Продолжая держать в фокусе внимания эти вопросы, мы публикуем вторую часть статьи М.Р. Когаловского (первая часть напечатана в январском номере «Директора»).
Часть 2. Базы данных XML, семантика XML-документов, перспективы
В первой части статьи [1] были рассмотрены предпосылки создания платформы XML — совокупности новых технологий представления данных в среде Web и доступа к ним, а также поддерживающих их индустриальных стандартов. Рассмотрены назначение, взаимосвязи и состояние разработки этих стандартов. Обсуждались характер данных, которые могут быть представлены средствами языка XML, сравнительная сложность языков XML и HTML. Было показано, что XML-документы имеют многоуровневое представление, аналогично данным в базах данных.
Базы данных XML
Совокупности информационных ресурсов Web, основанных на платформе XML, приобретают ряд новых важных черт, которые не были присущи ресурсам HTML и которые сближают их с традиционными базами данных.
Действительно, вспомним прежде всего о многоуровневом представлении XML-данных — неотъемлемом свойстве баз данных. Однако, как уже отмечалось, в среде XML принцип многоуровневости воплощается недостаточно строго. В XML-документе сосуществуют аспекты физического и логического представления данных. И это не позволяет реализовать здесь важнейшую идею технологий баз данных — принцип независимости данных (см. первую часть статьи).
Далее, как и в системах баз данных, в стандартах платформы XML идет речь о модели данных для представления информационных ресурсов XML (хотя в этой модели пока отсутствуют, к сожалению, какие-либо операционные средства).
В среде XML появляется аналог схемы базы данных, роль которой играет DTD или описание XML-документов средствами стандарта XML Schema [2-4]. Здесь можно вести речь и об аналоге концептуальной схемы базы данных, роль которой играет RDF-спецификация (см. далее). Наконец, для Web, основанного на платформе XML, разрабатываются языки запросов, как и в системах баз данных.
Более того, в последнее время начали появляться программные продукты, которые квалифицируются разработчиками как СУБД для баз данных XML. Поскольку, как уже было указано, «модель данных XML» в понимании W3C не включает каких-либо операционных возможностей, создатели таких СУБД дополняют данную модель собственными нестандартными средствами для этой цели. Так, компания Software AG в своем «информационном сервере» Tamino, который во многих публикациях часто квалифицируется как СУБД, использует язык XML в качестве языка определения данных, а также язык запросов XQL [5] (предложенный, кстати, на роль стандарта языка запросов для платформы XML).
В контексте баз данных XML важно также еще раз обратить внимание на разработанный и развиваемый W3C стандарт Document Object Model (DOM) [6] объектной модели для XML-документов, который определяет функции интерфейса прикладного программирования для систем, поддерживающих информационные ресурсы XML. Стандарт DOM может быть использован в этой роли и в системах баз данных XML.
Явное задание метаданных для XML-ресурсов
Одной из важнейших целей создания платформы XML является привнесение в среду Web метаданных, описывающих свойства поддерживаемых в ней информационных ресурсов. Речь идет прежде всего об описании структуры XML-документов и их смыслового содержания (семантики). Необходимость решения этой задачи аргументируется стремлением к получению возможностей автоматической проверки правильности структуры XML-документов и снижения уровня информационного шума при отыскании нужных данных в Web с помощью различных поисковых машин. Имеется в виду, что при наличии явного описания структуры документов проверку их правильности может осуществлять браузер. Описание семантики документов может быть полезным подспорьем для новых или модернизированных существующих поисковых машин, а также для разнообразных нуждающихся в нем Web-приложений.
Однако чаще всего не учитывается еще одно важное назначение метаданных, описывающих информационные ресурсы Web. Метаданные необходимы для создания принципиально новых высокоуровневых приложений Web, в частности основанных на интеграции информационных технологий и обеспечивающих интеграцию неоднородных информационных ресурсов, о чем говорилось в первой части статьи. рисунок иллюстрирует упрощенную архитектуру системы, в которой метаданные используются для обеспечения интеграции неоднородных информационных ресурсов — ресурсов XML и баз данных SQL.
Нужно заметить, что развитие этого последнего направления на платформе XML стимулируется интенсивно проводимыми во многих странах мира исследованиями по созданию информационных систем нового класса, функционирующих в среде Web и называемых электронными библиотеками [7].
