В сетях коммутации пакетов маршрутизаторы выполняют функцию приема и передачи сообщений. Так как же они работают
Маршрутизаторы одновременно и просты и сложны. Однако познакомиться с ними будет небесполезно, поскольку они обеспечивают работу как Internet, так и корпоративных сетей. В этой статье мы описываем маршрутизаторы в общих чертах и обращаемся к конкретным сетевым протоколам только тогда, когда это необходимо.
В сети коммутации сообщений все делается при помощи зеркал. Зеркала - это такие устройства, как маршрутизаторы, коммутаторы и мосты. Они получают сообщения через один интерфейс, определяют получателя по той или иной таблице и передают его на другой интерфейс. Одно из основных отличий между маршрутизатором и любым другим коммутатором сообщений состоит в способе построения таблиц. Маршрутизаторы посылают сообщения сетям, в то время как таблицы мостов и коммутаторов содержат список адресов подуровня MAC.
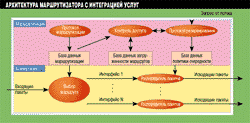
Маршрутизатор выполняет две основные функции: переключение трафика и обслуживание среды, в которой он работает. Обе функции можно реализовать на одном и том же процессоре, но это вовсе не обязательно. Зачастую переключение трафика осуществляет отдельный интерфейсный процессор или процедура обработки прерываний ядра, в то время как процесс обслуживания среды выполняется в фоновом режиме. На Рисунке 1 представлены основные компоненты маршрутизатора с интеграцией услуг, т. е. поддерживающего качество услуг (QoS).
 (1x1)
(1x1)
Рисунок 1.
Архитектура маршрутизатора с интеграцией услуг, т. е. поддерживающего
усовершенствованные алгоритмы QoS, соответствует приведенной схеме.
Верхний уровень на Рисунке 1, уровень маршрутизации, представляет собою часть маршрутизатора, предназначенную для обслуживания среды. Маршрутизатор выполняет целый ряд приложений, причем они могут быть частью сетевой архитектуры или конфигурироваться для удобства администратором сети. Эти приложения, или процессы, выполняются на уровне приложений маршрутизации (Routing Application). Один из таких процессов - доменная служба имен (Domain Name Service, DNS): он кэширует информацию о DNS для обслуживаемых систем. Однако DNS - не обязательная часть архитектуры IP-маршрутизатора, и далеко не каждый согласится с тем, что маршрутизатор должен предоставлять такую услугу. Стандартными сервисами маршрутизаторов являются, например, определение топологии (topology mapping) и управление трафиком (traffic engineering).
Протоколы маршрутизации определяют топологию сети и сохраняют информацию о ней в таблице маршрутизации. Если маршрутизатор не применяет протокол маршрутизации, то тогда он хранит статические маршруты или использует отдельный протокол на каждом интерфейсе. Обычно маршрутизаторы работают с одним протоколом маршрутизации.
Таблица маршрутизации, иногда называемая базой данных маршрутизации, - это набор маршрутов, используемых маршрутизатором в данный момент времени. Строки таблицы маршрутизации содержат, по крайней мере, следующую информацию:
Информация о маршрутизации содержит метрику, т. е. меру времени или расстояния, и несколько отметок о времени. Информация о пересылке включает в себя данные о выходном интерфейсе и адрес следующей системы по пути. Обычно маршрутизаторы хранят данные о нескольких возможных следующих транзитных маршрутизаторах в одной строке таблицы.
Протоколы, используемые при создании таблицы маршрутизации, отличаются между собой, но тем не менее их можно разделить на несколько основных категорий: на протоколы длины вектора расстояния, состояния канала и политики маршрутизации.
ПРОТОКОЛЫ МАРШРУТИЗАЦИИ
Протоколы длины вектора - простейший и наиболее распространенный тип протоколов маршрутизации. По большей части используемые сегодня протоколы этого типа ведут свое начало от протокола Routing Information Protocol компании Xerox (иногда они даже называются этим именем). Протоколы данного класса включают IP RIP, IPX RIP, протокол управления таблицей маршрутизации AppleTalk RTMP и Cisco Interior Gateway Routing Protocol.
Свое название этот тип протоколов получил от способа обмена информацией. Периодически каждый маршрутизатор копирует адреса получателей и метрику из своей таблицы маршрутизации и помещает эту информацию в рассылаемые соседям сообщения об обновлении. Соседние маршрутизаторы сверяют полученные данные со своими собственными таблицами маршрутизации и вносят необходимые изменения.
