Какая операционная система обеспечивает лучшую скорость выполнения для сетевых приложений?

В этой статье мы попробуем выяснить, под управлением какой из операционных систем: Linux, Solaris (для Intel), FreeBSD или Windows 2000 — сетевые приложения с высокими требованиями к ресурсам работают быстрее. Мы расскажем о том, какие решения предлагают поставщики сетевого программного обеспечения, а также выясним, каким образом отдельные детали архитектуры каждой из названных систем сказываются на производительности. Кроме того, мы поговорим о том, как выбрать операционную систему для конкретного сетевого программного проекта, и проанализируем результаты сравнения операционных систем, полученных как на тестовых задачах, так и в реальных условиях.
Как было установлено, скорость выполнения зависит, в первую очередь, от архитектуры приложения, а не от операционной системы, под управлением которой оно работает. Результаты тестирования показывают 12-кратное отличие в производительности приложений с архитектурой, основанной на процессах, и архитектурой с асинхронным выполнением. Важно также отметить, что при использовании наиболее эффективной асинхронной архитектуры разница в производительности ОС может достигать 75%. Согласно нашим измерениям, Linux на 35% эффективнее Solaris, оказавшейся на втором месте, за ней следует Windows и, наконец, FreeBSD.
ОСНОВНЫЕ ПОЛОЖЕНИЯ
В компании Lyris Technologies мы разрабатываем высокопроизводительные кросс-платформенные серверные приложения электронной почты. Высокая производительность приложения — это большое конкурентное преимущество, поэтому мы тратим уйму времени, настраивая все компоненты (программное обеспечение, аппаратуру и операционную систему). Наши клиенты часто задают один и тот же вопрос: какая ОС наиболее подходит для предлагаемого программного обеспечения? Либо, если операционная система уже выбрана, они хотят знать, как сделать так, чтобы приложения работали быстрее. Кроме того, в нашей компании есть подразделение, предлагающее услуги хостинга (в рамках модели аутсорсинга услуг). Поэтому мы заинтересованы в сокращениях затрат на аппаратное обеспечение при достижении наибольшей эффективности выполнения приложений для тех клиентов, которые пользуются этой услугой.
Как правило, работа приложения In-ternet разбивается на следующие этапы:
- обработка входящего TCP/IP соединения или установление соединения с другим компьютером;
- после установления соединения — обмен различными текстовыми командами по протоколу TCP/IP;
- эти команды инициируют различные действия — чтение с диска (отображение страницы Web), запись на диск (например, постановка в очередь полученных по электронной почте сообщений) или вызов внешних функций (фильтрация почты, обратный поиск в DNS).
В целом для обеспечения высокой производительности сетевых приложений необходимо:
- как можно быстрее выполнять несколько параллельных задач одновременно;
- эффективно справляться с частыми паузами (это может быть связано с низкой скоростью передачи по TCP/IP или ожиданием получения очередной команды);
- быстро выполнять операции TCP/IP.
Наилучший способ добиться максимальной производительности — учет всех трех вышеупомянутых критериев при разработке архитектуры приложения. При этом самыми важными компонентами архитектуры являются средства управления задачами и средства обработки вызовов TCP/IP.
АРХИТЕКТУРА УПРАВЛЕНИЯ ЗАДАЧАМИ
Известны три типа архитектуры управления задачами.
Один процесс — одна задача (архитектура, ориентированная на процесс). Множество копий программы запускается параллельно, при этом каждая из них выполняет единовременно одну задачу. Иногда новый процесс запускается, как только создается очередная задача (например, inetd, Sendmail), при другом подходе процессы используются повторно (например, Apache). Эта архитектура позволяет добиться хорошей производительности при низком уровне нагрузки. Она позволяет справиться и со средним уровнем нагрузки, если каждому экземпляру процесса не требуется большого объема ресурсов (например, qmail), а операционная система оптимизирована для работы с данным приложением, либо если данный тип приложения не создает слишком много параллельно выполняющихся задач. Использование многопроцессорных серверов оправдано, когда применяется процедура кэширования процессов, а общее число процессов остается достаточно низким (низкая или средняя общая нагрузка). Этот подход может быть реализован во всех операционных системах; однако в случае UNIX он более эффективен, чем в случае Windows (Windows отсутствует системный вызов fork(), и этот метод работает в Windows настолько медленно, что он нечасто применяется.)
