Конференция «Высокопроизводительные вычисления на платформе Tesla от nVidia», проведенная 27 февраля на факультете вычислительной математики и кибернетики МГУ и посвященная научным приложениям процессоров Tesla, стала первым мероприятием подобного рода. На нее возлагались определенные надежды, ведь графические процессоры универсального назначения (General-Purpose Graphical Processing Unit, GPGPU) не требуют больших материальных затрат и поэтому привлекают к себе внимание академической и университетской общественности, не избалованной средствами. Сейчас более полусотни университетов только в США, не считая других стран, экспериментируют с продуктами nVidia. Увы, в России такой опыт отсутствует и, судя по реакции зала, информированность о GPGPU близка к нулю. В мире дело обстоит иначе, есть группы исследователей, собственными силами собирающие специализированные компьютеры; к примеру, в Бельгии для томографии создан настольный компьютер FASTRA на четырех графических картах. Уже в текущем квартале должен появиться процессор AMD FireStream 9270, поддерживающий 800 потоков; на двойной точности его производительность достигнет 240 GFLOPS. Совершенно очевидно: направление GPGPU динамично развивается.
Собравшимся была представлена рабочая станция Tesla Personal Supercomputer на процессоре Tesla C1060, созданная nVidia в сотрудничестве с другими компаниями. В отличие от своих игровых и медийных предшественников, процессор серии Tesla 10XX ориентирован на расчеты, а потому поддерживает арифметические операции с двойной точностью. Плату C1060, на которой он монтируется, можно установить в любой стандартный корпус; всего в один корпус можно поместить до четырех таких плат. Еще одна версия исполнения, C1070, представляет собой четыре платы, смонтированные в каркасе высотой 1U.
В приложениях для Tesla поддерживается язык программирования CUDA (Compute Unified Device Architecture), созданный в nVidia специально для GPGPU на основе языка Си. Он содержит в себе коды, адресованные как классическому процессору CPU, так и GPGPU. Процедура компиляции CUDA своеобразна. Она разделена на несколько этапов. На первом шаге код, относящийся к CPU, извлекается и передается стандартному компилятору. Код же, предназначенный для GPGPU, сначала преобразуется в промежуточный язык PTX, а затем транслируется в специфические команды GPU.
Теперь о том, что не было сказано о GPGPU, но что важно понимать, дабы не бросаться выражениями «персональный суперкомпьютер», «производительность выше, чем у кластеров» и тому подобными без достаточной аргументации. Первые исследования, связанные с использованием GPGPU для расчетов, начались в лаборатории графики Стэнфордского университета в ходе проектов Brook и BrookGPU. Написанная сотрудниками лаборатории замечательная книга GPU Gems («Сокровища GPU») выложена в Internet, и ее можно рекомендовать прочесть всем, кто намеревается использовать GPGPU. В ней сформулированы принципы потокового компьютера, построенного по схеме, принципиально отличающейся от схемы последовательного компьютера Джона фон Неймана. Потоковый компьютер настолько не похож на последовательный, что ни о каком сравнении и речи быть не может. Нельзя, в частности, использовать в качестве критерия сравнения производительность, выраженную в гигафлопах, как нельзя сравнивать по лошадиным силам двигатели гоночного автомобиля и трактора.
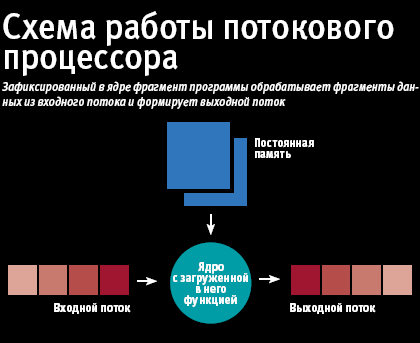
При работе по этой схеме не статические данные обрабатываются потоком команд, а поток данных проходит через фиксированную последовательность команд. Из постоянной памяти в ядро загружается некий код, который, находясь там, перерабатывает входной поток в выходной. Программирование таких процессоров сводится к двум операциям map и reduce, заимствованным из языков функционального программирования; map отображает обрабатывающие функции по ядрам, а reduce собирает результаты. Нечто подобное реализовано в современных параллельных СУБД. Можно с утверждать, что эта схема работает на крайне ограниченном спектре данных, которые можно отобразить на сотни ядер. Если эти условия выполняются, то действительно, как утверждают в nVidia, можно получить ускорение на несколько порядков. Есть классы приложений, где это работает, но гигафлопы, полученные на приложениях такого рода, не дают основания называть системы на базе GPGPU суперкомпьютерами.
Компания ATI, единственный реальный конкурент nVidia, куплен AMD, поэтому интересна реакция Intel на то, что делает nVidia. Казалась логичной симметричная сделка. Однако в Intel отвергают подобное предположение, характеризуют направление GPGPU как бесперспективное и видят будущее графических процессоров в собственной разработке Larrabee, программно совместимой с x86.