Этот алгоритм прост и, на первый взгляд, надежен. К сожалению, он работает наилучшим образом в небольших сетях при (желательно полном) отсутствии избыточности. Крупные сети не могут обойтись без периодического обмена сообщениями для описания сети, однако большинство из них избыточны. По этой причине сложные сети испытывают проблемы при выходе линий связи из строя из-за того, что несуществующие маршруты могут оставаться в таблице маршрутизации в течение длительного периода времени. Трафик, направленный по такому маршруту, не достигнет своего адресата. Эвристически данная проблема решаема, но ни одно из таких решений не является детерминистским.
Некоторые из этих проблем решаются усовершенствованным алгоритмом под названием алгоритм диффузионного обновления (DUAL), при этом маршрутизаторы используют алгоритм длины вектора для составления карты путей между ними и DUAL для широковещательного объявления об обслуживаемых ими локальных сетях. Информация об изменениях в топологии также рассылается по всей сети. Примером такого усовершенствованного протокола может служить Cisco Enhanced IGRP.
Вторую категорию протоколов обслуживания среды составляют протоколы состояния канала. Впервые предложенные в 1970 году в статье Эдсгера Дейкстры, протоколы состояния канала сложнее, чем протоколы длины вектора. Взамен они предлагают детерминистское решение типичных для их предшественников проблем. Вместо рассылки соседям содержимого своих таблиц маршрутизации каждый маршрутизатор осуществляет широковещательную рассылку списка маршрутизаторов, с которыми он имеет непосредственную связь, и напрямую подключенных к нему локальных сетей. Эта информация о состоянии канала рассылается в специальных объявлениях. За исключением широковещания периодических сообщений о своем присутствии в сети, маршрутизатор рассылает объявления о состоянии каналов только в случае изменения информации о них или по истечении заданного периода времени.
Недостатком таких протоколов состояния каналов, как OSPF, IS-IS и NLSP, является их сложность и высокие требования к памяти. Они трудны в реализации и нуждаются в значительном объеме памяти для хранения объявлений о состоянии каналов. При всем своем превосходстве над ранними протоколами длины вектора их реальное преимущество перед DUAL далеко не очевидно.
К третьей категории протоколов по обслуживанию среды относятся протоколы правил маршрутизации. Если протоколы маршрутизации на базе алгоритмов длины вектора и состояния канала решают задачу наиболее эффективной доставки сообщения получателю, то политика маршрутизации решает задачу наиболее эффективной доставки получателю по разрешенным путям. Такие протоколы, как BGP (Border Gateway Protocol) или IDRP (Interdomain Routing Protocol), позволяют операторам Internet получать информацию о маршрутизации от соседних операторов на основе контрактов или других нетехнических критериев. Алгоритмы, используемые для политики маршрутизации, опираются на алгоритмы длины вектора, но информация о метрике и пути базируется на списке операторов магистрали.
Одно из следствий применения протоколов такого рода в том, что пути сообщения и ответа на него через Internet, вообще говоря, различны. В корпоративных же сетях Intranet, не использующих политику маршрутизации, эти пути, как правило, совпадают.
ИНТЕГРИРОВАННЫЕ СЕРВИСЫ
Маршрутизатор с интеграцией услуг должен поддерживать протокол резервирования ресурсов (Resource Reservation Protocol, RSVP). Маршрутизаторы этого типа добавляют протокол ресурсов, контрольный модуль и интерфейс к политике очередей уровня коммутации (см. Рисунок 1).
RSVP позволяет системам запрашивать сервисы у сети, например гарантированную пропускную способность, максимальный уровень потерь или предсказуемую задержку. Сообщения "пути" RSVP рассылаются отправителем и отслеживают маршрут передачи данных, оставляя указатели на маршрутизаторах. Этот процесс позволяет маршрутизаторам производить резервирование по пути передачи даже при асимметрии маршрутов. Сообщения о резервировании ресурсов получателем находят источник, следуя оставленным указателям, и производят резервирование по пути.
На маршрутизаторах сообщения о резервировании объединяются при их возвращении к источнику. Как следствие, отправитель - например, рабочая станция в сети - получает сообщение от ближайшего маршрутизатора, а не от каждого из сотен или даже тысяч потенциальных покупателей. Однако резервирование выполняется, только если достаточно ресурсов для его гарантии. Это решение принимается контрольным модулем.
