Computerworld, США
Размещение на одном кремниевом чипе двух и более процессорных ядер стало одной из важнейших вех на пути развития вычислительной техники за последние годы. Исследователи нашли способ продлить жизнь легендарному закону Мура, избежав при этом чрезмерной сложности организации производства, энергоснабжения и охлаждения микропроцессоров, работающих на частоте выше 4 ГГц
Многопроцессорные кристаллы (Chip MultiProcessor, CMP) позволяют значительно увеличить производительность приложений, которые были написаны с учетом особенностей их архитектуры.
Однако добиться от параллельной обработки ощутимых преимуществ непросто. Программисты должны вести себя уже по-другому, равно как и компиляторы, языки программирования и операционные системы. Авторам прикладного программного обеспечения, которые хотят в полной мере использовать потенциал архитектуры CMP, понадобятся новые навыки, а также иные технологии и инструментальные средства проектирования, кодирования и отладки. К счастью, производители как аппаратного, так и программного обеспечения уже заняты созданием инструментов и методов, упрощающих решение данной задачи.
«Появление многоядерных процессоров породило немалые сложности у разработчиков программного обеспечения и компиляторов, — отметил Кен Кеннеди, профессор информатики университета Райса, специализирующийся на написании программного обеспечения для параллельной обработки. — Посмотрите на историю развития микропроцессорной отрасли: в соответствии с законом Мура количество процессорных ядер удваивается через каждые два года. Боюсь, что нам со своей стороны не удастся поддерживать столь же высокие темпы развития».
Приложения для настольных компьютеров, которые традиционно разрабатывались для однопроцессорных систем, все чаще пишутся с учетом параллелизма, присущего архитектуре CMP. Серверные же приложения, которые на протяжении многих лет проектировались для многопроцессорных систем, должны обладать возможностью еще более гибкого и эффективного распределения нагрузки. Виртуализацию — еще одно важное направление современного компьютерного мира — также проще реализовать в рамках системы CMP.
Целый ряд ведущих ИТ-компаний прилагают серьезные усилия для адаптации своих продуктов к особенностям архитектуры CMP. Исследователи, разрабатывающие инструментальные средства CMP, нацеливаются на решение двух достаточно широких вопросов: как находить ошибки в коде, написанном для нескольких процессоров, и как упростить процедуру создания надежных программ.
«Многие из технологий, используемых нами при написании последовательно выполняющегося кода, в параллельных программах не работают так, как хотелось бы, или не функционируют вовсе, — отметил менеджер исследовательского подразделения Microsoft Research по языкам программирования и инструментальным средствам Джим Ларус. — В ходе тестирования вы проверяете приложение на самых разных наборах данных, но при запуске параллельных программ можно тысячу раз получить правильные результаты, а в 1001-й возникнет ошибочная ситуация».
Эта неприятная особенность обусловлена «состязательностью» параллельного выполнения кода. Ожидается, что результаты работы одного процесса поступят на вход другого — причем, как правило, так и происходит. Но вследствие возникновения непредвиденных ситуаций (например, прерываний операционной системы) порядок работы нарушается. Ошибки подобного рода обнаружить крайне сложно, потому что при повторных прогонах они не регистрируются.
Инструментальные средства, разрабатываемые группой Ларуса, помогают осуществлять управление тестированием. Программисту, к примеру, предоставляется возможность варьировать временные параметры двух потоков и контролировать ошибки состязательности. В конечном итоге эти инструменты планируется поставлять на коммерческой основе в составе пакета Visual Studio, но до этого, по словам Ларуса, еще далеко.
Сотрудники Microsoft Research предпринимают попытки создания модели, которая бы обеспечивала строго последовательную обработку (keep it strictly sequential, KISS). Модель KISS преобразует параллельную программу в последовательную, имитирующую работу параллельно выполняемого кода. Затем последовательную программу можно проанализировать и частично выполнить в отладочном режиме с помощью обычных инструментальных средств, от которых требуется лишь понимание семантики последовательного функционирования.

