Несмотря на бытующее ошибочное мнение, масштабирование производительности сервера требует большего, чем установка более быстрых микропроцессоров.
Хотите, чтобы ваш фольксваген ездил в два раза быстрее? Для этого недостаточно установить вдвое более мощный двигатель. Тот же принцип применим к современным компьютерам: увеличение тактовой частоты ЦПУ отнюдь не означает, что производительность всей системы соответственно вырастет. Так, скорость доступа к памяти уже безнадежно отстает от ЦПУ, не говоря уже о подсистеме ввода/вывода - хотя результаты имеются и в этой области.
Достижение реальной масштабируемости требует взаимодействия нескольких факторов. Данный факт подчеркивает важность технологии поддержки масштабирования, без которой сетевые вычислительные технологии не поспевали бы за ЦПУ. В этой статье мы рассмотрим некоторые из таких технологий и расскажем, что они дают для масштабируемости критических системных компонентов и процессов.
ПРОЦЕССОРЫ И ПАМЯТЬ
Мы начнем наш анализ с самого сердца современного компьютера и перейдем затем на системный уровень. Аппаратным и программным обеспечением в центре этих устройств выполняется большинство операций, и такое положение дел вряд ли изменится в скором времени.
Увеличение скорости ЦПУ ведет к усовершенствованиям в других частях системы - даже если они и не всегда поспевают вовремя. Некоторое нарушение графика разработки архитектуры x86 следующего поколения вряд ли может серьезно повлиять на развитие технологии, но планируемые сроки освоения нового вида процессоров таковы, что производители должны начать работу над системами следующего поколения намного раньше намеченного момента их появления.
В ближайшей перспективе эти усовершенствования могут представлять собой более быстрые версии имеющихся микросхем с несколько расширенным множеством инструкций. В 1998 году Intel планирует выпустить процессоры под кодовыми названиями Deschutes, Katmai и Williamette. Они будут иметь более быструю внутреннюю шину и поддерживать более сложные трехмерные операции, нежели набор инструкций MMX.
Следующее значительное обновление архитектуры ЦПУ, планируемое на 1999 год, - это процессор Merced. Он знаменует собой отход Intel от архитектуры x86, хотя и будет иметь совместимый режим. Собственная 64-разрядная архитектура Merced обеспечит достаточное увеличение производительности, чтобы похоронить x86 навсегда, но, впрочем, не будем торопиться... (Дополнительную информацию о масштабируемости процессоров смотри в статье М. Гурвица "Многопроцессорные серверы в новом масштабе" в этом номере LAN.)
Что касается памяти, то появление nDRAM, производной от архитектуры Rambus, должно произвести настоящий переворот. Intel сделала немалые вложения в Rambus и сотрудничает с компанией над включением ее архитектуры в следующее поколение своих ЦПУ. Цель - создать память, способную поддержать (и в конечном итоге превзойти) шину со скоростью 100 МГц.
Однако сбрасывать со счетов теперешнего фаворита, Synchronous DRAM (SDRAM), все же не стоит. Производители модулей памяти не желают отдавать 1-2% лицензионных отчислений, как настаивает Rambus, - по крайней мере без борьбы. Многие из них работают над совершенствованием SDRAM для последующего включения ее в компьютерные системы нового поколения.
Данная проблема поднимает также важный вопрос о соотношении скорости процессора и скорости шины. Некоторые процессоры x86 уже имеют тактовую частоту 300 МГц, а процессоры Alpha компании Digital - даже еще большую. Сегодня эти процессоры работают с внешними шинами PCI и EISA с частотой не выше 66 МГц. Так что же, вся избыточная мощь ЦПУ теряется понапрасну?
Не совсем так. Значительные усилия прилагаются к оптимизации интерфейса с памятью, чтобы производительность системы страдала из-за него как можно в меньшей степени. Основной результат этих усилий на сегодня - применение сложных схем кэширования. ПК-системы без кэш-памяти создать можно, но ЦПУ потребуется обращаться к памяти при каждой операции чтения/записи. Система будет функционировать правильно, но такая конфигурация отрицательно скажется на общей производительности.
Благодаря кэш-памяти данные находятся ближе к ЦПУ. Эта быстрая память содержит копию данных, находящихся в гораздо более медленной основной памяти, с которыми ЦПУ работает в данный момент. Вообще говоря, чем больше кэш-памяти имеет система, тем лучше, но такие системы стоят обычно намного дороже, нежели системы с памятью DRAM, так что использование кэш-памяти для ускорения системы ограничено прагматическими соображениями.
