Эта статья адресована прежде всего руководителям проектов разработки и интеграции сложных информационных систем. Опыт таких разработок в нашей стране пока не очень велик, и его анализ приводит к некоторым выводам и позволяет сформулировать формальные методы, которые могут пригодиться в других проектах. Особый интерес представляет то, как организовать работу коллективов аналитиков над большим проектом, существуют ли правила командной работы, какие наработки можно использовать в аналогичных проектах. Чрезвычайно важно, как решать эти проблемы на наиболее ответственном этапе моделирования предметной области

|
| Илья Юрьевич Тудер - директор департамента консалтинговых и программных проектов, компания ВСС. E-mail: ituder@bcc.ru Борис Аронович Позин - доктор техн. наук, директор департамента консалтинга и методологии создания ПО информационных систем, компания «АйТи». E-mail: bpozin@it.ru |
- построение функциональной модели "как есть" (as is);
- ее анализ и преобразование в модель "как надо" (to be);
- построение концептуальной модели данных (КМД) ПрО (или модели классов, в случае применения методов объектно-ориентированного подхода).
Известны и другие подходы, например такие, в которых на первом же этапе моделирования начинается построение КМД (JSD — Jackson Structured Development — [13]). Такой подход назывался «объектным» (или подходом «от данных»), в отличие от «процессного», еще в те времена, когда слово «объектный» не было принято для обозначения соответствующего способа программирования и, позже, моделирования. Приведенная выше классическая схема является весьма распространенной в настоящее время и агрегирует разные методы.
Для сложных областей - таких как, например, банковская, процесс моделирования ПрО (технологии работы банка) представляет собой параллельную работу команды, состоящей из большого числа аналитиков (10-20), направленную на получение единого результата. По мере освоения ПрО (понимания ее аналитиками) модель развивается от выявленного перечня документов, формируемых или используемых при выполнении бизнес-процессов, к совокупности формализованных диаграмм, описывающих бизнес-процессы, сущности предметной области и отношения между ними, или свойства предметной области.
Большая размерность ПрО и необходимость командного решения творческой, слабоформализованной задачи, несмотря на наличие на рынке методов и инструментов моделирования, ставит перед руководителем проекта ряд вопросов, связанных с необходимостью специфического планирования и организации параллельно-последовательного процесса моделирования, а затем и разработки системы, комплексирования результатов параллельной работы аналитиков, поддержания логической целостности проекта.
Практически каждый руководитель крупного проекта ищет ответы на вопросы:
- как ограничить трудоемкость моделирования и при этом достичь необходимого и достаточного для последующего проектирования уровня детализации коллективно построенной модели?
- как обеспечить логическую целостность (непротиворечивость) результатов коллективного моделирования, на основе которых будет разрабатываться система, и защитить свой проект от "эффекта Вавилонской башни"?
- как перейти от моделирования предметной области к итерационному процессу проектирования-реализации системы в условиях большой размерности, при этом за счет чего обеспечить возможность верификации результатов разработки на соответствие первичной модели?
- как понизить совокупную сложность разработки при большой размерности предметной области?
Для решения поставленных выше задач нужна промышленная технология разработки, которая учитывала бы коллективный характер работы, предусматривала применение существующих методологий и предполагала возможность адаптации к условиям конкретного проекта. К сожалению, существующие методы разработки не дают, на наш взгляд, полного и комплексного ответа на поставленные выше вопросы.
Конечно, противоречащие друг другу задачи: а) не утонуть в деталях; б) ограничить объем работ; в) уметь перерабатывать сведения команды аналитиков — решались давно. Дж. Мартин (см. [8], методика BSP и ее развитие) и Дж. Хаббард (см. [11], метод и инструмент DBANALYSER) из IBM, Ч. Баркер из Oracle делали значительные, но все же частичные попытки в этом направлении. В простых случаях проблемы удавалось решать «вручную», за счет интеллектуальных усилий старшего аналитика, интегрирующего сведения от остальных членов команды. Но сложные системы требовали развития методов и инструментов, поддерживающих эту работу. Так, набор методов и инструмент интеграции частных представлений нескольких аналитиков в целостную модель ПрО были разработаны с ориентацией на проекты больших комплексных САПР (см. [2]). Но всех проблем это не решало, так как не сокращало размерность модели. Со временем же острота ситуации только нарастала, так как системы усложнялись, а динамика их изменения росла. Это приводило еще к одному эффекту — постоянному возникновению неопределенности в больших (часто — на многие сотни сущностей ПрО) моделях, к невозможности включения всех деталей описания в модель. В результате в работах [3, 4] такое свойство, как неполнота ИС и ее моделей, вводилось как их постоянное, регулярное свойство.
