В эпоху стремительных технологических перемен планирование нагрузки становится все более необходимым. Проактивный подход поможет вам подготовиться к будущему.
Теперь мы измеряем прогресс "годами Internet", причем один год Internet равен четверти календарного года. При головокружительных изменениях в технологии точное планирование нагрузки становится критически важным.
Несколько лет назад, если вы развертывали систему с относительно несовершенным проектом, ее можно было настроить, а дополнительные мощности добавить до перевода на систему всех пользователей. Сегодня времени на это нет. Чтобы потребители могли воспользоваться преимуществами новой технологии, например средствами соединения с удаленным офисом, мультимедийными приложениями или услугами Internet и Intranet, технологию необходимо разворачивать быстро. Для этого вы должны разработать стратегию планирования нагрузки, чтобы определить, где и как нужно расширить сетевую среду для размещения как новых приложений, так и новых пользователей.
ПРОАКТИВНОЕ ПЛАНИРОВАНИЕ НАГРУЗКИ
По существу, планирование нагрузки решает три вопроса: как данный комплекс изменений - например новые приложения и пользователи - скажется на загруженности сети; как эти изменения повлияют на производительность или время отклика; наконец, какое действие они окажут на эффективность имеющихся приложений?
Хорошая стратегия планирования нагрузки решает эти вопросы с двух позиций: с точки зрения сети и с точки зрения пользователей. Цель планирования нагрузки состоит в удовлетворении потребностей конечных пользователей. Поэтому свободное общение между администраторами сетей и конечными пользователями, а также между администраторами сетей и разработчиками приложений необходимо для успешного планирования. Без такого диалога получение необходимой информации для разработки хорошего плана невозможно. У конечных пользователей вы должны собрать информацию о требованиях к производительности приложений; от разработчиков вы должны узнать, какова структура приложений и каковы требования к данным.
Процесс планирования нагрузки представляет собой пятиступенчатую замкнутую систему с обратной связью.
Определение требований конечных пользователей к приложениям. Планирование нагрузки невозможно без понимания того, какие операции важны для конечных пользователей. Вы должны опросить пользователей, чтобы определить, какие приложения они используют и насколько часто. Это поможет вам смоделировать новые приложения. Например, если пользователь выполняет запрос к конкретной базе данных 50 раз за час, то новое приложение должно поддерживать скорость транзакций по меньшей мере 60 секунд на один запрос. Портативный анализатор сети служит хорошим инструментом для моделирования производительности новых приложений.
Оценка имеющейся сети. Мониторинг существующей сети позволяют осуществить многие инструменты. Помимо портативных анализаторов это платформы управления на базе SNMP, зонды удаленного мониторинга (RMON) и т.п. Если одни продукты следят за загруженностью сети, то другие контролируют и сообщают о загруженности сервера, в том числе ЦПУ, диска и памяти. Последние инструменты на рынке следят за производительностью конкретных приложений.
При использовании приложений для мониторинга период, в течение которого вы производите измерение производительности, имеет немаловажное значение. Например, отчет о загруженности сети с усреднением по 15-минутному периоду времени может пропустить короткие пики загруженности, а ведь они могут повлиять на мнение пользователей о времени отклика. Почти любая сеть выглядит прекрасно, если загруженность усредняется по достаточно долгому периоду выборки. Чтобы определить, как пиковый трафик влияет на производительность сети, вы должны использовать отчеты с усреднением загруженности по интервалу времени в несколько секунд. При анализе тенденций приложения для мониторинга должны выполняться в течение длительного периода времени.
Расчет требуемого времени отклика и предполагаемой загруженности сети. После определения потребностей конечных пользователей и требований к приложениям, вы можете определить предполагаемую загруженность сети новыми пользователями и приложениями. Эту цифру можно найти несколькими способами, в том числе при помощи формул и инструментов моделирования. Эти методы мы обсудим дальше.
Определение сетевой стратегии и структуры приложений. Основываясь на результатах моделирования, вы можете оценить различные сетевые топологии и технологии, чтобы определить, какая из них способна удовлетворить предполагаемым требованиям к сети и приложениям. Используя модели архитектуры приложений, можно определить структуру приложений для оптимизации их производительности. Например, ЦПУ клиентов или сервера будет задействовано? Данные будут находиться в филиале или корпоративном центре данных? Поскольку требования конечных пользователей к приложениям уже известны, вы можете оценить различные варианты в соответствии с конкретными вопросами производительности и нагрузки в вашей сетевой среде.