Согласие на резервирование ведет к изменениям политики очередности и базы данных резервирования. Политику очередности, т. е. алгоритмы, определяющие порядок, в котором сообщения обслуживаются, мы обсудим несколько позднее.
Уровень коммутации выполняет и другие важные задачи. Определение топологии сети и политики очередности только вспомогательные задачи, основная же задача маршрутизации - переключение трафика. Переключение - это процесс приема сообщения, выбора подходящего маршрута дальнейшего следования и отправка его по этому маршруту. Данная операция обслуживается четырьмя различными процессами: входным драйвером, процессом выбора маршрута, очередью и выходным драйвером.
При всем многообразии дополнительных возможностей производители стараются сделать этот путь оптимальным по скорости. Путь переключения делается настолько быстрым, насколько производитель в состоянии это сделать, поэтому он обычно называется быстрым путем. Реже используемые (или дополнительные) возможности, например фрагментация сообщений или обработка опций IP-заголовка, делегируются более медленным и более сложным последовательностям процессов.
Многие рассматривают модуль выбора маршрута как основной модуль маршрутизатора. Выбор маршрута осуществляется с использованием классических методик. Например, в простейшем случае код переключения ищет адрес получателя в таблице маршрутизации, выбирает один из возможных следующих транзитных узлов (определенных протоколом маршрутизации), удаляет входной и добавляет выходной заголовки канального уровня, а затем посылает сообщение.
Конечно, вся эта процедура применяется только к действительным сообщениям (основные протоколы сетевого уровня имеют процедуры для квалификации сообщения). Если сообщение слишком велико по размеру для выходного интерфейса, то маршрутизатор вынужден либо фрагментировать, либо отбросить его. Если пакет содержит контрольные суммы (DECnet IV и IPv6 их не предусматривают, в отличие от большинства других протоколов), то сначала проверяется контрольная сумма. Фактически все архитектуры имеют также и счетчик транзитных узлов: маршрутизатор увеличивает его на единицу и сравнивает с предельным допустимым значением. Маршрутизатор отбрасывает недействительные сообщения и уведомляет об этом отправителя.
Некоторые протоколы, в частности IPv4, IPv6 и ISO IP, поддерживают дополнительные поля: они позволяют маршрутизатору записывать путь сообщения по сети и посылать сообщение в принудительном порядке через некоторые системы по пути следования, накапливать отметки о времени, передавать информацию об идентификации и выполнять другие функции сетевого уровня. Эти факультативные процедуры также выполняются модулем выбора маршрута.
После переключения сообщения модулем выбора маршрута распорядитель сообщений определяет момент отправки сообщения. Планирование отправки сообщений - и самая простая, и самая сложная функция уровня коммутации. Маршрутизаторы по большей части либо добавляют сообщение в очередь FIFO (англ. сокр. "первым пришел, первым ушел") ожидающего отправки трафика, либо, если очередь полна, просто отбрасывают их. Такой простой алгоритм довольно эффективен, но опыт управления сетями и недавние исследования показывают, что он далеко не оптимален.
В маршрутизаторе, реализующем архитектуру с интеграцией услуг IETF, алгоритмы обслуживания очередей сортируют трафик в таком порядке, чтобы данные гарантии были выполнены. Часто маршрутизаторы, не поддерживающие QoS, реализуют подобные алгоритмы в целях управления трафиком.
FIFO - ПЕРВЫМ ПРИШЕЛ, ПЕРВЫМ УШЕЛ
Стандартные реализации очереди FIFO первыми отправляют наиболее раннее из полученных сообщений и отбрасывают все последующие, если очередь уже полна. Недавние исследования показывают, что удаление сообщений, по крайней мере для TCP/IP, имеет серьезные побочные эффекты. Например, когда сообщение потеряно, приложение-отправитель может рассматривать это как сигнал о том, что оно посылает пакеты слишком быстро. TCP реагирует на такой сигнал замедлением отправки сообщений. Но когда очередь полна, то часто несколько сообщений отбрасываются друг за другом - в результате целый ряд приложений решает замедлить передачу. После этого приложения зондируют сеть для определения ее загруженности и буквально через несколько секунд возобновляют передачу с прежним темпом, что опять приводит к перегрузке.