В силу этого в [4] ставилась задача организации и обеспечения постепенного, компонентного проектирования баз данных. Для этого, в частности, предполагалось иметь «возможность фиксировать описания атрибутов, сущностей, связей, функций и т. д. с любой степенью неполноты, возможности производить описания на уровне недетализированных, предметно связанных совокупностей информационных структур («кластеров сущностей»)... В условиях компонентного проектирования организационная схема проектирования БД должна выглядеть как схема параллельного спирального проектирования компонентов БД и их комплексирования по необходимости».
Остается решить, как аналитикам и руководителям проектов поступать в этих условиях, какой метод работы будет сегодня давать значительный практический эффект. Ответу на эти вопросы и посвящена данная работа.
Чего не хватает в классических методологиях при коллективном моделировании сложных систем
Какую модель выбрать в качестве базы всегопроекта?
Выбор функциональной модели в качестве базовой имеет недостатки. Анализ проектов по разработке и развитию ИС показывает, что информационная составляющая ПрО по сравнению с функциональной (то есть с процессами) имеет большую стабильность [4] и меньшую размерность. Именно поэтому для обеспечения логической целостности проекта в качестве базовой модели принимается информационная модель. Но даже оставаясь в рамках процедурно-ориентированных методов, необходимо правильно формулировать цели функционального моделирования. На начальных этапах наиболее важно с помощью функциональной модели прежде всего выявить информационные объекты ПрО, в то время как степень детализации функциональных элементов является вопросом второстепенным. При этом важно, чтобы все аналитики, участвующие в процессе моделирования, детализировали модель до однородных по существу и сложности объектов. Это нужно для того, чтобы модели, полученные разными аналитиками, можно было сопоставлять и комплексировать. Таким образом, мы приходим к вопросу о глубине функционального моделирования.
Подход, при котором глубина функционального моделирования определяется требованиями к процессам, представленным в модели (например, SA/SD [15], методология Гейна/Сарсон [1], SADT [7], DATARUN [9]), на задачах большой размерности приводит к непомерной трудоемкости моделирования. В то же время в условиях итерационного моделирования сложной ПрО вовсе не вся информация необходима на каждом шаге, таким образом, ее можно получать последовательно, начиная с того шага, на котором без нее уже нельзя обойтись.
Необходимый уровень детализации функциональной модели целесообразно определить как требования к информационным объектам, представленным на потоках данных нижнего уровня иерархии. Эти требования должны быть едиными для всех аналитиков на каждой итерации моделирования. Например, в начальной модели в качестве такого требования наиболее разумно выбрать детализацию с подробностью до документа, являющегося частью делового документооборота банка. Степень отражения в модели структурной и алгоритмической сложности процессов при этом можно не рассматривать, поскольку это вопросы последующих итераций моделирования. Напомним, что на этой итерации главным вопросом является состав информационной составляющей ПрО. Такой подход позволит ограничить сложность модели и понизить трудоемкость начального моделирования, поскольку необходимые детали самых разных видов могут уточняться позже, в процессе параллельно-последовательной работы над элементами системы.
Концептуальная целостность и верифицируемость
Для обеспечения целостности (непротиворечивости) результатов параллельной работы аналитиков в ряде работ традиционно применяются глоссарии в совокупности с организационно-техническими процедурами их ведения. Ряд методов регламентирует необходимость наличия глоссариев для информационных элементов предметной области.
Подобный способ предлагался у упоминавшегося уже Дж. Хаббарда [11]. Применение глоссариев с автоматизированной поддержкой процедур разрешения семантических коллизий и интеграции локальных представлений было реализовано в [2]. Разработанные там программы опирались на формальные определения, информационную реализацию и конструктивное процедурное использование содержания и взаимосвязей так называемых «слоя локальных представлений» и «слоя интегрированной инфологической модели» в «объединенном словаре данных». В более позднем инструменте, в системе SILVERRUN, ведутся локальные словари отдельных аналитиков и словарь системы, в который локальные описания элементов перегружаются («процесс консолидации модели») с использованием специально назначенных общих «системных» имен, соответствующих разным, в общем случае локальным. Все же и в [2], и в системе SILVERRUN не ставилась в явном виде задача минимизации сущностей, включаемых в модель данных, не предлагались методы понижения размерности модели и трудоемкости проекта на стадии анализа.