Один поток — одна задача (многопоточная архитектура с множеством подпроцессов). Отдельная копия программы запускает несколько потоков, выполняемых в рамках основного процесса, при этом каждая задача обслуживается отдельным потоком. Такие приложения очень хорошо работают при низких и средних уровнях нагрузки. Высокий уровень нагрузки вызывает снижение производительности (которая чаще всего остается приемлемой); однако если нагрузка оказывается слишком высока, то приложение практически перестает подавать признаки жизни. Приложения с множеством потоков обычно позволяют выполнять одновременно от 500 до 1000 задач. Каждая следующая задача использует новый поток, причем ему требуется меньше ресурсов памяти и центрального процессора, чем при создании соответствующего процесса. Многопоточная архитектура используется всего в нескольких проектах с открытыми исходными кодами, так как только некоторые распространенные версии UNIX работают стабильно при значительной нагрузке с большим числом потоков. Производительность многопроцессорных серверов может быть даже хуже, чем у однопроцессорных, так как программные семафоры на многопроцессорных серверах потребляют значительно больше ресурсов. (В качестве примеров многопоточных приложений можно привести такие популярные серверы Web, как Netscape Web Server и Apache для Windows.)
Один поток — много задач (асинхронная архитектура). Одна копия программы запускает несколько потоков (обычно отдельный поток на один тип задач), и каждый поток управляет большим числом задач с использованием асинхронного метода TCP/IP (называемого также неблокирующим). Так как большинству программ не приходится работать с высоким уровнем нагрузки, а асинхронное программирование достаточно сложное, только некоторые приложения поддерживают эту архитектуру. Асинхронные программы хорошо подходят для многопроцессорных серверов, так как в них обычно используются потоки, работающие независимо друг от друга продолжительное время. Поэтому число межпроцессорных блокировок невелико, и каждый поток может быть надолго и эффективно передан конкретному процессору (в качестве примера можно назвать программу-демон DNS BIND).
АРХИТЕКТУРА УПРАВЛЕНИЯ ВЫЗОВАМИ TCP/IP
Вторая важная составляющая повышения производительности — архитектура управления вызовами TCP/IP. На уровне операционной системы существует множество способов выполнения одной и той же сетевой операции. Необходим компромисс между обеспечением требуемой скорости исполнения вызовов TCP/IP и усилиями, направленными на их программную реализацию. Кроме того, некоторые технологии ускорения вызовов TCP/IР доступны не на всех платформах; поэтому требование более высокой производительности может ограничить ваш выбор платформ.
Блокирующие вызовы TCP/IP. Блокирующие вызовы TCP/IP ждут завершения требуемой операции, а затем немедленно реагируют на ее результат. При небольшом количестве задач это обеспечивает немедленную реакцию на события, а при большом — операционная система затрачивает значительные ресурсы на переключение контекста в многозадачной среде, и общая эффективность значительно снижается. Блокирующие (синхронные) вызовы TCP/IP выполняются с очень короткими задержками при низких нагрузках и идеальны для таких приложений, как слабо загруженный сервер Web, где реакция при обращении к странице должна быть очень быстрой. Однако если используется архитектура, ориентированная на процесс, и новый процесс создается для каждого нового соединения (например, inetd), то сокращение задержек от применения блокирующих вызовов TCP/IP будет перекрыто значительными накладными расходами на запуск последующих процессов.
Неблокирующие вызовы TCP/IP. Неблокирующие (асинхронные) вызовы TCP/IP инициируют операцию, а затем переключаются на другие действия, не дожидаясь получения результата. При завершении операции или наступлении очередного события приложение получает соответствующий сигнал и реагирует на него. Этот двухшаговый процесс требует более сложного программирования, и, кроме того, иногда реакция на новое событие занимает пусть небольшое, но время (что ведет к увеличению задержки). Подобная неблокирующая технология обеспечивает гораздо лучшую производительность при средних и высоких уровнях нагрузки. Она может выдержать и самые высокие нагрузки, но время реакции может оказаться несколько больше, чем при блокирующих вызовах TCP/IP.