Что касается масштабируемости, то здесь с памятью нет проблем. Перевод основных операционных систем и ЦПУ на 32-разрядный режим сделал старый предел в 640 Кбайт полузабытым воспоминанием. Современные системные платы для масштабируемых серверов могут запросто обслуживать 2 Гбайт системной оперативной памяти, а с помощью специализированных устройств - и того больше. Переход к 64-разрядному адресному пространству произойдет, вероятно, задолго до появления соответствующего объема системной оперативной памяти, необходимой для его тестирования.
МАСШТАБИРОВАНИЕ ОС
Большая часть используемых для масштабируемых серверных приложений операционных систем работают в 32-разрядном режиме. Это обстоятельство имеет особое значение в случае приложений для баз данных, где необходим быстрый доступ к огромным массивам информации.
Один из способов масштабировать систему - использовать несколько подсистем параллельно. Если узкое место сервера - центральный ЦПУ, то один из вариантов решения проблемы - установить несколько ЦПУ. Это можно сделать, поставив рядом еще один сервер; однако если второму серверу необходим доступ к той же самой находящейся в памяти базе данных, что и первому, то две системы будут тратить почти столько же времени на взаимодействие друг с другом, сколько и на выполнение полезных функций.
Это привело к созданию компьютеров с несколькими ЦПУ (такая конфигурация называется многопроцессорной). Основная задача здесь - распределение программных задач между ЦПУ, а отнюдь не создание аппаратной системы с несколькими ЦПУ.
Главная цель этих усилий - симметричная многопроцессорная обработка (Symmetrical Multiprocessing, SMP), когда любой из ЦПУ в системе может задействовать свободные циклы без застопоривания работы всей системы.
Такого рода многопроцессорная обработка поддерживается большинством современных серверных операционных систем, хотя и далеко не лучшим образом. Например, современные многопроцессорные системы не масштабируются выше десятка ЦПУ (обычно не более 16 процессоров), и они не являются полностью симметричными. Часто один ЦПУ выделяется для взаимодействия с периферийными устройствами или назначается системным распорядителем (system master).
В прошлом UNIX - изначально разрабатываемый для масштабируемых сред - был единственной ОС для многопроцессорных систем. Однако, с ужесточением конкуренции между UNIX и Windows за доминирование в новых системных архитектурах, пользователи получили более эффективные масштабируемые решения.
СИСТЕМНЫЕ ШИНЫ
До сих пор мы обсуждали ЦПУ, основную память и ОС. Но серверы предназначены для предоставления данных, а это задача подсистемы ввода/вывода. Первые IBM PC имели простую шину данных, представляющую собой ограниченное расширение шины ЦПУ, так что работа подключаемых к шине устройств существенным образом зависела от ЦПУ. С тех пор многое изменилось.
Главный недостаток архитектуры системы ввода/вывода, зависящей от центрального ЦПУ, состоит в том, что она чрезвычайно подвержена перегрузкам. Программируемый ввод/вывод с циклами опроса для мониторинга аппаратного обеспечения неэффективен, но избыточное число прерываний также может нарушить работу системы общего назначения.
Последовательный порт на базе старой микросхемы 8250 UART - хороший тому пример. Буфер для данных на микросхеме очень мал, так что передача или прием каждого символа приводит к генерации прерывания.
Но последовательные порты - весьма простые устройства. Сложные подсистемы типа дисков и сетевых интерфейсов требуют сложного программирования ЦПУ, а также всех соответствующих ресурсов. Даже сложные ЦПУ типа x86 не очень-то хорошо справляются с вводом/выводом, потому что при возникновении прерывания ЦПУ должен сохранить информацию о своем текущем состоянии, прежде чем сможет отреагировать. Такая схема не благоприятствует быстрой обработке прерываний.
Очевидным решением представляется выделение специализированного ЦПУ для низкоуровневого управления устройствами ввода/вывода. Здесь-то и выходит на сцену спецификация интеллектуального ввода/вывода (Intelligent I/O, I2O). I2O определяет аппаратную и программную архитектуру для распределения задач ввода/вывода между интеллектуальными субпроцессорами. В большинстве случаев данные в конечном итоге попадают в ЦПУ, но часто некоторые их типы минуют ЦПУ.
Концепция I2O обманчиво проста. В мэйнфреймах этот принцип используется уже давно, а устройства интеллектуального ввода/вывода с передачей данных посредством прямого доступа к памяти (Direct Memory Access, DMA) вряд ли можно отнести к числу новинок. Отличительной особенностью архитектуры I2O является то, что она допускает прямое подключение к системной шине PCI с помощью определенного программного и аппаратного интерфейса, а также дает спецификацию функциональной среды для самого процессора ввода/вывода (I/O Processor, IOP).