Обратная связь. После развертывания новых приложений и добавления пользователей, вы должны установить зонды для мониторинга сетевого трафика, предпочтительно по приложениям. Этот шаг замыкает кольцо. Иначе вы никогда не узнаете, насколько точным было планирование. Полученные отклики возвращают нас назад, к первому и второму шагу: оценке требований и базовому трафику. Теперь вы готовы к следующему комплексу перемен.
ТЕХНИЧЕСКИЕ ПОДХОДЫ
Если проактивное управление служит базисом для разработки успешной стратегии планирования нагрузки, то аналитические методы позволяют осуществить значимое определение емкости сети и производительности приложений. Эти методы позволяют рассчитать объем трафика, с которым инфраструктура в состоянии справиться, а также производительность, которую в итоге получат конечные пользователи.
Первый шаг в процессе моделирования - это выполнение нескольких простых расчетов для выяснения, есть ли у вас вообще проблемы с емкостью. Если простой расчет покажет, что, в худшем случае, новое приложение займет один процент от пропускной способности магистрали, то на этом ваша работа завершена! Однако, весьма вероятно, что вы выявите несколько потенциально проблемных областей.
Во-первых, вы должны спросить, что является узким местом: сеть, сервер или клиент? Затем можно провести более подробный анализ этих областей и точнее смоделировать инфраструктуру сети.
ВИНОВНИК - УЗКОЕ МЕСТО
Сеть не всегда бывает узким местом. Зачастую факторами, ограничивающими производительность, являются клиенты и серверы. Чтобы проиллюстрировать процесс определения потенциальных проблемных областей, давайте рассмотрим развертывание нового приложения для новых пользователей. Если приложение доступно по сети, измерения для определения заторов можно произвести при помощи портативных анализаторов протоколов и зондов RMON. Сведения о времени прибытия необходимо собрать для каждого пакета при транзакции.
Длительность транзакции может составлять несколько миллисекунд, секунд или даже минут. Время транзакции необходимо минимизировать, поскольку от этого зависит эффективность работы пользователей. Время отклика зависит от трех факторов: времени путешествия по сети, времени извлечения данных сервером и времени принятия и запроса клиентом данных. Первая задержка называется задержкой сети, а вторая и третья - задержкой на обдумывание. Задержки могут измеряться для всей транзакции в целом или для пакета в отдельности. Важно определить, какая часть задержки при выполнении транзакции вызвана сетью, сервером или клиентом.
Пусть клиент запрашивает информацию от сервера. Общую задержку для этой транзакции можно вычислить в четыре этапа. Во-первых, вы должны измерить время обдумывания клиентом. На уровне пакета время обдумывания - это задержка между временем получения клиентом кадра данных и временем запроса следующего кадра. Во-вторых, нужно измерить задержку в сети и на сервере. Это измерение также производится на клиенте; при этом вы измеряете задержку, связанную с временем обдумывания сервера, вместе с задержкой на передачу по сети. (Время задержки на передачу - это время, в течение которого пакет передается по сети от клиента к серверу.) В-третьих, необходимо измерить время задержки на сервере, т.е. интервал между временем получения запроса сервером и временем ответа на него. После выполнения этих измерений вы будете располагать следующей информацией:
Время обдумывания клиентом = t1
Задержка (в сети и на сервере) = tc
Время обдумывания сервером = t3
Далее задержка в сети вычисляется следующим образом:
Задержка в сети = t2 = tc - t3
Общая задержка при транзакции = t1+t2+t3
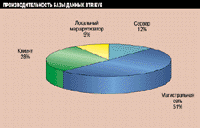
Представив результаты измерений в виде круговой диаграммы (например, при помощи Excel), вы немедленно получаете информацию об узких местах сети. Графическое изображение задержек при работе с базой данных Btrieve по магистрали FDDI дано на Рисунке 1. На этом узле сервер и клиенты находятся в разных сетях Token Ring, причем эти сети связаны с магистралью через маршрутизаторы. Результаты показывают интересную вещь: магистральная сеть оказывает наибольшее влияние на время отклика; локальный же маршрутизатор Novell и сервер баз данных Btrieve работают достаточно быстро.
 (1x1)
(1x1)
Рисунок 1.
Задержки, связанные с базой данных Btrieve, запросы к которой передаются
по магистрали FDDI.
Для определения производительности базового оборудования и сети измерения можно проводить в нерабочее время. Для выявления дополнительных узких мест измерения должны производиться в часы пик. Некоторые виды оборудования могут превосходно работать при небольших нагрузках, но не справляются с более интенсивными нагрузками.