Каждая из трех описанных архитектур управления задачами соответствует определенной модели системных вызовов TCP/IP. Программы, ориентированные на процесс, и программы со множеством потоков обычно используют блокирующие вызовы TCP/IP, так как они проще для программирования и обладают вполне удовлетворительной производительностью при, как правило, низких нагрузках. Однако в приложении, которое основано на архитектуре асинхронного выполнения задачи, блокирующие вызовы TCP/IP не подходят для целей многозадачного управления. Поэтому если для решения своих задач вы обратитесь к сетевому приложению, основанному на архитектуре асинхронного выполнения задач, то получите все преимущества использования наиболее масштабируемых типов вызовов TCP/IP — так называемых неблокирующих.
ТЕСТ НА РЕАЛЬНЫХ ЗАДАЧАХ
Чтобы оценить производительность различных операционных систем и сетевых приложений, мы разработали три различных теста: тест на реальной задаче, тест чтения и записи на диск и тест на сравнение архитектуры задач. Сравнение производилось для следующих операционных систем: Linux (Red Hat 7.0, kernel 2.2.16-22), Solaris 2.8 для Intel, FreeBSD 4.2 и Windows 2000 Server. На момент нашего исследования это были самые последние версии программного обеспечения, причем мы сравнивали только так называемые «продукты из коробки». Установив операционные системы на одинаковых 4-гигабайтных дисках SCSI-3 (модель IBM DCAS-34330), для испытаний мы применяли один и тот же компьютер (системная плата ASUS P3B, процессор Intel Pentium III на 550 MГц, оперативная память SDRAM на 384 Мбайт, контроллер SCSI Adaptec 2940UW, видеокарта ATI Rage Pro 3D, Ethernet-карта Intel EtherExpress Pro 10/100).
В тесте на реальной задаче измерялась скорость отправления большого количества почтовых сообщений с помощью нашей программы MailEngine. Она представляет собой почтовый сервер, работает во всех тестируемых операционных средах (а также на Solaris для SPARC) и построена на асинхронной архитектуре (с неблокирующими вызовами TCP/IP с использованием системного вызова poll ()). Мы запускали Mail-Engine в тестовом режиме, чтобы 200 тыс. наших абонентов не получили тестовых писем. В этом режиме программа выполняла все шаги по отправке почты, но в последний момент посылала команду RSET вместо команды DATA. Затем соединение SMTP разрывалось, и реально письма клиентам не доставлялись. Наша тестовая нагрузка состояла из одного сообщения, которое нужно было отправить по 200 000 различным почтовым адресам, разбросанным по 9113 доменам. Так как одно и то же сообщение ставилось в очередь для каждого получателя, скорость чтения и записи на диск не была решающим фактором. Мы постепенно увеличивали число одновременных соединений, чтобы наблюдать, как возрастающая нагрузка влияет на производительность.
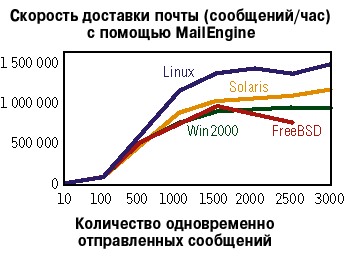
|
| Рисунок 1. Сравнение операционных систем. |
На Рисунке 1 представлена скорость доставки почты в тестовом режиме MailEngine при разном количестве одновременных соединений для каждой операционной системы. Linux является бесспорным лидером по скорости, примерно на 35% опережая идущий вслед за ним Solaris. При добавлении новых соединений общая производительность системы увеличивалась, правда, ее рост практически прекращался, когда число соединений превышало 1500. Производительность FreeBSD несколько снизилась после того, как количество соединений превысило указанную цифру.
В UNIX-подобных операционных системах необходимо настроить ядро ОС, чтобы один процесс мог обслуживать такое число соединений. Но, несмотря на внесенные изменения, FreeBSD выдала предупреждение о нехватке ресурсов и отказалась работать при числе соединений более чем 2500.
ТЕСТ ФАЙЛОВОЙ СИСТЕМЫ
Многие сетевые приложения сохраняют информацию в очереди на диске для ее последующей обработки (например, очередь почтовых сообщений в sendmail) или во избежание переполнения. Мы имитировали типичные ситуации в проведенных тестах. Написанная с этой целью программа на C++ создает, записывает и читает записанный текст в 10 тыс. файлах в одном каталоге (один файл в один момент времени). Для измерения эффективности файловой системы размер файла был увеличен с 4 до 128 Кбайт.