В настоящее время из распространенных методов авторам, кроме RUP [14], не известен ни один метод, который предполагал бы одновременное ведение нескольких глоссариев на стадии анализа. При этом RUP декларирует такую возможность по построению, но не регламентирует содержание и взаимосвязь глоссариев (прежде всего в силу того, что они обеспечиваются в последующем инструментальными средствами). В RUP предусмотрен анализ результатов моделирования, однако конкретное его содержание не регламентируется.
Для дальнейшего изложения важно отметить, что практически всегда при моделировании ПрО оперируют двумя видами информационных объектов: неформализованными и формализованными. Неформализованные объекты, или документы предметной области (ДПО), представляют собой информационные объекты в виде, в котором ими оперирует ПрО без какой-либо формализации и нормализации атрибутного состава. В отличие от них формализованные объекты, или сущности предметной области (СПО), представляют собой информационные объекты (сущности), формализо-
ванно описывающие понятия ПрО. СПО являются основой для проектирования элементов системы.
Формализованные сущности выявляются на основе анализа и формализации исходных неформализованных документов, и эту связь между элементами очень важно сохранить в ходе моделирования и проектирования. Связи между элементами впоследствии не только позволят формализовать процедуры верификации, но и определить характеристики использования сущностей в бизнес-процессах через документы, присутствующие на потоках функциональной модели.
Для упорядочения процесса формирования раздельных описаний ДПО и СПО при коллективном моделировании предлагается использовать два взаимосвязанных по содержанию глоссария: соответственно глоссарий ДПО и глоссарий СПО. Независимо от применяемых методов проектирования системы (структурных, объектно-ориентированных) основой для проектирования объектов ИС будут являться сущности предметной области, содержащиеся в одном из глоссариев. Но для того чтобы осуществить переход от представления о структуре ПрО к ее формализованному описанию, необходимо предусмотреть процедуры поэтапной верификации модели на каждой итерации ее создания. Для верификации необходимы объект и эталон. Именно эти роли и выполняют соответственно глоссарий СПО и глоссарий ДПО.
Использование глоссариев позволяет не только обеспечить единую интерпретацию информационных объектов ПрО в процессе параллельно-последовательных моделирования и разработки, но и формализовать процедуры их верификации на основе первичной информации о предметной области, что очень существенно для проектов большой размерности, где количество таких объектов измеряется многими сотнями.
Совокупная сложность разработки
Вопрос уменьшения совокупной сложности и снижения трудоемкости в условиях большой размерности традиционно решается разбиением проекта на части. Для разбиения проекта на части без потерь в концептуальной целостности системы необходимо выявить интегрирующую основу, вокруг которой может вестись параллельно-последовательная разработка элементов. Как уже говорилось ранее, интегрирующая основа должна быть выявлена в первую очередь в информационной плоскости.
Классическая схема структурного анализа (например, методом Гейна/Сарсон) предполагает построение полной концептуальной модели данных (КМД), представляющей все сущности предметной области и их отношения. При большой размерности предметной области сложность построения полной КМД оказывается практически неприемлемой. Кроме того, трудоемкость этой работы нелинейно возрастает при увеличении количества элементов.
В условиях большого проекта основным способом борьбы со сложностью является переход к итерационной детализации с ограничением сложности модели на каждой итерации моделирования. Для реализуемости такого подхода необходимо, чтобы все информационные объекты, определенные на данной итерации для каждой части модели, позволяли проводить детализацию этой части модели максимально независимо от других ее частей, но в рамках модели, полученной на этой итерации. Для реализуемости такого подхода необходимо, чтобы аналитики могли определить перед каждой следующей итерацией, какие сущности связаны с другими частями ПрО (имеют общесистемное значение), а какие имеют локальное значение для детализируемой части ПрО и могут быть детализированы полностью в рамках работы над ней на более поздних стадиях, когда без этой детализации нельзя будет обойтись.
Для реализации такого подхода необходимы формализованные методы выявления общесистемных (имеющих значение для всей ПрО в целом) компонентов (сущностей, элементов). Однако существующие методологии не предоставляют таких методов на этапе анализа. В чем-то схожая работа с «объектами», или, точнее, с локальными предметными базами данных Дж. Мартина, включала отделение неактуальных объектов такого сорта, но только в ходе стратегического планирования развития системы и на уровне целых баз данных.
Таким образом, продолжают требовать своего решения задачи формализации и методической поддержки процесса коллективного моделирования предметной области в условиях большой размерности и высокой сложности проекта.