Случайное раннее обнаружение (Random Early Detection, RED) представляет альтернативу очередям FIFO. Оно позволяет смягчить эффект от потери трафика даже при очень больших нагрузках, так что приложения не синхронизированы друг с другом, как это имело место в предыдущем случае. Такая очередь по-прежнему использует принцип FIFO, но, вместо того чтобы отбрасывать сообщения из конца очереди, RED отбрасывает трафик статистически, когда средняя длина очереди за данный промежуток времени превосходит некоторое значение. Таким образом, заполнение очереди оптимизировано для обеспечения большей устойчивости алгоритма. Этот процесс был придуман специально для TCP, но те, кто его изобрел, считают, что он применим к любому трафику, когда сеть не гарантирует доставки.
Очередь с приоритетами - это алгоритм, при котором несколько очередей FIFO или RED образуют одну систему очередей. Трафик распределяется между данными очередями в соответствии с некоторыми заданными критериями, например в соответствии с приложением или получателем. Однако трафик отправляется в порядке строгой очередности: сначала трафик с высоким приоритетом, затем со средним и т. д. При всей простоте понимания и реализации этот алгоритм не очень хорошо работает при высоких нагрузках, потому что очереди с низким приоритетом оказываются блокированными в течение продолжительного периода времени или низкоприоритетный трафик имеет такую большую задержку в результате следования по окружному пути, что становится бесполезным.
Очереди в соответствии с классом (Class-Based Queuing, CBQ) - это алгоритм, при котором трафик делится на несколько классов. Определение класса трафика в значительной мере произвольно. Класс может представлять весь трафик через данный интерфейс, трафик определенных приложений, трафик к заданному подмножеству получателей, трафик с качеством услуг, гарантированным RSVP. Каждый класс имеет собственную очередь, и ему гарантируется, по крайней мере, некоторая доля пропускной способности канала. Если какой-либо класс не исчерпывает предоставленный ему лимит пропускной способности, то остальные классы увеличивают свою долю пропорциональным образом.
Взвешенная справедливая очередь (Weighted Fair Queuing, WFQ) является частным случаем CBQ, когда отдельному классу соответствуют независимые потоки. Как и в случае CBQ, каждому классу WFQ соответствует одна очередь FIFO и гарантируется некоторая часть пропускной способности канала. Если некоторые потоки используют предоставленную им пропускную способность не полностью, то другие потоки увеличивают свою долю соответственно. Так как каждый класс - это отдельный поток, то гарантия пропускной способности эквивалентна в данном случае гарантии максимальной задержки. Зная параметры сообщения, вы можете по известной формуле вычислить его максимальную задержку при передаче по сети. Выделение дополнительной пропускной способности позволяет уменьшить максимальную задержку.
Входные и выходные драйверы - это программы и чипы для приема и отправки сообщений из системы. Вообще говоря, они могут рассматриваться естественным образом в рамках протоколов сетевого уровня. Однако протоколы маршрутизации должны учитывать топологические соображения. По этой причине они рассматривают классы компонентов канального уровня по-иному. Обычно компоненты канального уровня характеризуются такими терминами, как локальные сети, каналы точка-точка, сети множественного доступа с виртуальными соединениями, каналы нерегулярного доступа и коммутируемые каналы.
Локальная сеть, вероятно, наиболее известный для сообщества Internet компонент канального уровня. Примерами могут служить сети Ethernet, Token Ring, FDDI и (несколько парадоксально) Switched Multimegabit Data Service. Предназначение локальных сетей не в обеспечении высокой загруженности, а в обеспечении высокой доступности; в результате, когда локальная сеть загружена, ее производительность менее предсказуема и далека от оптимальной. Локальную сеть можно реализовать, используя различные комбинации кабеля, концентраторов и коммутаторов. Но системы в них - как хосты, так и маршрутизаторы - имеют целый ряд общих характеристик. Если вы не занимаетесь написанием драйверов, то тогда отношение к локальной сети как средству предоставления высокодоступных сервисов некоторому множеству систем с заданной скоростью, вполне достаточно.
Каждая система имеет MAC-адрес, идентифицирующий систему в пределах данной сети. Когда какая-либо система отправляет сообщение, адрес сетевого уровня системы-получателя должен быть переведен сначала в MAC-адрес. Как это делается, зависит от протокола: в NetWare МАС-адрес является частью адреса сетевого уровня, в то время как в AppleTalk и IP протокол определения адреса запрашивает системы об их адресах для установления соответствия между адресами канального и сетевого уровня.