|
| По словам представителей Intel, к концу текущего года 85% серверных процессоров и 70% процессоров для ПК будут выпускаться с двумя ядрами. Согласно прогнозу, через пять лет в серверных микропроцессорах будет насчитываться уже 16 ядер, а в чипах для настольных машин — до 8 ядер. Но чем загрузить восемь процессорных ядер, работающих на частоте 3,6 ГГц? |
В Microsoft и ряде других компаний работают также над созданием новой программной модели, получившей название памяти программных транзакций (Software Transactional Memory, STM). Она позволяет корректно синхронизировать операции с памятью без блокировок — традиционного способа устранения ошибок, связанных с временными последовательностями, — и избежать тем самым клинчей. В модели STM обращение к памяти воспринимается как часть транзакции, и если в ходе выполнения другой операции возник конфликт, связанный с временной последовательностью, транзакция просто откатывается назад. Попытку выполнить транзакцию можно предпринять позже — примерно таким же образом работают сейчас системы управления базами данных.
«Идея заключается в том, что программист вместо описания процедуры синхронизации на очень низком уровне просто объявляет: ?Хочу, чтобы весь код между этой и этой точками программы выполнялся с последовательной организацией доступа к данным. А ну-ка, система, сделай это?», — пояснил Ларус.
Модель STM, являющаяся сегодня весьма популярной темой исследований, в перспективе, очевидно, будет реализована как на аппаратном, так и на программном уровне. И тогда разработчики для обеспечения корректной синхронизации в параллельно выполняемых программах должны будут использовать избирательную блокировку — на уровне отдельных строк или элементов, а не всей таблицы. Чем больше параллельных потоков, тем труднее это сделать.
Продукты Microsoft не требуют внесения серьезных изменений при переходе от систем с двумя процессорами (или процессорными ядрами) к четырем или восьми процессорам. Понадобится, скорее, всего лишь некоторая настройка производительности. «Однако при дальнейшем повышении масштабируемости возникает вопрос, где искать узкое место, — отметил Ларус. — И чем больше процессоров, тем тщательнее нужно планировать блокировки».
Немецкая компания MainConcept разрабатывает программное обеспечение для шифрования и дешифрации сигналов (в частности, видео высокого разрешения), и ее специалисты хорошо знакомы с подобной избирательной блокировкой на практике. Обработка видео требует большой вычислительной мощности. Фильмы с высоким разрешением должны обрабатываться в режиме реального времени, каждому кадру требуется до мегабайта памяти, а над каждым фрагментом кадра проводятся достаточно сложные математические преобразования.
Специалисты MainConcept настроили свое программное обеспечение на работу в системах с двумя процессорными ядрами так, чтобы ядра обрабатывали фрагменты кадра параллельно. По словам директора MainConcept Маркуса Менига, производительность после этого выросла в 1,8 раза. А при использовании двух двухъядерных процессоров быстродействие увеличится еще в 1,8 раза. Подобный почти линейный рост производительности близок к идеалу и намного превышает твердый хороший уровень с коэффициентом 1,5.
Программное обеспечение использует «огромные сегменты памяти», осуществляя поиск и выборку информации из этих областей. Если программное обеспечение грамотно спроектировано, большую часть работы можно выполнить с помощью кэш-памяти, расположенной непосредственно на процессоре. Тем самым обеспечивается ускорение обработки информации. Для адаптации своих программных продуктов к аппаратной архитектуре компания MainConcept использует инструментальные средства настройки производительности, поставляемые корпорацией Intel. Механизм Intel VTune Performance Analyzer помогает оптимизировать код, а компоненты Thread Profiler и Thread Checker обеспечивают сбалансированность работы множества потоков и выявление узких мест в многопоточном коде.
Мениг предупредил, что линейного роста производительности по мере увеличения числа процессорных ядер добиться не удастся. «Не стоит ожидать линейной зависимости для 8, 16 ядер и более, — подчеркнул он. — Чем быстрее система и больше ядер в ней присутствует, тем чаще именно организация доступа к памяти становится препятствием на пути к дальнейшему увеличению производительности».
«Разработчикам кода, пытающимся использовать преимущества нескольких процессоров или процессорных ядер, приходится решать три основных вопроса, — отметил директор по развитию подразделения разработки программного обеспечения Intel Джеймс Рейндерс. — Первый из них связан с масштабируемостью — как загрузить каждый из дополнительных процессоров? Трехкратное увеличение производительности на четырехпроцессорной системе — очень хороший результат. Все, что превышает этот показатель, — просто великолепно».