Предлагаемые элементы технологии моделирования
Для решения поставленных выше задач в [10] предложены следующие элементы технологии коллективного моделирования, дополняющие положения существующих методологий:
- критерий глубины детализации функциональной модели, направленный на выявление на первом этапе моделирования целостных информационных объектов предметной области типа ДПО; это позволяет обеспечить необходимый и достаточный уровень декомпозиции коллективно построенной модели для перехода на следующие этапы проекта, ограничив при этом трудоемкость моделирования;
- критерии верификации функциональной модели предметной области, основанные на взаимосвязанных глоссариях, которые содержат информационные объекты ПрО до и после их формализации;
- метод выявления общесистемных сущностей ПрО (ОСПО), который позволяет определить интегрирующую основу (ядро) проекта для всех последующих этапов его жизненного цикла, а также дает возможность отказаться от трудоемкой процедуры построения полной КМД (или модели классов) на этапе анализа.
Метод выявления общесистемных сущностей ПрО
Предложенный метод представляет собой формализованную процедуру выявления тех сущностей, которые наиболее часто используются в бизнес-процессах функциональной модели. Именно такие сущности должны стать кандидатами в объекты ядра информационной системы. Чем больше размерность проекта и количество участвующих в нем аналитиков, тем более важное значение приобретает формализация процедур выявления ядра, от которого зависит качество всего проекта.
Метод начинает работать после завершения функционального моделирования, в процессе которого формировался обсуждаемый ранее глоссарий документов. На завершающей стадии функционального моделирования проводится контроль результатов работы отдельных аналитиков на полноту и непротиворечивость, а также комплексирование (консолидация) единой модели, в том числе формирование глоссария сущностей. Таким образом, к началу применения метода функциональная модель и глоссарии полностью сформированы.
Сам метод может быть представлен следующим образом.
Исходной информацией для работы метода являются глоссарии, информация из которых представляется в матричной форме. Сам метод реализован посредством аппарата теории матриц. Результаты предварительного моделирования описываются в виде строк матриц, связывающих информационные объекты с бизнес-процессами. Путем последовательных матричных преобразований проводится «свертка», то есть выявление информационных объектов, претендующих на роль общесистемных сущностей. Оценка степени соответствия объекта статусу общесистемной сущности осуществляется по отношению к так называемому коэффициенту минимального использования (Kmin), определяющему минимальную долю от общего числа бизнес-процессов, в которых должна использоваться сущность для того, чтобы она была признана общесистемной; значения коэффициента лежат в пределах от 0 до 1. Например, те сущности, которые используются минимум в 80% процессов (то есть Kmin = 0,8), и будут общесистемными. Данный коэффициент характеризует свойства ПрО и позволяет адаптировать метод к условиям конкретного проекта.
Выявление в процессе моделирования и первоочередное проектирование общесистемных сущностей необходимо не только для обеспечения концептуальной целостности проекта. Оно осуществляется и для понижения взаимной зависимости подсистем (числа неспроектированных общих элементов) в процессе их параллельно-последовательной разработки. Это позволяет понизить совокупную сложность и трудоемкость всего проекта. При этом зависимость сложности и трудоемкости проекта от количества подсистем, вместо нелинейно-возрастающей (например, растущей как квадрат размерности модели), приближается к аддитивной, то есть растущей линейно. Механизм понижения совокупной сложности проиллюстрирован в [10].
Однако надо заметить, что предлагаемый подход наиболее эффективен для тех предметных областей, где существует относительно небольшая доля общесистемных информационных сущностей, используемых большинством бизнес-процессов.
О вычислении коэффициентов и об области, где метод эффективен
Мы располагаем интересными и важными, на наш взгляд, данными, полученными во время проведения статистических исследований характеристик банковской ПрО, выполненных на основе анализа ряда проектов по разработке автоматизированных банковских систем. Проекты обладали большой размерностью, количество сущностей ПрО в каждом из них составляло несколько сотен. Целью исследований было определение влияния характеристик использования сущностей в бизнес-процессах на совокупную сложность проекта.