Как же решается задача определения метаданных в XML?
Прежде всего, непосредственно в языке XML предусматривается поддержка метаданных, описывающих структуру XML-документов. Этой цели служат определения типов документов (Document Type Definition, DTD). DTD представляется в синтаксисе языка XML и описывает структуру документов данного типа в терминах их элементов. Это описание может быть встроено в XML-документы или оно хранится где-либо в Web, и в документе дается на него ссылка. Такие внешние описания для различных областей приложений могут быть стандартизованы в рамках сообществ пользователей и разработчиков XML-документов.
Для более детального описания структуры XML-документов могут использоваться средства стандарта XML Schema. По сравнению с DTD этот стандарт предоставляет для описания XML-документов дополнительные возможности, в частности более развитую систему типов значений атрибутов элементов.
Рассмотрим теперь вопрос об описании семантики XML-документов.
Описание семантики XML-документов
Семантика XML-документа может быть определена в среде приложений XML явным или неявным образом (по умолчанию). Явное определение может иметь различную степень формализованности. Кратко рассмотрим стандартизованные средства, созданные для этих целей, и возможности их использования.
Пространства имен XML
Простейшая возможность задания семантики — использование пространства имен. В отличие от языка HTML, обеспечивающего форматную разметку текста, которая определяет его представление на экране, XML служит для структурной разметки.
Разметка в XML позволяет выделять в тексте содержательные структурные единицы, называемые элементами XML-документа. Для выделения каждого типа элементов используется свой тег, указывающий имя типа элемента. Поэтому с каждым таким тегом можно ассоциировать семантику соответствующих элементов XML-документа (адрес организации, номер телефона и т. д.).
Если некоторое сообщество разработчиков и пользователей XML-документов договорится о единой интерпретации имен, принадлежащих некоторому набору, то этот унифицированный набор, возможно, с каким-либо описанием их смысла (например, в виде обычного текста на естественном языке или представленный каким-либо иным образом), может использоваться как пространство имен. Адрес документа, представляющего в Web этот набор имен, будет рассматриваться как уникальный идентификатор пространства имен, и на него можно ссылаться в XML-документе, где используются принадлежащие этому пространству имена. И тем самым им придается некоторый смысл.
Заметим, что ресурс Web, адрес которого символизирует некоторое пространство имен, может не содержать никакого явного описания смысла принадлежащих ему имен и даже просто не существовать. В таком случае мы имеем дело с определением семантики имен данного пространства по умолчанию.
В последнее время начали создаваться сервисы регистрации и поддержки пространств имен в интересах различных сообществ разработчиков и пользователей. Зарегистрированное пространство имен является своего рода стандартом для сообществ клиентов сервиса регистрации.
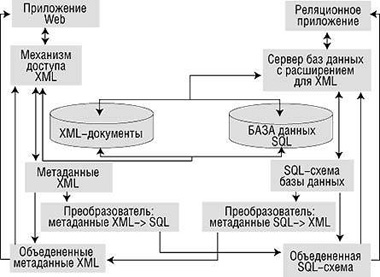 |
| Рис. 1. Упрощенная архитектура системы, обеспечивающей интеграцию информационных ресурсов XML и SQL |
Дублинское ядро
Одним из примеров достижения консенсуса о составе пространства имен является набор элементов метаданных для описания семантики представленных в Web документов, названный Дублинским ядром (Dublin Core, DC).
Первоначальная версия этого набора, состоящая из 13 элементов, была принята в 1995 году в г. Дублине (США) на симпозиуме, организованном Online Computer Library Center (OCLC) и National Center for Supercomputing Applications (NCSA).
Для развития и поддержки DC была учреждена специальная организация — Dublin Core Metadata Initiative (DCMI). Текущая версия спецификаций Дублинского ядра — DC 1.1 [8] — была принята в июле 1999 года. Она включает уже 15 элементов (см. таблицу).
В настоящее время активно обсуждается содержание следующей версии Дублинского ядра — DC 2.0. При этом речь идет как о составе элементов метаданных, так и об ассоциируемых с ними факультативных квалификаторах. Квалификаторы могут использоваться для уточнения смысла и способа интерпретации значений элементов метаданных в рамках какой-либо конкретной сферы применения. Предполагается, что если используемое программное средство работы с XML-документами встречает какой-либо квалификатор, смысл которого ему неизвестен, то этот квалификатор будет игнорироваться.
