Средства Business Intelligence в России пока не слишком востребованы
|
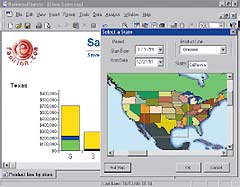
| Business Objects — это простое в использовании графическое средство, обеспечивающее оперативный доступ к различным источникам данных, составление запросов и построение профессионально оформленных отчетов |
В середине июня прошла научно-практическая конференция «Business Intelligence: все составляющие успеха». Она была посвящена обсуждению оптимальных путей построения BI-систем, применения бизнес-аналитики для оценки эффективности работы и повышения конкурентоспособности компании. Организаторами конференции выступили Hewlett-Packard, Sybase, «Терн» и «Крок».
Ольга Шматалюк, менеджер по маркетингу компании Market-Visio, обрисовала тенденции развития BI-систем. Она отметила, что пока внедрение BI часто осуществляется в отдельных департаментах и в основном носит характер создания «островков BI». Производители систем такого рода, как правило, концентрируются на разработке узкоспециализированных средств.
Представители «Терна» выступили с двумя докладами. Первый был посвящен проблеме трансформации данных в полезную информацию и серии продуктов DataStage — средств класса Extraction Transformation Loading от компании Ascential Software.
Второй доклад заключался в представлении системы Business Objects. ВО — это простое в использовании графическое средство, обеспечивающее оперативный доступ к различным источникам данных, составление запросов и построение профессионально оформленных отчетов, навигацию в многомерных представлениях выборок данных. То есть главными задачами ВО являются обеспечение удобного доступа к данным, создание отчетности различного вида и аналитическая обработка информации (OLAP-анализ).
Александр Козик, директор по проектам Sybase CIS, представил возможности СУБД Sybase Adaptive Server IQ для построения хранилища данных. Преимуществом Sybase Adaptive Server IQ по сравнению с традиционными СУБД является то, что данные хранятся не в строках, а в столбцах, что оптимально для OLAP. Кроме того, система позволяет избежать «взрывов данных» за счет сжатия данных при индексации и необязательной пре-агрегации данных.