В другом узле мы провели тест для приложения автоматизации офиса: Word for Windows на сервере NetWare. Открытие документа объемом 46 Кбайт по легко загруженному сегменту Ethernet заняло 3,1 сек. Как мы установили, 97% этого времени составляла задержка на обдумывание клиентом, и только 1,6% времени занимала передача пакетов по сегменту Ethernet.
ПРОБЛЕМЫ С КЛИЕНТОМ И СЕРВЕРОМ
Если результаты анализа узких мест показывают, что проблемы имеют место на клиенте или на сервере, то вы должны собрать о них более подробную информацию.
Клиенты и серверы имеют одни и те же потенциальные узкие места: память, тактовая частота ЦПУ и ввод/вывод (как в сеть, так и с диска). Отличие между ними в том, что производительность сервера необходимо увеличивать с ростом числа пользователей или трафика; клиент, очевидно, обеспечивает работу только одного пользователя. Несмотря на это, клиент может запросто оказаться узким местом, в результате чего усилия по обновлению сети или сервера могут оказаться тщетными.
Зондов, установленных для определения базовой производительности, достаточно для сбора дополнительной информации о потенциальных узких местах клиентов и серверов. Для мониторинга серверов существует множество коммерческих инструментов. Традиционные приложения типа iostat и mpstat предоставляют снимки загруженности серверов Unix. Windows NT Server имеет подобные встроенные средства сбора данных. Для централизованного мониторинга производительности компьютера используются программные агенты, например HP MeasureWare от Hewlett-Packard. В случае NetWare инструменты типа ServerTrak и TrendTrak компании Intrak предоставляют ценную информацию о загруженности ЦПУ, вводе/выводе NetWare и загруженности памяти. NetTune компании BMC Software также осуществляет мониторинг ввода/вывода с физического диска на серверах NetWare, благодаря чему ввод/вывод кэш-памяти можно отличить от запросов к диску.
Что касается клиента, хорошо уже то, что производительность не надо масштабировать, а тестирование производительности конфигураций различных рабочих станций достаточно просто провести методом проб и ошибок. Для мониторинга производительности клиентов Unix вы можете использовать те же самые инструменты, что и для сервера, iostat и mpstat. В случае Windows 95 вы можете использовать встроенный системный монитор.
ПРОБЛЕМЫ С СЕТЬЮ
Если производительность компьютеров зависит от объема памяти, тактовой частоты ЦПУ и скорости ввода/вывода, то производительность сети определяется двумя фундаментальными параметрами: полосой пропускания и временем задержки. Если установлено, что сеть является узким местом, то вы должны более точно определить эти два параметра. Понимание того, как они влияют на эффективность работы сети, позволит определить необходимую полосу пропускания и гарантировать - за счет правильной структуризации приложений, выбора протоколов и планирования сети, - что эта полоса пропускания будет доступна работающим в сети приложениям.
Полоса пропускания определяется физическим и канальным уровнем сетевой инфраструктуры - например, 10 Мбит/с для Ethernet и 1,536 Мбит/с для канала T-1. Время задержки подсчитать труднее, потому что оно зависит от нескольких факторов, скажем, от задержки при передаче данных, задержки при промежуточной буферизации на маршрутизаторах и коммутаторах и задержки при доступе в случае локальных сетей с разделяемой средой. Полоса пропускания и время задержки определяют в совокупности базовую пропускную способность коммуникационного канала.
Рисунок 2 демонстрирует комбинированный эффект полосы пропускания и времени задержки. В этом примере мы моделировали передачу по сети файла в виде блока данных размером W байт. Эта информация передается от клиента к серверу по сети с пропускной способностью BW. Каждый полученный блок подтверждается квитанцией от клиента серверу. Скорость передачи данных - это просто размер блока данных (W), поделенный на общее время, необходимое для посылки, приема и подтверждения пакета. Таким образом, формула имеет вид:
Скорость передачи = W : (W : BW + 2tN + tS + tC)
В этом уравнении tN - время задержки на передачу по сети, tS - время обдумывания сервером и tC - время обдумывания клиентом. W, деленный на BW, - это необходимое время для передачи блока данных по среде передачи. Подчеркнем важность задержки на передачу по сети - tN. Эта величина появляется в формуле дважды - один раз для передачи данных, и второй раз для передачи квитанции. Время обдумывания клиентом и сервером встречается только один раз.