Заметим, что DCMI взаимодействует с Internet Engineering Task Force (IETF) и National Information Standard Organization (NISO) с целью придания DC статуса американского национального стандарта. В настоящее время разработка этого стандарта, названного ANSI/NISO Z39.85 [9], завершается.
Дублинское ядро с принятой в нем семантикой элементов метаданных может использоваться в рамках платформы XML различными способами. Например, можно применять DC в качестве пространства имен для некоторого типа XML-документов или в RDF-спецификации, о чем речь пойдет ниже.
RDF-спецификации
Стандартизованный путь явного описания семантики XML-документов основан на использовании средств, предложенных в уже упоминавшемся в первой части статьи стандарте Resource Definition Framework (RDF). Такое описание, называемое RDF-спецификацией, аналогично по своим возможностям концептуальной схеме в системах баз данных. По сравнению с рассмотренными выше средствами оно представляет собой более высокий уровень семантического описания информационных ресурсов, приблизительно эквивалентный ER-модели.
В RDF-спецификации объявляется некоторое множество ресурсов, с каждым из которых ассоциируются пары «свойство — значение». Значения свойств задаются литерально либо ссылками на другие ресурсы, которые представляются в свою очередь их свойствами. Таким образом, свойства могут определять и связи между ресурсами. Следует отметить, что семантика свойства и его значение — это не одно и то же. Например, «Publisher — лицо, организация или служба, обеспечивающая доступ к ресурсу» — это в данном случае пара «свойство—семантика», а «Publisher — «Открытые системы»— это пара «свойство—значение».
Информационные ресурсы в RDF — это ресурсы Web, идентифицируемые уникальным образом с помощью их URI (Uniform Resource Identifier, обобщение концепции URL в WWW). Они могут также представлять собой коллекции других информационных ресурсов или литералов, называемые контейнерами. Допускаются контейнеры типа мультимножества, последовательности и альтернативы.
Для того чтобы RDF-спецификация семантики информационных ресурсов была полной, необходимо ассоциировать с нею описание семантики используемых в этой спецификации свойств, которое в терминологии стандарта RDF называется схемой. Никаких ограничений на способ представления схемы не налагается. Достаточно лишь представить ее как некоторый ресурс в WWW и использовать URI этого ресурса для ссылки на нее в RDF-спецификации. Таким образом, здесь мы имеем еще одну «открытую точку» (наряду с указанной в первой части статьи), позволяющую определять наборы свойств различным образом — от определения их как пространств имен и вплоть до описания на каком-либо формальном языке высокого уровня типа языков представления знаний.
Характер представления RDF- схемы, глубина описания семантики свойств в ней и степень ее формализованности должны соответствовать потребностям приложений XML, оперирующих конкретной категорией информационных ресурсов, которые описываются данной RDF-спецификацией и этой схемой.
Один из способов задания схемы предлагается во второй части стандарта RDF, которая так и называется — Schema Specification [10]. Процесс принятия ее в качестве стандарта W3C находится в настоящее время в завершающей стадии. Schema Specification предоставляет средства не только для моделирования и описания семантики свойств информационных ресурсов, но и для спецификации ограничений целостности.
Спецификации RDF Schema Specification основаны на объектной модели. В этой модели используются концепции классов, свойств и ограничений, ассоциируемых с классами и свойствами, поддерживается иерархическое отношение «класс—подкласс».
Метаданные, представленные средствами RDF, могут использоваться для более эффективного поиска ресурсов поисковыми машинами Web, в электронных библиотеках, в описаниях коллекций страниц Web, составляющих некоторый виртуальный документ, для представления содержания информационных ресурсов в конкретных предметных областях, а также для поддержки различных Web-приложений, нуждающихся в семантической информации о ресурсах.
Как уже отмечалось, в задачу RDF не входит стандартизация каких-либо наборов семантических свойств, и они могут быть различными в разных случаях. Для некоторых приложений уже существуют такого рода стандарты, например, для описания семантики электронных текстовых документов используется рассмотренное выше Дублинское ядро. В стандарте RDF показано, каким образом Дублинское ядро может быть выражено средствами Schema Specification.