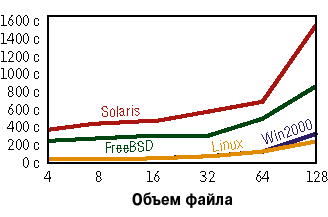
|
| Рисунок 2. Время на создание, запись и чтение 10 000 файлов. |
На Рисунке 2 представлены результаты тестов файловой системы. Скорости Linux и Windows были почти одинаковыми и значительно выше, чем у двух остальных: в шесть раз по сравнению с FreeBSD и в 10 раз — с Solaris. Отметим, какие файловые системы работали в каждой ОС: в Linux — EXT2, в Solaris — UFS, в Windows 2000 — NTFS, в FreeBSD — UFS. Другие файловые системы, без всякого сомнения, показали бы иные результаты. Если вашему приложению часто приходится обращаться к диску, мы рекомендуем использовать Linux или Windows либо установить альтернативные файловые системы на FreeBSD или Solaris.
ТЕСТ АРХИТЕКТУРЫ ПРИЛОЖЕНИЙ
Наконец, мы оценили, насколько быстро сетевые приложения с различной архитектурой выполняются на каждой операционной системе. Мы написали простенькую серверную программу на C++, которая на все входящие соединения реагировала сообщением «450 too busy», используя одну из трех архитектур для управления отправкой ответного сообщения: (1) ориентированную на процесс архитектуру, когда для обслуживания очередного соединения запускается новый процесс; (2) многопоточную архитектуру, где каждому соединению назначается отдельный поток, и (3) асинхронную архитектуру, в которой обработка всех ответных соединений осуществляется с помощью неблокирующих вызовов TCP/IP. Отдельная программа на C++, работавшая на другой машине (под Linux), пыталась как можно быстрее установить соединение с нашей простой серверной программой, постепенно увеличивая число одновременных соединений и одновременно подсчитывая количество успешно полученных ответных сообщений. График, отражающий результаты 12 тестов, слишком громоздок для этой статьи, поэтому вместо него мы поместили другой график, где приведены средние значения для каждой из рассмотренных архитектур с целью демонстрации основных отличий в производительности.
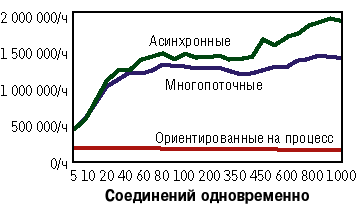
|
| Рисунок 3. Средняя пропускная способность сетевых архитектур (усредненные результаты тестов для Linux, FreeBSD, Solaris и Windows 2000). |
На Рисунке 3 показана производительность для каждого типа архитектуры, усредненная по всем операционным системам. Хотя производительность заметно отличалась для каждой из платформ, но все же не так разительно, как в зависимости от выбора архитектуры. Самой медленной оказалась архитектура, основанная на процессе, и ее производительность составила всего лишь 5% от аналогичного значения для асинхронной архитектуры. Асинхронный метод позволяет справляться с нагрузкой, которая на 35% больше, чем та, какую успешно выдерживает многопоточный метод при 1000 одновременно установленных соединений. Кривые на графике показывают, что разрыв между производительностью этих двух технологий увеличивается с возрастанием нагрузки.
НАСТРОЙКА ЯДРА ДЛЯ ВЫСОКОЙ ПРОИЗВОДИТЕЛЬНОСТИ
При использовании стандартных конфигураций протестированные нами UNIX-подобные операционные системы не поддерживают большого числа одновременных соединений TCP/IP, как это требуется асинхронным приложениям и многопоточным приложениям. Это обстоятельство накладывает ограничение на производительность приложений и может безо всяких на то оснований заставить системного администратора отказаться от применения данных видов высокопроизводительных архитектур. К счастью, подобные препятствия легко преодолеваются путем некоторой настройки ядра. В UNIX каждое соединение TCP/IP использует дескриптор файла, поэтому необходимо увеличить общее число дескрипторов, доступных операционной системе, а также максимальное количество дескрипторов, которое каждый процесс имеет право использовать. Во всех UNIX-подобных операционных системах имеется команда ulimit (sh и bash), с помощью которой, после проведения соответствующей настройки ядра, вы можете разрешить применение большего числа дескрипторов открытых файлов c командами, запущенным из этой оболочки. Мы предлагаем остановиться на ulimit -n 8192 и рекомендуем следующие настройки ядра.