|
| Рис. 1. Распределение сущностей предметной области по коэффициентам использования |
Введем понятие «коэффициент использования сущности» (Ки), равный отношению количества бизнес-процессов, с которыми связана данная сущность, к общему количеству бизнес-процессов в модели. Для трех проектов банковских систем построены графики распределения описанных в модели информационных сущностей по коэффициентам использования их в бизнес-процессах (рис. 1). Количество сущностей определяется площадью под кривой на выбранном интервале значений коэффициентов использования. Графики показывают, что большинство сущностей (около 80%) имеют малые коэффициенты использования (около 0,2). Это означает, что они важны только для отдельных бизнес-процессов. В то же время во всех трех проектах существует небольшая, но компактная группа сущностей (около 10%), имеющих большие значения коэффициентов использования (около 0,8). Иными словами, использование этих сущностей в 80% бизнес-процессов позволяет говорить о том, что они имеют общесистемный характер. Количество остальных сущностей достаточно мало и практически равномерно распределяется по интервалу средних значений коэффициентов использования (от 0,3 до 0,8). Характеристики использования сущностей, как видно из графиков, являются достаточно стабильными свойствами в предметной области.
Вернемся к ключевому вопросу: как применить метод выявления общесистемных сущностей, какое значение коэффициента Kmin использовать в конкретном проекте для того, чтобы понизить размерность информационной модели и совокупную сложность последующего процесса разработки подсистем.
Как уже говорилось ранее, совокупная сложность разработки подсистем проекта, состав которых соответствует бизнес-процессам функциональной модели, нелинейно возрастает при увеличении числа связей между ними. Для оценки связности бизнес-процессов в [5] предлагается классификация видов сцепления, которая в упрощенном варианте подходит для целей данного исследования. Будем считать, что два бизнес-процесса имеют сцепление, равное количеству общих информационных сущностей (то есть сущностей, используемых как в одном, так и в другом бизнес-процессе). Тогда коэффициент сцепления функциональной модели (Kc) (или системы, состоящей из подсистем) можно рассматривать как сумму сцеплений всех пар бизнес-процессов, деленную на количество таких пар (см. формулу, приведенную во врезке).
Очевидно, что на совокупную сложность и трудоемкость параллельно-последовательной разработки подсистем оказывают наибольшее влияние не все сущности, а только те, которые не были спроектированы (определены) и заданы в качестве исходной информации к началу работы по подсистемам. Таким образом, для снижения совокупной сложности проекта необходимо спланировать работу так, чтобы провести в первую очередь проектирование (определение) общесистемных объектов. Тем самым на последующих этапах уменьшится коэффициент сцепления по неопределенным объектам и снизится сложность проектирования новых компонентов (подсистем).
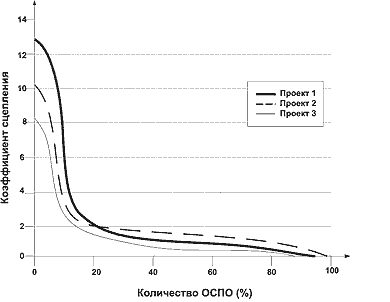
|
| Рис. 2. Зависимость сцепления функциональной модели по определенным сущностям от количества выявленных и определенных общесистемных сущностей |
На рис. 2 показаны графики зависимости коэффициента сцепления модели от количества (в процентах к общему числу) общесистемных сущностей. Графики показывают, что 10% сущностей с наибольшим коэффициентом использования в качестве общесистемных (ОСПО) определяют наиболее сложную часть модели, при построении которой приходится анализировать отношения каждой сущности в рамках наибольшего количества бизнес-процессов (в среднем порядка 10), что определяется ее коэффициентом использования. При исключении примерно 10% наиболее используемых сущностей сцепление понижается в три-четыре раза по отношению к исходному уровню. Для последующей группы сущностей (еще 10%) сцепление уменьшается еще примерно в два раза. Около 60% сущностей используются в малом количестве бизнес-процессов, и детализация каждой из них при моделировании может быть поручена одному аналитику.
Сопоставление участка резкого снижения сцепления на рис. 2 с графиком распределения сущностей по коэффициентам использования (рис. 1) позволяет выявить в предметной банковской области пороговое значение коэффициента использования для признания сущности общесистемной. Как следует из представленных графиков, в банковской ПрО целесообразно применять метод выявления ОСПО с пороговым значением (Kmin), равным 0,8, что позволяет на первом этапе анализа понизить размерность информационной модели в среднем до уровня 20% от общего числа сущностей, а также получить существенное (более чем в четыре раза) снижение сцепления функциональной модели и соответствующих ей подсистем проекта. На следующих итерациях, действуя таким же образом, можно понизить размерность анализируемой области примерно вдвое, а затем разбить задачу на относительно независимые части, которые могут разрабатываться отдельными аналитиками. Для других предметных областей значение данного коэффициента может отличаться.