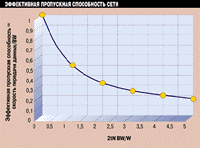
Теперь, когда мы определили скорость передачи данных, можно измерить приведенную пропускную способность для определения влияния сети на скорость передачи. Приведенная пропускная способность показывает, какая часть полосы пропускания реально доступна для передачи данных (в предположении, что задержка на сервере и клиенте отсутствует (#, #)):
{Скорость передачи : BW} = 1 : (1 + [2tNBW : W]}
График этого универсального уравнения приведен на Рисунка 2. С его помощью вы можете узнать, насколько реальная пропускная способность соответствует той, за которую вы платите. Предположим, например, что вы имеете канал T-1 (1,536 Мбит/с) с задержкой 5 мс при передаче в один конец. Предположим далее, что ваше конечное оборудование поддерживает транспортное окно размером 1,5 Кбайт. В этом случае 2tNBW : W = 2x0,015x1,536x106 : (1500x8) = 3,84 и скорость передачи данных равна 0,317 Мбит/с! В качестве другого примера рассмотрим сеть Token Ring, где клиенты и сервер разделены промежуточными узлами в виде моста и маршрутизатора с задержкой в один конец только 5 мс. Предположим, что размер транспортного окна равен 4 Кбайт. В этом случае мы находим, что реальная скорость передачи 2,7 Мбит/с, а не 16 Мбит/с.
 (1x1)
(1x1)
Рисунок 2.
Совокупный эффект полосы пропускания и времени задержки.
Таким образом, время задержки оказывает огромное влияние на производительность приложений в локальных и глобальных сетях, причем особенно чувствительны приложения, имеющие дело с крупными документами и графикой. Поэтому приложениям Intranet на базе HTTP необходимо уделить специальное внимание при моделировании производительности. Структуру приложений и топологию сети надо тщательно проанализировать на соответствие требованиям конечных пользователей, прежде чем принимать какие-либо решения.
В ОЧЕРЕДЬ ЗА УСЛУГАМИ
До сих пор мы не учитывали тот факт, что запросы пользователей могут одновременно касаться сервера, локальной и глобальной сети. Когда это происходит, образуется очередь запросов. Очередность как таковая - это еще одна важная концепция, и она должна быть рассмотрена в процессе планирования нагрузки.
Предположим, например, что сервер баз данных NetWare может ответить на запрос за 1 мс. Такой быстрый ответ будет получен, если данные уже кэшированы, - это типично для серверов NetWare. Однако сколько транзакций в секунду эта система поддерживает? Ответ: 1:0,001 = 1000 транзакций в секунду. Предположим, что транзакции происходят регулярно - одна в миллисекунду. В этом случае сервер будет поддерживать все транзакции, и время отклика для каждой будет равно 1 мс - таким образом, все хорошо. Однако если все запросы подаются одновременно, то для того пользователя, чей запрос окажется в очереди последним, время отклика составит одну секунду - т.е. в тысячу раз больше? При планировании нагрузки сервера или канала глобальной сети эти эффекты необходимо учитывать.
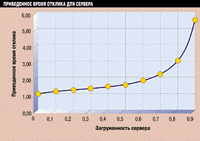
К счастью, быть специалистом по теории массового обслуживания, чтобы применить ее к планированию нагрузки, вовсе не обязательно. Общие результаты теории массового обслуживания изложены в ряде книг и статей, например в книге Пола Е. Рено "Introduction to Client/Server Systems" (New York, John Wiley, 1993). Мы применили один из выводов этой книги к ситуации, когда время отклика постоянно, а запросы пользователей прибывают через нерегулярные промежутки времени. График на Рисунке 3 изображает приведенное время отклика для сервера как функцию загруженности сервера. Этот график можно использовать для анализа целого ряда проблем, связанных с временем отклика сервера. Возьмем, например, снова сервер NetWare, чтобы посмотреть, как работает этот процесс. Базовое время отклика этого сервера при низкой нагрузке составляет 1 мс на транзакцию. Его нагрузка - 1000 запросов в секунду. Предположим, что сервер получает 600 запросов в секунду. В этом случае загруженность сервера составляет 60% или 0,6. Согласно графику, среднее время отклика в этом случае будет равно 1,75 мс - 75% роста по сравнению с тем случаем, когда сервер загружен мало.
 (1x1)
(1x1)
Рисунок 3.
Приведенное время отклика для сервера как функция загруженности сервера.
Всегда, когда скудные ресурсы используются несколькими пользователями одновременно, сеть будет испытывать снижение производительности ввиду образования очереди. Эти задержки очень сильно зависят от того, как пользовательские запросы распределены во времени.