В Linux echo 65536 > /proc/sys/fs/file-max изменяет число доступных системе файловых дескрипторов.
В FreeBSD в /etc/sysctl следует добавить (либо можно использовать sysctl -w, чтобы внести следующие строки):
Kern maxfiles=65536 Kern maxfilesperproc=32768
В Solaris в /etc/system необходимо добавить следующие строки
set rlim_fd_max=0x8000 set rlim_fd_cur=0x8000
после чего систему следует перезагрузить.
РЕЗЮМЕ
Наш тест на реальной задаче показал, что различия в производительности операционных систем с лучшими и худшими показателями достигают 75%, при этом Linux на 35% опережает идущий вслед за ним Solaris. Что еще более важно, асинхронные приложения работали в среднем в 12 раз быстрее, чем приложения, основанные на процессе, и на 35% быстрее, чем многопоточные приложения. Если ваше приложение тратит существенную часть времени на дисковые операции ввода/вывода, то процедуры записи на диск или чтения с него будут идти в 10 раз быстрее под Linux и Windows 2000 по сравнению с Solaris и в 6 раз быстрее по сравнению с FreeBSD.
Если при оценке сетевых приложений для вас важна конечная производительность, то следует помнить, что архитектура программного обеспечения должна быть главным критерием оценки (т. е. следует отдать предпочтение многопоточной или асинхронной архитектуре).
Джерри Ротман — менеджер по технической поддержке и главный системный администратор в компании Lyris; Джон Бакман — основатель и исполнительный директор компании Lyris, а также и создатель оригинальных продуктов ListManager, MailShields и MailEngine.
Как определить, какая сетевая программная архитектура используется
Как правило, в программной документации не указывается, какая сетевая программная архитектура используется. Но так как архитектура — главный определяющий фактор производительности при больших нагрузках, решить эту проблему необходимо. Ниже приводятся приемы, которые можно использовать, чтобы установить внутреннюю структуру приложения даже без знания исходного кода. Прежде всего, вы должны смоделировать ситуацию с высокой нагрузкой — по крайней мере 200 одновременно выполняющихся задач, а потом с помощью тех или иных инструментальных средств проверить, как выполняется процесс.
Linux
- Запустите top.
- Один процесс — одна задача — выполняется много процессов, причем все используют различное количество памяти.
- Один поток — одна задача — выполняется много процессов, все с одинаковым количеством используемой памяти, причем число процессов изменяется с течением времени.
- Один поток — много задач (один поток) — выполняется один процесс.
- Один поток — много задач (несколько потоков) — выполняется много процессов, все с одинаковым объемом используемой памяти, причем число процессов меньше 100.
Solaris
- Запустите ps -efl. Колонка NLWP показывает, сколько «легких процессов» выполняется внутри каждого процесса, причем каждый из них перечисляется в отдельной строке.
- Один процесс — одна задача — если ps -efl покажет многочисленные копии вашего приложения, а каждая копия при этом имеет свой уникальный идентификатор процесса (ID), то приложение построено на основе архитектуры «один процесс — одна задача».
- Один поток — одна задача — ps -efl покажет множество процессов для вашего приложения. Если все они имеют одинаковый ID процесса, а число копий изменяется со временем, значит, приложение использует архитектуру «один поток — одна задача».
- Один поток — много задач (один поток) — будет показан единственный процесс.
- Один поток — много задач (несколько потоков) — ps -efl покажет многочисленные копии вашего приложения, причем все выполняемые копии имеют одинаковый ID процесса, а число копий — не более 100.
Windows 2000 и NT
- С помощью диспетчера задач (Task Manager) можно посмотреть активные задачи, а perfmon.exe покажет число потоков выполняемой задачи.
- Один процесс — одна задача — диспетчер задач отметит приблизительно один процесс на выполняемую задачу.
- Один поток — одна задача — perfmon.exe покажет приблизительно один поток на выполняемую задачу.