Ввиду необходимости такой трансляции каждой системе в локальной сети необходим уникальный адрес сетевого уровня, благодаря которому сообщение может быть доставлено ей по сети; адрес должен содержать достаточную топологическую информацию (обычно в виде номера сети или префикса адреса), чтобы маршрутизаторы знали, куда направлять сообщение. Подобная система идентификации позволяет последнему маршрутизатору передать сообщение непосредственно системе-получателю.
Организация очередей в локальных сетях сопряжена с определенными трудностями, так как системы не знают о поведении своих соседей. Протоколы локальных сетей имеют механизмы, с помощью которых системы могут договариваться об использовании среды передачи для каждого конкретного сообщения. Это согласование осуществляется обычно посредством обнаружения коллизий или передачи маркера. Такой процесс отнимает иногда немало времени, однако ввиду высокой пропускной способности длинные очереди для локальной сети не характерны.
Каналы точка-точка, например PPP или HSSI, представляют полную противоположность локальным сетям, поскольку здесь мы имеем дело только с двумя участниками. Некоторые архитектуры маршрутизации рассматривают их как внутренние интерфейсы между двумя половинками маршрутизатора, в то время как другие - как вырожденный случай локальной сети.
Такие каналы обычно не имеют адресов, потому что маршрутизаторы с обоих концов могут идентифицировать друг друга непосредственно, не беспокоясь о формальном имени. Данная конфигурация имеет определенные достоинства при распределении адресов: нет нужды присваивать каналу номер сети. Кроме того, преобразование адресов производить тоже не надо.
В конфигурации точка-точка очередь, кроме того, проще организовать, так как незачем договариваться об использовании канала. Таким образом, система полностью контролирует характеристики трафика.
Каналы нерегулярного доступа, наподобие асинхронных коммутируемых или ISDN-каналов, во многом напоминают каналы точка-точка, за одним важным исключением. Если прямой канал недоступен, то пользоваться им невозможно, пока он не будет восстановлен. Поэтому маршрутизаторы обмениваются друг с другом сообщениями для нахождения обходного пути по сети. Однако если канал нерегулярного доступа не функционирует в данный момент, то он может быть сделан доступным посредством звонка. При таком сценарии маршрутизаторы исходят из предположения, что канал задействуется по требованию, и при определении топологии они рассматривают такой канал как доступный. Это в какой-то степени фикция (недоступный канал считается доступным), которая требует некоторых изменений в протоколах маршрутизации.
Сети множественного доступа с виртуальными соединениями (называемые также нешироковещательными сетями множественного доступа, или NBMA) включают X.25, frame relay и ATM. С точки зрения маршрутизаторов, сети с виртуальными соединениями рассматриваются обычно как локальные сети или совокупность интерфейсов точка-точка. Они схожи с локальными сетями в том, что каждая система имеет в них свой адрес, однако этот адрес соответствует виртуальному соединению, а не системе или интерфейсу. Если два виртуальных соединения соединяют одну и ту же пару маршрутизаторов, то каждое из них имеет свой адрес. Виртуальные сети схожи и с каналами точка-точка: например, система обладает полным контролем над очередями; более того, источником передаваемых по виртуальному соединению данных может быть только один из участников. Участник известен как "тот, кто использует виртуальное соединение", а стало быть, адреса интерфейсов попросту не нужны.
С точки зрения маршрутизации, сети на канальном уровне следует рассматривать с осторожностью. Проблемы с маршрутизацией возникают, например, когда сеть множественного доступа с виртуальными соединениями рассматривается как локальная сеть. Потеря магистрали - общего пути для нескольких виртуальных соединений - в сети frame relay может привести к тому, что протоколы маршрутизации (в особенности это касается OSPF) потеряют связь со всеми коллегами, хотя, тем не менее, они и будут иметь возможность обмениваться сообщениями. По этой причине такие сети лучше представлять как совокупность ненумерованных каналов точка-точка.
Имея представление о вышеперечисленных компонентах современного маршрутизатора, вы можете со знанием дела приобретать, развертывать, использовать и обслуживать вашу сеть.
Фред Бейкер - ведущий инженер по программному обеспечению в Cisco Systems, работающий в области телекоммуникаций с 1978 года. Он принимал участие в разработке стандартов ITU и IETF и в таких отраслевых консорциумах, как форумы Winsock-2 и ATM. В настоящее время Бейкер является председателем IETF. С ним можно связаться по адресу: fred@cisco.com.