Спецификация I2O определяет несколько конфигураций (см. Рисунок 1). Они имеют разные производительность и стоимость, но главное отличие между ними состоит в том, где находится процессор ввода/вывода - на системной плате или на периферийном устройстве. Это дает производителям системных и периферийных компонентов достаточную гибкость в выборе наилучшей конфигурации для конкретного приложения(-ий).
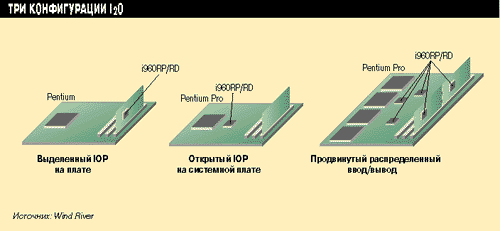
Данная диаграмма демонстрирует три конфигурации, предусматриваемые спецификацией. Основное различие этих схем состоит в том, где находится процессор ввода/вывода - на системной плате или на периферийном устройстве. Процессоры Intel i960 PR/RD являются первыми I2O-совместимыми процессорами ввода/вывода.
I2O СПЕШИТ НА ПОМОЩЬ
Преимущество I2O над ЦПУ-интенсивным вводом/выводом очевидно. То, что выделенный IOP будет справляться с вводом/выводом при управлении как с помощью опроса, так и прерываний лучше, чем и так перегруженный ЦПУ, представляется само собой разумеющимся. Главный вопрос здесь - как I2O выглядит по сравнению с относительно интеллектуальным интерфейсом вроде SCSI.
Как мы увидим позже, SCSI (или, точнее, его последняя инкарнация UltraSCSI) - это распределенная архитектура ввода/вывода с достаточно интеллектуальным управлением внешней шиной ввода/вывода.
Отличие между этой схемой и I2O состоит в том, что последняя предусматривает в качестве аппаратного интерфейса шину PCI внутри системы. Реализовать обработчика I2O для дисковой подсистемы SCSI относительно просто. Но если SCSI уже определяет интеллектуальную архитектуру ввода/вывода, то зачем еще I2O?
От ответа на этот вопрос зависит судьба I2O. Приверженцы SCSI давно поняли, что абстрактный интерфейс управления устройством обладает огромными преимуществами, так как он избавляет программистов от необходимости писать отдельный драйвер устройства для каждой возможной в SCSI комбинации плат устройств/контроллера.
Advanced SCSI Programming Interface (ASPI) - общий для многих устройств SCSI. Этот интерфейс определяет единый способ выполнения устройствами SCSI таких операций, как чтение/запись.
К сожалению, ASPI не скрывает от операционной системы тот факт, что он является интерфейсом к шине SCSI. Другими словами, дисковая подсистема SCSI должна иметь драйвер устройства на базе ASPI (или эквивалентный), отличный от драйвера IDE для диска IDE.
I2O определяет интерфейс для устройств типа используемых для массового хранения данных. Нижележащая технология взаимодействия с устройствами может быть SCSI, IDE или какой-либо иной. Часть драйвера устройства, находящаяся в ОС, должна знать только, как взаимодействовать с интерфейсом I2O.
Производитель периферийного устройства пишет устройство-зависимую часть драйвера, выполняемую в рамках определенной I2O программной архитектуры, а поставщик операционной системы - общую часть для своей ОС.
Некоторые, например группа Linux, высказывают недовольство тем фактом, что спецификация I2O закрытая - данную спецификацию контролирует группа I2O Special Interest Group (I2OSIG), состоящая из производителей оборудования, заинтересованных в I2O. Чтобы получить к ней доступ, организация должна вступить в I2OSIG, поэтому разработчикам условно-бесплатных систем Linux трудно получить доступ к этим интерфейсам.
Членами I2OSIG являются компании Wind River, Intel и Microsoft.
ПЕРИФЕРИЯ PCI
Огромная заслуга в том, что такие новшества, как I2O, стали вообще возможными, принадлежит шине PCI. Она заменила ISA и практически вытеснила другие архитектуры наподобие EISA и VESA Local Bus.
PCI - это интеллектуальный интерфейс для периферии, а не простое расширение шины ввода/вывода в архитектуре x86. Благодаря этому она становится все более популярной не только как шина ввода/вывода для ПК, но и для встроенных приложений. Пропускная способность шины PCI составляет 132 Мбайт/с - значительно больше по сравнению с ее предшественниками.