Второй вопрос касается «корректности» — как избежать проблем, обусловленных состязательностью, взаимными блокировками и другими особенностями многопроцессорных приложений? Программное обеспечение Intel Thread Checker позволяет выявлять потоки, которые обращаются к одним и тем же областям памяти без применения методов синхронизации а это «почти всегда указывает на ошибку».
Третий вопрос связан с проблемой «сложности программирования». Современные компиляторы способны распознавать в исходном коде фрагменты, допускающие организацию параллельной обработки, и активно используют эти возможности. Программисты могут помочь в этом компилятору, включив в свой код ряд соответствующих указаний.
Эти «указания» перечислены в спецификациях стандарта OpenMP, в которых описаны директивы компилятора, библиотечные процедуры и переменные среды, используемые для определения параллелизма в программах на языках Фортран, Cи и C++. В качестве альтернативы этим расширениям можно описывать многопоточность вручную, в этом случае мысли выражаются даже яснее. Таким образом, спецификации стандарта OpenMP могут оказаться весьма полезными.
Аналогичной точки зрения придерживается и Кеннеди: «Я считаю, что программисту следует писать программу в как можно более естественном стиле, а компилятор должен распознавать характеристики процессора, обеспечивая максимальную производительность».
Аналитик компании In-Stat Том Халфхилл отметил, что некоторые разработчики, столкнувшись с системами CMP, буквально «рвут на себе волосы». Переписывание программ с учетом многопоточной архитектуры требует очень больших трудозатрат. Кроме того, возникают новые ошибки и осложнения, а программное обеспечение увеличивается в объеме — не удивительно, что люди идут на это крайне неохотно.
В языках Фортран и C++ изначально не были заложены возможности параллельной обработки, в то время как в Java соответствующие средства присутствуют, поэтому появление систем CMP способствует дальнейшей популяризации Java.
Впрочем, следует признать, что поезд CMP уже набирает ход, нравится это разработчикам программного обеспечения или нет. По словам представителей Intel, к концу текущего года 85% серверных процессоров и 70% процессоров для ПК будут выпускаться с двумя ядрами. Согласно прогнозу Халфхилла, через пять лет в серверных микропроцессорах будет насчитываться уже 16 ядер, а в чипах для настольных машин — до 8 ядер. Кроме того, каждое ядро сможет одновременно обрабатывать по крайней мере четыре потока.
Сегодняшние опасения, связанные с оптимизацией программного обеспечения для архитектуры CMP, немного напоминают страхи двадцатилетней давности, когда разработчиков беспокоили недостаточные объемы доступной памяти и дискового пространства. Сейчас оба эти ресурса стоят настолько дешево и имеются в таком количестве, что большинство приложений разрабатываются исходя из предположения их неограниченной доступности.
«Через пять-десять лет то же самое произойдет и с процессорными ядрами, — считает Халфхилл. — Их станет так много, что операционная система будет выделять приложению столько ядер, сколько ему нужно, а вам больше не придется беспокоиться о том, что некоторые ядра простаивают или используются не на полную мощность».
Появление архитектуры CMP способствует дальнейшему развитию аппаратной виртуализации, благодаря которой на компьютере можно запускать сразу несколько операционных систем одновременно. Многопроцессорная архитектура обеспечивает более точное распределение ресурсов на машине. Появляется возможность повышения эффективности управления и распределения процессорных ресурсов. Одному приложению, к примеру, можно выделять два ядра и не более, а другое, обладающее более высоким приоритетом, будет использовать вычислительную мощность уже четырех ядер. «Отображая виртуализацию на отдельные ядра, вы можете получать более предсказуемые результаты», — подчеркнул Рейндерс.
Архитектура CMP обеспечивает увеличение производительности по сравнению с использованием нескольких независимых процессоров, поскольку внутрипроцессорные соединения и каналы, связывающие процессор с памятью, работают гораздо быстрее в случае реализации всего этого непосредственно на чипе. По мнению Кеннеди, такая ситуация должна привести к созданию гибридных систем, состоящих из компьютерных кластеров, работающих под управлением многоядерных процессоров.
«Оформятся два разных вида параллелизма: межпроцессорный параллелизм, построенный, возможно, на основе обмена сообщениями и совместного использования памяти, и параллелизм, реализованный в рамках одного чипа, — пояснил он. — Функции, требующие высокой пропускной способности каналов, связывающих процессоры, будут выполняться с применением архитектуры CMP, а те из них, которые не предъявляют высоких требований к производительности, можно распределить между процессорами кластера. Хорошей областью применения такой архитектуры являются средства обработки транзакций различных типов и системы управления базами данных».
