SAN напрямую к HBA крупного сервера UNIX. (Я позволю себе не называть имен производителей сервера и маршрутизатора.) Хотя никаких проблем с такой конфигурацией не ожидалось, ситуация оказалась не столь безоблачной. Маршрутизатор предполагал одно, а HBA — совершенно другое. В результате сервер UNIX сразу оказался в ступоре. Пришлось прописать AL_PA на аппаратном уровне на маршрутизаторе, и эта информация была добавлена в матрицу поддержки маршрутизатора. Надеюсь, что выбранное вами решение уже протестировано в лабораторных условиях, тем самым вы избавите себя от подобных хлопот.
РАЗДЕЛЕНИЕ НА ЗОНЫ
Сеть устройств хранения, аналогичная показанной на Рисунке 6, скорее всего, потребует разделения на зоны таким образом, чтобы не все устройства оказались доступными для всех серверов. Например, доступ к дисковому массиву старшего класса может быть открыт для Сервер B и Сервер C, но не со стороны Сервер A. Однако вам, вероятно, придется открыть доступ к библиотеке ленточных накопителей для всех трех серверов. Сделать это удастся с помощью распределения по зонам. Вы можете обсудить вопросы распределения по зонам с производителями.
После подключения к SAN и выполнения запланированных конфигураций зон каждый сервер способен создать файлы устройств, необходимые для доступа к дискам и ленточным накопителям SAN. Это можно сделать в самых разных версиях UNIX и NT. Например, команды drvconfig, tapes и disks в Solaris позволяют создать корректные файлы устройств без перезагрузки системы. HP-UX использует ioscan и insf, а в NT можно инициировать поиск новых устройств из Control Panel. Однако многие операционные системы пытаются установить метку на каждый диск, который им доступен. Таким образом, вы можете применять распределение по зонам для защиты дисков от других операционных систем. Например, нельзя допускать того, чтобы машина с NT имела доступ к дискам, которые предназначены для Solaris!
Типичная процедура установки предусматривает применение стандартных команд резервного копирования для тестирования доступности каждого ленточного накопителя и дисковода. В случае с UNIX тесты для ленточных накопителей выполняются с помощью dump, tar и cpio, а для NT — посредством NTBACKUP. Чтобы проверить доступность дисководов, используйте dd в UNIX и менеджер диска в NT. Может оказаться, что не все устройства будут видны с первой попытки, и конфигурации SAN или HBA придется изменить, чтобы открыть к ним доступ. Этот шаг, вероятно, самый сложный. Как только все устройства станут доступны там, где это нужно, дальше будет намного проще. Хороший VAR или консультант могут оказать серьезную помощь на данном этапе. После его завершения следует установить приобретенное программное обеспечение управления SAN. Оно поможет управлять сетью устройств хранения и резервировать имеющиеся ресурсы. Это отдельная интересная тема, которую я, возможно, рассмотрю в других статьях.
В. Куртис Престон занимается вопросами организации хранения уже более восьми лет. Он создавал системы хранения для нескольких компаний, входящих в список Fortune 100. С ним можно связаться по адресу: curtis@backupcentral.com.