Однако масштабируемость требует совершенствования каждого элемента системы. Усовершенствования следующего поколения типа средств мониторинга шины разрабатываются в таких продуктах, как Insight Manager компании Compaq.
Идея такого мониторинга состоит в том, чтобы обнаружить ошибку до того, как она вызовет сбой в работе системы. Например, если периферия сталкивается с непонятными ошибками, возобновляющимися при повторении операции, то с большой степенью вероятности можно предположить, что в устройстве возникла какая-то неисправность. Внешнее устройство, взаимодействующее с комплектом микросхем интерфейса PCI, может обнаружить эти ошибки, даже если повторная попытка прозрачна для главного ЦПУ системы.
Другое напрашивающееся усовершенствование - увеличение разрядности шины. ЦПУ начинают расширяться до 64-разрядной шины данных, хотя такое расширение и трудно реализовать.
Digital уже поспешила представить 64-разрядную шину PCI для своего семейства процессоров Alpha (см. Рисунок 2). Intel пока не делала заявлений относительно 64-разрядной шины данных, хотя ясно, что добиться адекватного повышения производительности с помощью 32-разрядной шины вряд ли реально. По этой причине безусловная поддержка компанией Intel 64-разрядной архитектуры станет вряд ли возможна раньше, чем появится Merced. Данный процессор станет первым ЦПУ Intel, поддерживающим архитектуру IA-64, предусматривающую 64-разрядную шину данных и адресов.
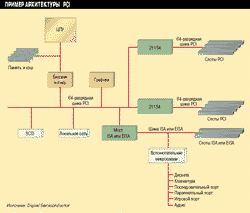 (1x1)
(1x1)64-разрядная микросхема моста PCI 21154 компании Digital Semiconductor позволяет увеличить емкость системы за счет добавления большего числа устройств или слотов PCI, чем может поддерживать одна шина PCI. Микросхема 21154 обладает большим буфером, чем первые мосты такого рода.
Это усовершенствование нацелено не только на расширение адресного пространства. Шина данных тоже станет шире, благодаря чему данные от и к периферии станут передаваться в два раза быстрее по сравнению с 32-разрядной шиной с той же тактовой частотой.
Альтернативой расширения шины PCI является использование более чем одной шины в системе - такая конфигурация получила название двойной равноправной шины (dual-peer bus). Compaq реализовала ее, создав систему с двумя отдельными путями доступа по PCI к ЦПУ, что дает совокупную пропускную способность ввода/вывода в 267 Мбайт/с (в случае оптимального распределения нагрузки между шинами). Эта конфигурация реализована в серверах ProLiant 1600, 3000 и 5500.
Последней реализацией для PCI является 64-разрядная микросхема моста PCI. Шина PCI относится в первую очередь к комплекту системных микросхем, а не к ЦПУ; это делает данные микросхемы главными переменными в задачах масштабируемости производительности.
Как правило, шина PCI поддерживает максимум 3-4 слота. Серверам нужно обычно больше периферийных устройств, чем определено вышеуказанным пределом, а это вызывает необходимость в микросхемах моста.
Цель моста - иметь несколько шин в одной системе. Архитектура с двумя равноправными шинами служит примером реализации такого сценария. Другие конфигурации с мостами позволяют шине PCI сосуществовать в системе с другими шинными архитектурами. Например, мост между PCI и EISA дает возможность использовать специализированные платы EISA.
ШИНЫ ПОДСИСТЕМ
Компоненты следующего уровня располагаются между интерфейсными платами и самой периферией. Эти интерфейсы меняются столь же быстро, как и остальная часть системы.
SCSI имеют долгую историю последовательных усовершенствований. В результате общая пропускная способность возросла восьмикратно и достигла 40 Мбайт/с в его последней реализации - UltraSCSI, или SCSI-3.
Но общая пропускная способность - это не единственная область, где требуются улучшения. Усовершенствование обработки множественных одновременных запросов сделало последние версии SCSI популярными для приложений, где серверам приходится выполнять несколько интенсивных задач одновременно.
При подобной схеме запросы в очереди на передачу данных переупорядочиваются динамически для достижения максимальной возможной производительности таким образом, чтобы не возникло ошибок.
Уже ведется работа над последовательными версиями SCSI с еще более быстрой передачей данных по шине большей протяженности. Если только не появится какого-либо конкурирующего интерфейса, SCSI ожидают блестящие перспективы в мире серверов.