Перспективы XML
Завершая краткий анализ функциональных возможностей новой технологической платформы Web, базирующейся на языке XML, следует высказать нашу точку зрения на перспективы ее использования.
По нашему мнению, XML — отнюдь не модное направление, а естественный результат развития Web-технологий, следствие стремления к более эффективному использованию уникальных возможностей открытой глобальной информационной среды, которую они поддерживают. Не думаю, что создание платформы XML — это новая эпоха в развитии Всемирной паутины (скорее, началом новой эпохи стало создание самой паутины), но убежден, что это — начало нового, более наукоемкого и технологически более совершенного этапа в ее истории.
Уже сегодня XML, несомненно, стал стандартом де-факто. Все ведущие поставщики программного обеспечения не только Web, но и систем баз данных, включают в свои программные продукты поддержку языка XML или даже создают специализированные системы, такие как упоминавшийся уже сервер Tamino компании Software AG. Компания Microsoft включила поддержку XML в новую версию своего Web-браузера Internet Explorer 5.0. Появились экспериментальные XML-сайты, например XML-зеркало сайта журнала ACM SIGMOD Record на Web-сервере Римского университета (http://www.dia.uniroma3.it/Araneus/Sigmod/).
Большую работу по продвижению стандартов платформы XML в практику ведет крупный Международный консорциум OASIS (http://www.oasis-open.org/), в составе которого более 140 компаний. Эта деятельность является основной задачей консорциума. OASIS разрабатывает, координирует разработки и распространяет информацию о методологиях применения, технологиях и реализациях этих стандартов. В его задачу входит также создание приложений для «вертикальной» индустрии (например, разработки DTD, схем XML и пространств имен XML), спецификаций интероперабельности (в частности, создание спецификаций профилей, включающих стандарты рассматриваемой категории), тестов на соответствие рассматриваемым стандартам.
О большом интересе к языку XML свидетельствуют дни XML в Европе [11], проведенные по инициативе OASIS при поддержке W3C, OMG и других организаций в октябре 2000 года в Брюсселе, Осло, Стокгольме, Копенгагене, Амстердаме, Мюнхене, Цюрихе, Милане.
Распространению стандартов XML-платформы существенным образом способствует политика W3C, направленная на обеспечение доступности их спецификаций, создание ряда свободно распространяемых синтаксических анализаторов для языка, то большое внимание, которые создатели стандартов XML уделяют обеспечению преемственности для существующей HTML-платформы и накопленных на ее основе ресурсов.
Хотя язык XML и базирующиеся на нем стандарты получают все более широкое распространение, имеются вместе с тем факторы, которые сдерживают массовое распространение XML в среде Web.
Во-первых, существует связанная с экономическими и иными причинами естественная инерционность столь масштабной среды, какой является сегодняшний Web. Эта инерция может преодолеваться только постепенно.
Во-вторых, пока еще не завершена работа над двумя важнейшими стандартами платформы XML, которые позволяют строить из отдельных XML-документов и их компонентов гипермедийную среду. Речь идет о стандартах XPointer и XLink. Мы уже отмечали выше, что в языке XML нет средств для определения гиперссылок. Эту задачу решают указанные стандарты. Предусматриваемые в них возможности существенно более богаты, чем у имеющихся в HTML средств гиперссылок. Первоначальная версия XLink была слишком усложнена по известному закону «второй системы». Поэтому работа над этим стандартом сводилась к постепенному исключению из него слишком сложных элементов. В июле 2000 года проекты обоих указанных стандартов уже получили в W3C статус Candidate Recomendation, и можно ожидать в ближайшее время их одобрения.
В заключение хотелось бы затронуть еще одну тему. Технологии XML начинают распространяться и в нашей стране. В этой связи приобретает важное значение русскоязычная терминология в этой области, которая, конечно же, еще только начинает формироваться. Автор попытался внести свой вклад в это важное дело. На сайте [12] представлена текущая версия подготовленного нами русскоязычного глоссария стандартов платформы XML, работа над которым будет продолжена.