- Один поток — много задач (один поток) — один процесс, один поток.
- Один поток — много задач (несколько потоков) — диспетчер задач покажет один процесс; perfmon.exe — не более 100 потоков.
Альтернативные способы исследования внутренней структуры приложений: трассировка системных вызовов
- Команда strace (на Linux) либо truss (на Solaris и FreeBSD) позволяет вывести на экран системные вызовы приложений.
- Команда grep позволяет получить информацию о вызовах select и poll, что обычно свидетельствует об асинхронных, операциях. Poll() эффективнее, чем select(), при большом числе соединений.
- С помощью grep можно просмотреть те вызовы, которые начинаются с aio (что означает асинхронный ввод/вывод) либо lio (список ввода/вывода). Данные вызовы являются признаком сложной асинхронной архитектуры. Например, aio_write(), aio_read(), lio_listio().
- С помощью grep можно также отследить вызовы, которые начинаются с pthread или с thr_ (в Solaris), что свидетельствует об использовании многопоточности. Если новая задача неизменно ведет к вызову pthread_create(), то применяется подход «один поток — одна задача».
Используемые серверы
Мы проводили исследование на компьютере собственной сборки, используя самые надежные компоненты, которые нам удалось найти и для которых имеются необходимые драйверы. Наш стандартный компьютер состоит из: системной платы ASUS P3B или CUV4X Pen-tium III, оперативной памяти RAM на 384 Мбайт, контроллера Adaptec SCSI3, жестких дисков IBM SCSI3 в шасси с двумя вентиляторами, видеокарты ATI AGP Rage Pro 3D и сетевой карты Intel EtherExpress 10/100; причем все это помещено в корпус для монтажа в стойку Antec высотой 4U. Итоговая цена — примерно 2000 долларов за каждый компьютер.
Операционные системы, используемые в Lyris, для сетевых приложений
Solaris 7, 8 для Intel для почтовой рассылки.
- Дешевые стандартные ПК.
- Надежное и высокопроизводительное выполнение многопоточных программ.
- Очень высокая стабильность работы.
- Приемлемая производительность операционной системы.
Windows 2000 для почтовой рассылки на базе на SQL.
- Достаточно высокая стабильность.
- Надежное и высокопроизводительное выполнение многопоточных программ.
- Легко осуществляемое удаленное управление с помощью VNC.
- При использовании сервера MS SQL в качестве хранилища информации надежность гораздо выше, по сравнению с применением файловой системы NT (сбой операционной системы клиента больше не приводит к повреждению информации, кроме того, возможна архивация данных в режиме реального времени, что недоступно в файловой системе NTFS).
Red Hat Linux и Solaris 7, 8 для сервера приложений.
- UNIX более, чем Windows, подходит для серверов приложений из-за его высокой стабильности и несложного восстановления приложений после сбоев.
- Если приложение доступно на всех платформах UNIX, мы используем Solaris по причине его высокой стабильности. Например, большие нагрузки DNS могут привести к сбою ядра Linux (Red Hat 6.1 или 2.2.12-20), а под управлением Solaris DNS работала очень стабильно.
- Некоторые приложения предлагают более широкие возможности в случае Linux, чем для других UNIX-подобных операционных систем, в такой ситуации мы используем Red Hat Linux.
Red Hat Linux для файловых серверов.
- Развитая поддержка Samba (причем двунаправленная, позволяющая к тому же монтировать тома Windows).
- Программная реализация массивов RAID работает быстро и проста в установке (только, увы, не очень надежна).
- FreeBSD w/Vinum (http://www.vinumvm.org) представляется более стабильной и полнофункциональной альтернативой программному RAID (но ее установка существенно сложнее, чем под управлением Linux).
OpenBSD для межсетевого экрана.
- Самая последняя версия ядра (2.8) очень надежна даже при десятках тысяч соединений.
- Встроенная фильтрация TCP/IP на уровне ядра работает очень быстро (гораздо быстрее, чем под Linux).
- Разработчики системы безопасности OpenBSD свели на нет количество используемых по умолчанию функций, для обеспечения высокого уровня защиты.
- Маршрутизация и межсетевой экран могут поддерживаться одной системой, обеспечивая высокую производительность и упрощая управление.