Как видим, предметная банковская область обладает необходимыми свойствами для эффективного применения предлагаемых решений. При автоматизации банковской деятельности собственно банковская специфика составляет не более 30%. Остальные 70% представляют собой экономические, хозяйственные, управленческие и другие функции, характерные для многих предметных областей, что позволяет рассчитывать на эффективное применение предлагаемых технологических решений при разработке комплексных автоматизированных систем для предприятий различных сфер деятельности.
Заключение
Цель данной работы — показать руководителям проектов и аналитикам, что даже для сложных предметных областей большой размерности задача их коллективного моделирования, столь актуальная в настоящее время, является разрешимой. Нам представляется, что полученные результаты помогут руководителям проектов правильно организовать работы, обеспечивая возможности поэтапной проверки (верификации) модели, контроля целостности проекта, и одновременно, помогут правильно построить процедуры итерационного моделирования.
Хотелось бы подчеркнуть, что особенностью столь масштабных проектов является необходимость концентрации ресурса разработчиков на первоочередном проектировании общесистемных объектов, что позволяет затем более гибко учитывать требования заказчика по порядку реализации подсистем.
Авторы надеются, что предложенные количественные показатели помогут руководителям проектов с учетом конкретных характеристик предметных областей правильно сформулировать планы итераций как по моделированию, так и по проектированию информационных систем, минимизируя затраты главного ресурса - специалистов, а также помогая им выделять главное и вовремя переходить от этапа к этапу с учетом достигнутых результатов.
Стоит заметить, что предлагаемые методы позволят организовать соответствующие процессы как при структурной, так и при объектно-ориентированной технологии моделирования и создания программного обеспечения информационных систем, которой принципиально присуща итерационность.
Литература
- Гэйн К., Сарсон Т. Структурный системный анализ: средства и методы. Перев. с англ. М.: Эйтекс, 1993.
- Зиндер Е. З. Методы и инвариантный инструмент синтеза инфологической модели для интегрированной САПР. - В кн.: Численные методы и средства проектирования и испытания РЭА (тезисы докладов). Т. 2. - Таллин: ТПИ, 1987. С. 131-134.
- Зиндер Е. З., Белоконь А. К. Персонализация информационных технологий и инструментальной поддержки в проектировании //Tahkekeha elektroonika elementide projekteerimise ja kat- setamise numbrilised meetodid ja vahendid. Vabar. noup. ettek. teesid. K.II. - Tallinn: TTU, 1989.
- Зиндер Е. З. Проектирование баз данных: новые требования, новые подходы // СУБД. 1996. № 3.
- Калянов Г. Н. Теория и практика реорганизации бизнес-процессов. - М. СИНТЕГ, 2000.
- Липаев В. В., Позин Б. А., Штрик А. А. Технология сборочного программирования. М.: Радио и связь, 1992.
- Марка Д. А., МакГоуэн К. Методология структурного анализа и проектирования SADT// М.: МетаТехнология, 1993.
- Мартин Дж. Планирование развития автоматизированных систем. - М.: Финансы и статистика, 1984.
- Методология DATARUN. // Русский перевод АО "Аргуссофт", М., 1996.
- Тудер И. Ю. Коллективный анализ предметной области // Банковские технологии. 2001. № 5. С. 32-38.
- Хаббард Дж. Автоматизированное проектирование баз данных. - М.: "Мир", 1984.
- Штрик А. А., Осовецкий Л. Г., Мессих И. Г. Структурное проектирование надежных программ встроенных ЭВМ. - Л.: Машиностроение, 1989. 296 с.
- Jackson M. A. System Development. Englewood Cliffs, New Jersey: Prentice Hall International, 1983.
- Kruchten P. The Rational Unified Process: an introduction. Second edition // Addison Wesley Longman, inc., 2000.
- Yourdon E. Modern Structured Analysis // Englewood Cliffs, New Jersey: Yourdon Press, 1989.
СОВОКУПНАЯ СЛОЖНОСТЬ РАЗРАБОТКИ
Совокупная сложность разработки подсистем проекта нелинейно возрастает при увеличении числа связей между ними. Оценку связности бизнес-процессов можно выполнять, рассчитывая коэффициент информационного сцепления функциональной модели:
где:
Mpj - количество общих информационных сущностей j-й пары бизнес-процессов функциональной модели;
N - количество бизнес-процессов в функциональной модели;
N(N-1) / 2 - количество пар бизнес-процессов.