Литература
- Когаловский М. Р. XML: возможности и перспективы. Часть 1. Платформа XML и составляющие ее стандарты // Директору информационной службы. Приложение к Computerworld Россия. — М.: Открытые системы, январь 2001.
- XML Schema Part 0: Primer. W3C Candidate Recommendation. 24 October 2000. http://www.w3.org/TR/2000/CR-xmlschema-0-20001024.
- XML Schema Part 1: Structures. W3C Candidate Recommendation. 24 October 2000. http://www.w3.org/TR/2000/CR-xmlschema-1-20001024.
- XML Schema Part 2: Datatypes. W3C Candidate Recommendation. 24 October 2000. http://www.w3.org/TR/2000/CR-xmlschema-2-20001024.
- Robie J., Lapp J., Schash D. XML Query Language (XQL). The W3C Query Languages Workshop. December 3-4, 1998. Boston, Massachusets. http://www.w3.org/TendS/QL/QL98/pp/xql.html.
- Document Object Model (DOM) Level 1 Specification. Version 1.0. W3C Recommendation. 1 October 1998. REC-DOM-Level-1-19981001. http://www.w3.org/TR/1998/REC-DOM-Level-1-19981001.
- Когаловский М. Р., Новиков Б.А. Электронные библиотеки — новый класс информационных систем. Российская Академия наук. — М.: Наука, МАИК «Наука/Интерпериодика», Программирование, № 3, 2000. С. 3-8.
- Dublin Core Metadata Element Set Reference Description, Version 1.1, 1999-07-02. http://purl.org/dc/documents/rec-dces-19990702.htm.
- ANSI/NISO Z39.85-2000x. The Dublin Core Metadata Element Set. Draft Standard. Modified September 30, 2000. National Information Standards Organization, 2000.
- Resource Description Framework (RDF). Schema Specification 1.0. W3C Candidate Recommendation 27 March 2000. http://www.w3.org/TR/2000/CR-rdf-schema-20000327.
- XML Days Europe. Building Next Generation Internet Applications. http://www.llt.de/xml/.
- Когаловский М. Р. Глоссарий по XML-технологиям. http://www.iis.ru/weblib/docs/ xml/xml-gloss.html.ru.
Михаил Рувимович Когаловский — зав. лабораторией систем баз данных Института проблем рынка РАН, ученый секретарь Московской секции ACM SIGMOD. Ему можно написать по адресу: kogalov@cemi.rssi.ru
Глоссарий
Платформа — целенаправленно разработанная для решения некоторых задач совокупность технологий и поддерживающих их стандартов.
Метаданные — свойства данных, определяющие их структуру, допустимые значения и способы их представления, взаимосвязи с другими данными, размещение и другие характеристики данных, которые помогают правильно их интерпретировать и использовать. Иначе говоря, это данные о данных.
Семантика XML-документа — смысловое содержание документа.
Информационный ресурс — используемые в приложениях данные, которые представлены в базах данных, базах знаний, на Web-сайтах, в отдельных файлах различной природы или в процедурной форме с помощью продуцирующих их программных средств.
Операционные средства модели данных — совокупность операторов языка манипулирования данными этой модели данных.
| Номер элемента | Название элемента | Смысл элемента |
| 1 | Title | Название ресурса |
| 2 | Creator | Лицо, организация или служба, ответственные за подготовку содержания ресурса |
| 3 | Subject | Тема, обсуждаемая в содержании ресурса |
| 4 | Description | Описание содержания ресурса в свободной форме |
| 5 | Publisher | Лицо, организация или служба, обеспечивающие доступ к ресурсу |
| 6 | Contributor | Другие участники подготовки содержания ресурса |
| 7 | Date | Дата создания ресурса или предоставления его для доступа |
| 8 | Type | Жанр, категория или другие характеристики природы ресурса |
| 9 | Format | Характер представления ресурса |
| 10 | Identifier | Точная ссылка на ресурс |
| 11 | Source | Ссылка на источник, из которого продуцирован данный ресурс |
| 12 | Language | Язык представления ресурса |
| 13 | Relation | Ссылка на ресурс, связанный с данным |
| 14 | Coverage | Область пространства, времени и т. д., к которой относится содержание ресурса |
| 15 | Rigths | Права интеллектуальной собственности на ресурс и т. п. |