МОДЕЛИРОВАНИЕ СРЕДЫ
После выявления проблем с нагрузкой и производительностью все готово для создания модели вашей среды. Более подробную картину того, с какими вопросами производительности сталкивается ваша сеть, можно получить с помощью целого ряда инструментов моделирования. Программные инструменты, например WinMind компании Network Analysis Center, используют аналитические методы моделирования для получения картины работы всей вашей глобальной сети. Этот инструментарий позволяет также рассчитать стоимость передачи в соответствии с различными тарифами IXC. ComNet III компании CACI Products применяет моделирование дискретных событий, благодаря чему возможно моделирование работы клиентов, серверов и сети. QASE компании AST обладает теми же функциями.
Инструменты моделирования дискретных событий позволяют более точно смоделировать загруженность сети и производительность приложений. Они выполняются автономно на платформе ПК или Unix и моделируют поведение реальной системы на уровне пакета. Конечно, для того чтобы эти инструменты были эффективны, вы должны ввести как можно более точную информацию о предполагаемом использовании приложений и требованиях к производительности, возможном поведении новых приложений и производительности компьютеров, маршрутизаторов и коммутаторов. Если собранные данные точны, то эти инструменты позволяют прогнозировать загруженность и производительность с точностью до 85-90%.
Такие инструменты, как ComNet III компании CACI, выдают результаты двух типов: во-первых, предполагаемую загруженность сети в процентах или байт/с; с помощью этой цифры вы можете получить представление о том, сколько свободного места осталось в сети. В конце концов, вы хотите создать сеть, которая оставляет возможности для роста. Во-вторых, эти инструменты моделирует производительность приложений. Если простой метод расчета, описанный выше, позволяет определить среднее время отклика или среднюю загруженность сети, то инструменты моделирования показывают, как производительность распределяется между приложениями и пользователями.
Чтобы получить лучшее представление о том, как эти инструменты работают, давайте возьмем пример из реальной жизни: компания решает определить производительность Microsoft Exchange по каналам глобальной сети, прежде чем его покупать и устанавливать. В этом примере интересующая нас транзакция - извлечение почты. Мы хотим определить, как приложение будет работать при заданном трафике в локальной и глобальной сетях компании. Пользователи расположены в филиале, имеющем локальную сеть Token Ring. Exchange Server находится на магистрали Token Ring в центральном вычислительном центре. Эти два узла связаны между собой каналом T-1. Мы предполагаем, что пользователи будут посылать десять сообщений в час и что 10% этих сообщений будут иметь одномегабайтные включения.
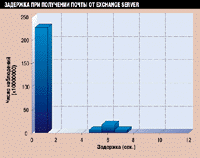
Результаты моделирования показали, что средняя задержка на извлечение почты составит 0,63 с, а максимальная задержка - 10,9 с. Полное распределение времени отклика приложения приведено на Рисунке 4. Полное распределение дает информацию не только о среднем времени отклика (или минимальном и максимальном времени отклика), но также о реальном времени отклика, с которым каждому пользователю придется иметь дело. Согласно результатам на Рисунке 4, задержка для большинства пользователей составит 0,6 секунд, но те, кому придется извлекать сообщения с включением объемом 1 Мбайт, столкнутся с задержкой приблизительно в шесть секунд. Изредка, когда несколько пользователей борются за полосу пропускания канала Т-1, задержка может составлять 10 с.
 (1x1)
(1x1)
Рисунок 4.
График демонстрирует модельную производительность Exchange для канала
Т-1. В данном примере оцениваемой транзакцией было извлечение почты. Для
получения этих результатов мы предполагали, что каждый пользователь будет
посылать десять сообщений в день и что 10% этих сообщений будут содержать
включения объемом 1 Мбайт.
ЗАВЕРНИТЕ, ПОЖАЛУЙСТА!
При еженедельном появлении новых приложений, модификаций и технологий потребность в проактивном планировании нагрузки становится еще более насущной не только для обеспечения ведения бизнеса, но и для его эффективного ведения. Без продуманного планирования нагрузки компании подвергаются риску снижения продуктивности критической для бизнеса операции, излишней платы за сетевое оборудование и услуги, или неэффективных трат на обновление уже работающей системы.
Помните, что ключом к успеху планирования нагрузки является понимание потребностей пользователей. В конце концов, они заказчики тех сетевых услуг и приложений, работу которых вы обеспечиваете.
Фредерик В. Шолл - президент Monarch Information Networks. Компания Monarch предоставляет услуги по планированию нагрузки и моделированию производительности важнейших для бизнеса приложений. С ним можно связаться по адресу: monarch@world.std.com.