Сегодня, пожалуй, все согласны с тем, что использование дополнительных процессоров, ядер и вычислительных мощностей в общем случае может оказаться весьма полезным при построении крупных корпоративных систем, а вот будущее архитектуры CMP на рынке настольных и портативных компьютеров, где даже и одноядерные процессоры большую часть времени простаивают, пока покрыто туманом. Хорошей областью применения параллелизма являются отдельные специализированные приложения (например, системы распознавания речи) и многопоточное игровое программное обеспечение.
Сегодня ПК с единственным одноядерным процессором может использовать преимущества многозадачности, поручая одному потоку, к примеру, вывод на дисплей, другому организацию длительных вычислений, а еще одному обеспечение связи с сервером. Но чем загрузить восемь процессорных ядер, работающих на частоте 3,6 ГГц?
Ларус заметил, что ему известно о затруднениях, которые испытывают разработчики, пытаясь предоставить отдельно взятому клиенту возможность использования преимуществ подобных систем.
«Откровенно говоря, с аналогичными трудностями сталкиваемся и мы, — подчеркнул он. — И это тема для весьма активных исследований».
Многогранность многоядерной обработки
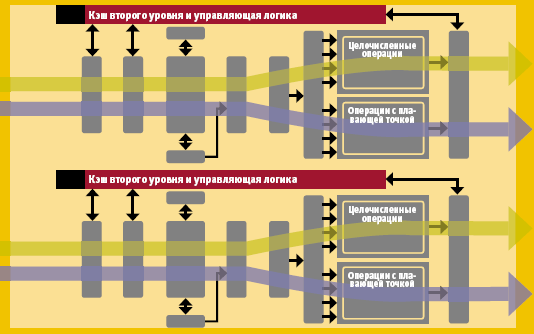
Процессор Intel Pentium Extreme Edition состоит из двух ядер, имеющих каждое собственную кэш-память и работающих на одинаковой частоте. Технология Intel Hyper-Threading превращает, в свою очередь, каждое из ядер в два логических процессора (в приведенном примере выполняющих соответственно целочисленные операции и вычисления с плавающей точкой). Возможность параллельной обработки четырех независимых потоков операций позволяет исполнять на процессоре одновременно по нескольку приложений, например, наряду с основной — фоновые задачи, такие как средства обеспечения информационной безопасности. Наконец, реализованная в процессоре технология поддержки виртуализации обеспечивает возможность одновременного исполнения нескольких операционных систем и/или приложений в независимых друг от друга разделах
Множественность и параллелизм
Hyperthreading: термин, введенный корпорацией Intel. Множество потоков одновременно выполняется на одном процессоре.
Векторная обработка (vector processing): применяется при организации научных или инженерных расчетов. В этом случае за одну операцию обрабатывается целая строка чисел (вектор).
Конвейер инструкций (instruction pipeline): процессор начинает выполнять следующую инструкцию до полного завершения обработки предыдущей. Скорость выполнения операций увеличивается за счет предварительного занесения следующей инструкции в кэш-память.
Многозадачность (multitasking): создает у пользователя впечатление параллельного выполнения операций. Выполнение кодовой последовательности на некоторое время приостанавливается, и процессор начинает обрабатывать другой фрагмент кода. В случае многопоточности (multithreading) приостанавливается выполнение одного потока, и тот же самый процессор приступает к обработке другого.
Многопроцессорный кристалл (chip multiprocessor): два или более процессора, размещенные на одном чипе, выполняют независимые приложения или одно приложение с параллельной обработкой. У каждого из процессоров может быть собственная кэш-память или общая разделяемая кэш-память.
Прогнозирование ветвления (branch prediction), выполнение с нарушением очередности (out-of-order execution) и упреждающее исполнение (speculative execution): Различные технологии, обеспечивающие одновременное выполнение отдельных частей программы, которые нельзя считать строго параллельными. Инструкции выполняются условно и при необходимости могут быть отменены.
Суперскалярная обработка (superscalar processing): способность системы выполнять две инструкции за один процессорный цикл.