Хотя мы и назвали SCSI основополагающей технологией, варианты усовершенствования на низших системных уровнях им не исчерпываются. Один из них - Fibre Channel, комплект протоколов, определяющий очень высокую скорость передачи данных (до 1 Гбайт/с) между компьютерами, периферией и другими системами через волоконно-оптический интерфейс.
В зависимости от выбранного интерфейса канал Fiber Channel будет выглядеть для системы как шина SCSI или как локальное сетевое соединение. Единственное отличие для высокоуровневых компонентов любого из двух интерфейсов в том, что соединение функционирует с очень высокой скоростью.
Другой вариант - спецификация IEEE 1394, называемая Firewire, которая некоторыми считается наследницей SCSI. Firewire рассматривается главным образом как интерфейс между вычислительной системой и бытовой электроникой, но часть специалистов прочит ее и на роль интерфейса общего назначения с устройствами массового хранения. В последнем случае она напрямую конкурирует со SCSI.
С точки зрения пропускной способности Firewire весьма конкурентоспособна. В настоящее время ее спецификация определяет скорости 100, 200 и 400 Мбит/с и предусматривает пути модернизации до 800 Мбит/с и гигабитных скоростей.
Но насколько возможности управления данными в Firewire будут достаточны для того, чтобы она смогла заменить SCSI, остается пока неясным. В худшем случае Firewire будет играть важную роль в качестве интерфейса к мультимедийным серверам с потенциалом стать в будущем универсальным интерфейсом к коммуникационным системам и устройствам массового хранения.
Другая подсистемная шина - Universal Serial Bus (USB). Более чем год многие системы обеспечивают аппаратную поддержку USB, так что единственным сдерживающим обстоятельством их развития является отсутствие программного обеспечения в популярных операционных системах.
USB - далеко не явный кандидат на победу в гонке масштабируемости, по крайней мере в том, что касается общей пропускной способности. USB разрабатывалась для поддержки относительно медленных устройств, таких как клавиатура, мышь, последовательные устройства и принтеры.
Следует, однако, помнить, что масштабируемость может вести к необходимости подключения к системе множества устройств такого типа. Чего недостает современным ПК - это достаточного числа прерываний, каналов DMA и адресов ввода/вывода для поддержки большого числа медленных устройств. USB позволяет 128 устройствам совместно использовать один набор этих скудных ресурсов.
НОВЫЕ СЕТЕВЫЕ ПЛАТЫ
Сетевая плата является важным фактором масштабируемости серверов. Однако усовершенствование сетевой платы самой по себе имеет мало смысла, если она уже использует сетевую среду на полную мощь и если кабельная топология или сетевая архитектура не меняются.
К счастью, такие технологии, как Gigabit Ethernet, уже становятся реальностью, а это еще более увеличивает важность сетевых плат. Интеллектуальные концентраторы позволяют еще более эффективно использовать доступную пропускную способность в любой подобласти сети посредством сегментирования или перехода к коммутирующим концентраторам. ATM также постепенно начинает внедряться.
Предел пропускной способности сети устанавливает скорее сетевая архитектура, нежели сетевая плата. Разделяемая сеть на 10 Мбит/с типа 10Base2 может быстро достичь насыщения, даже если сегмент содержит всего несколько сетевых плат. Переход к коммутируемой архитектуре с кабелем из витой пары Категории 5 в качестве среды передачи, например 10BaseT, позволяет предоставить пропускную способность в 10 Мбит/с для каждого ответвления сети. Если сами сети являются масштабируемыми, то пользователи могут добавить серверы вместо того, чтобы масштабировать до бесконечности отдельный сервер.
Следующий шаг - переход к более быстрой сетевой технологии. Так, переход к Ethernet на 100 Мбит/с осуществляется достаточно безболезненно, причем в некоторых сетях и это уже не предел - на повестке дня стоит Gigabit Ethernet.
ЗАДАЧА МАСШТАБИРУЕМОСТИ
Технологии, которые мы обсудили в этой статье, уже доступны в том или ином виде, но далеко не все из них готовы для массового использования. Однако они уже приносят реальную пользу, а будущее для многих выглядит весьма многообещающим. Масштабируемость вряд ли когда-нибудь исчезнет с повестки дня, но производители аппаратного и программного обеспечения уже готовят инструментарий для построения систем следующего поколения.
Ларри Миттаг - вице-президент по встроенным системам в Stellcom Technologies. С ним можно связаться по адресу: larry@stellcom.com.